
Bitcoinkursvorhersage mit AWS – Teil 1
Wir hatten bereits im Rahmen eines vorangegangenen Blogartikels über unser internes Forschungsprojekt SAPPhiRE (Social mediA Price PREdiction) berichtet. Hierbei wollten wir auf Basis von Twitter-Daten eine Prognose auf den Bitcoin-Kurs berechnen und, naja, steinreich werden…
Ein zweites Ziel im Rahmen dieses Projekts war die Entwicklung eines technischen Prototyps, der die komplexen Aspekte eines typischen Big Data Projekts (Datenintegration, Datenanalyse und Datenvisualisierung) umsetzt. Hierzu wurde in einer ersten Leistungsstufe eine entsprechende Umgebung komplett selbst aufgebaut und On-Premise betrieben.
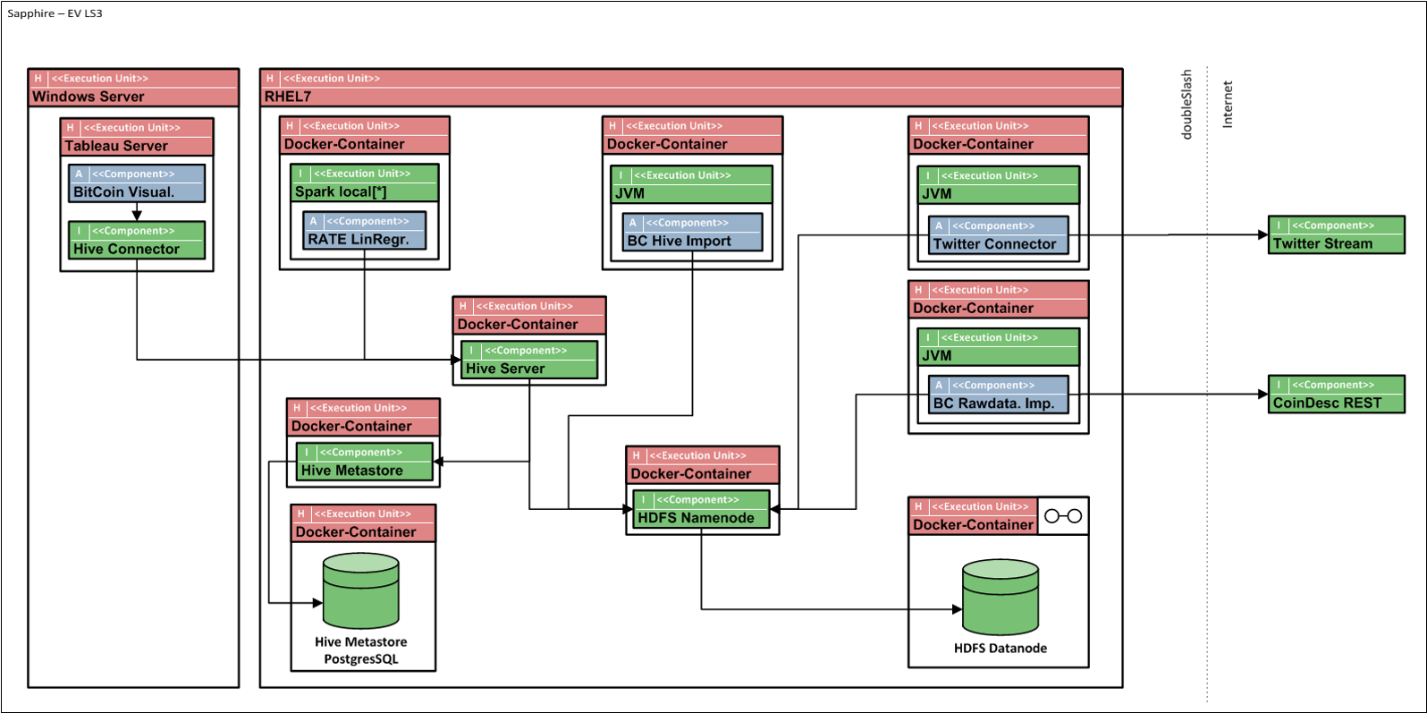
Beim Aufbau und Betrieb dieser Plattform mussten wir eine Vielzahl an Herausforderungen meistern, angefangen vom Monitoring der Anwendung, über Backupstrategien bis hin zur Sicherstellung einer Skalierbarkeit. Hierzu wurde eine Vielzahl an Technologien eingesetzt: Spark, Hive, PostgreSQL, Docker, HDFS, REST, Java und Tableau – um nur ein paar zu nennen. Und wie man sich denken kann, ist das Zusammenspiel dieser verschiedenen Technologien durchaus komplex und auch aufwendig, unter anderem weil man eine Vielzahl von Experten benötigt, die sich regelmäßig miteinander abstimmen und synchronisieren.
Für uns war das der Anlass, unseren fachlichen Use Case mit einem neuen Technologiestack und auf Basis von Cloud Computing Technologien zu erproben.
Die Ergebnisse dieses Projekts wollen wir im Rahmen einer zweiteiligen Blogserie kurz vorstellen. Im Rahmen dieses ersten Beitrags stellen wir die technische Umsetzung vor. In einem zweiten Teil beschreiben wir die implementierte Business Logik und gehen auf die wesentlichen Lessons Learned ein, die wir im Rahmen des Projekts für uns mitgenommen haben.
Technische Umsetzung
Für die technische Umsetzung wurde ein Platform-as-a-Service (PaaS) Ansatz auf Basis von AWS Technologien genutzt, d.h. sämtliche Hardware wurde von der Cloud zur Verfügung gestellt. Lediglich die Software, d.h. die fachliche Logik, musste selbst implementiert werden.
Die Architektur lässt sich dabei in folgende Abschnitte aufteilen:
Datensammlung
Auf Abbildung 3 ist dargestellt, wie die Komponenten für die Datensammlung miteinander arbeiten. Für die Sammlung der Twitter- und Bitcoin Daten wurde die Twitter API bzw. Coindesk API verwendet. Die Twitter API stellt Tweets mithilfe von Streaming in Echtzeit bereit, während die Coindesk API eine REST API darstellt und somit durch das Stellen von HTTP Requests den aktuellen Kurswert zurückgibt. Beide APIs werden jeweils durch ein Python-Skript angesprochen, welche dauerhaft im Hintergrund laufen und die dabei abgerufenen Daten speichern. Für die Ausführung dieser Skripte auf AWS wurde Elastic Beanstalk verwendet – ein Service, der sich automatisch um die Bereitstellung von Code auf EC2-Instanzen kümmert.
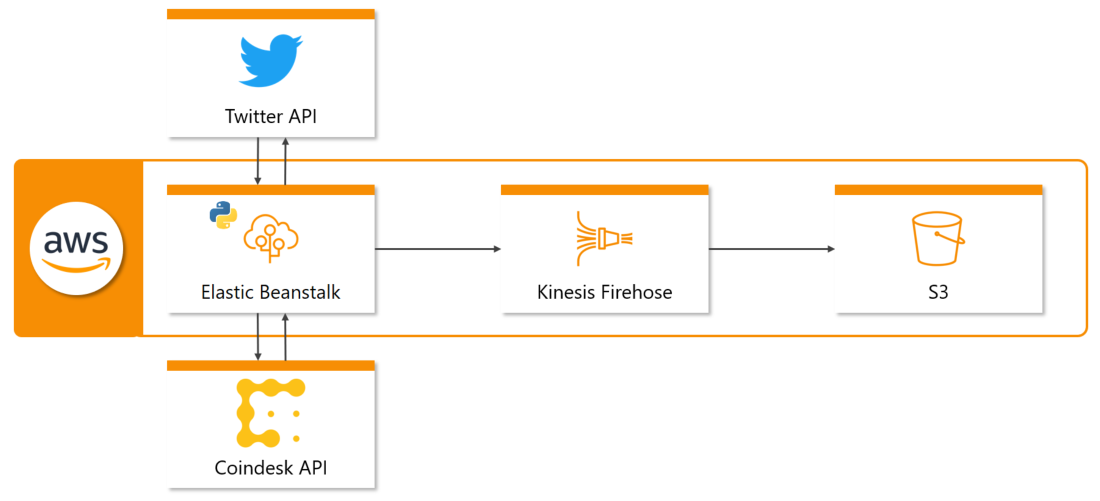
Um die Twitter- und Bitcoin-Daten von Elastic Beanstalk auf einem AWS Storage Service zu übertragen, wird der Service Kinesis Firehose verwendet, welcher Daten entgegennimmt und diese im gewählten Storage Service abspeichert. Kinesis Firehose ermöglicht es zudem, eingehende Daten zu komprimieren oder zu verarbeiten, bevor diese gespeichert werden.
Als zentraler Storage Service für alle im Projekt verwendeten Daten wird S3 benutzt, womit Objekte gespeichert und abgerufen werden können.
Datenverarbeitung, Modelltraining und -vorhersage
Wie zuvor bei der Datensammlung stellt Abbildung 4 sämtliche Komponenten dar, die für die Datenverarbeitung, das Modelltraining und die -vorhersage verantwortlich sind. Da das Training täglich und die Vorhersage stündlich laufen sollen, müssen die dazugehörigen Services in AWS selbst angesteuert werden. Für diesen Zweck wird CloudWatch benutzt – ein Service, der hauptsächlich für das Logging der AWS Services zuständig ist, aber zusätzlich weitere Funktionen anbietet, wie z.B. das Auslösen von Services in einem festlegbaren Intervall.
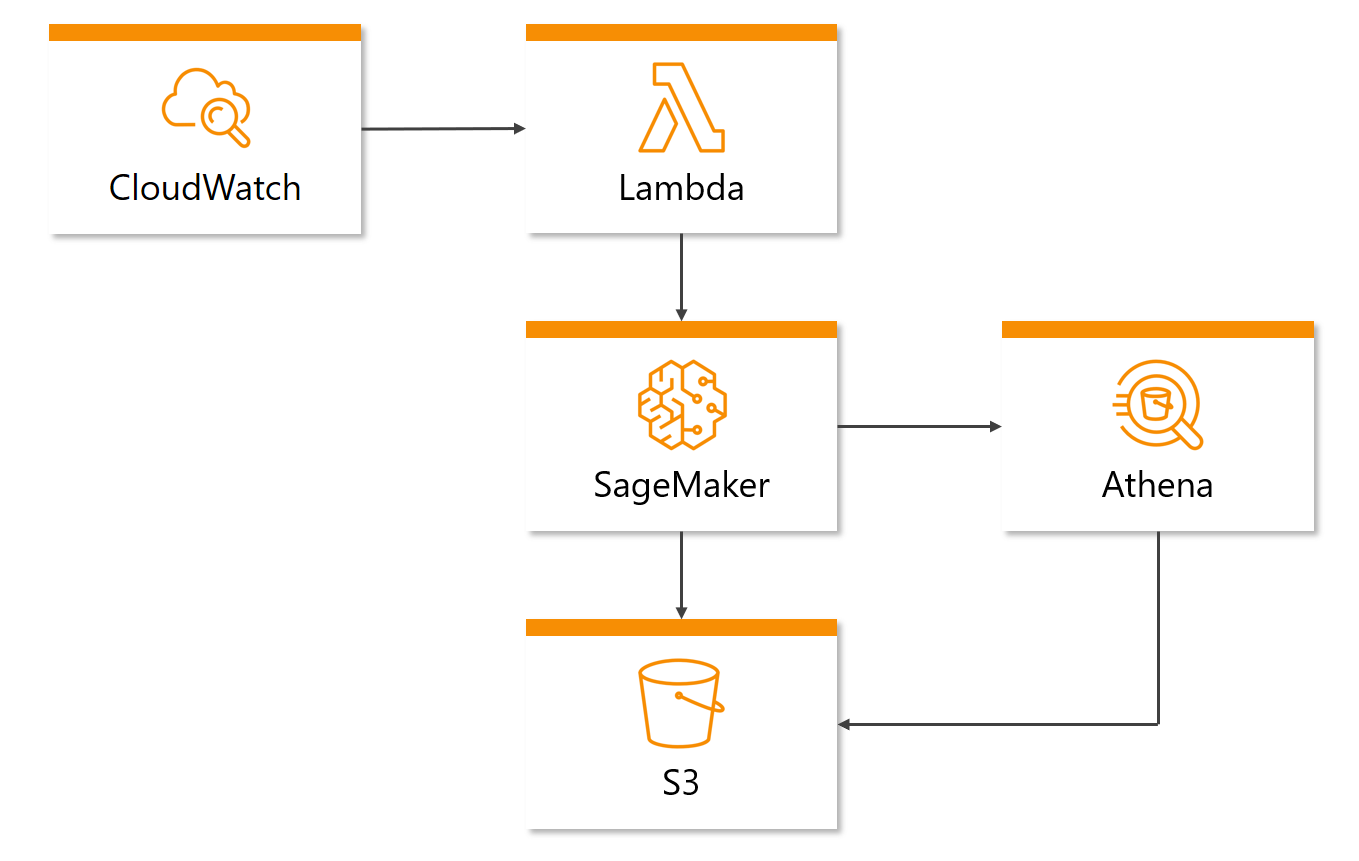
Durch CloudWatch soll ein Training / eine Vorhersage gestartet werden. Allerdings kann der dafür verantwortliche Service (SageMaker => siehe hierzu auch den nächsten Absatz) nicht direkt durch einen CloudWatch Auslöser angesteuert werden. Daher wird der Service Lambda verwendet, welcher das Ausführen von Skripten auf der Cloud ermöglicht. Die Ausführung einer Lambda Funktionen kann durch Events ausgelöst werden, wie z.B. die vorher genannte CloudWatch Auslöser, wodurch ein regelmäßiges Training / Vorhersage gewährleistet werden kann. In der Lambda Funktion wird die AWS SDK Boto3 verwendet, um SageMaker aufrufen zu können.
Bei SageMaker handelt es sich um einen Machine Learning Service, auf dem jegliche Operationen zum Erstellen, Trainieren und Bereitstellen von Machine Learning Modellen möglich sind. Auf SageMaker werden sowohl das Training als auch die Vorhersage ausgeführt. Um auf die Daten in S3 zugreifen zu können, wird der Service Athena verwendet, mit welchem SQL-ähnliche Abfragen in S3 ausgeführt werden können. Das aus dem Training entstehende Modell wird sodann auf S3 gespeichert.
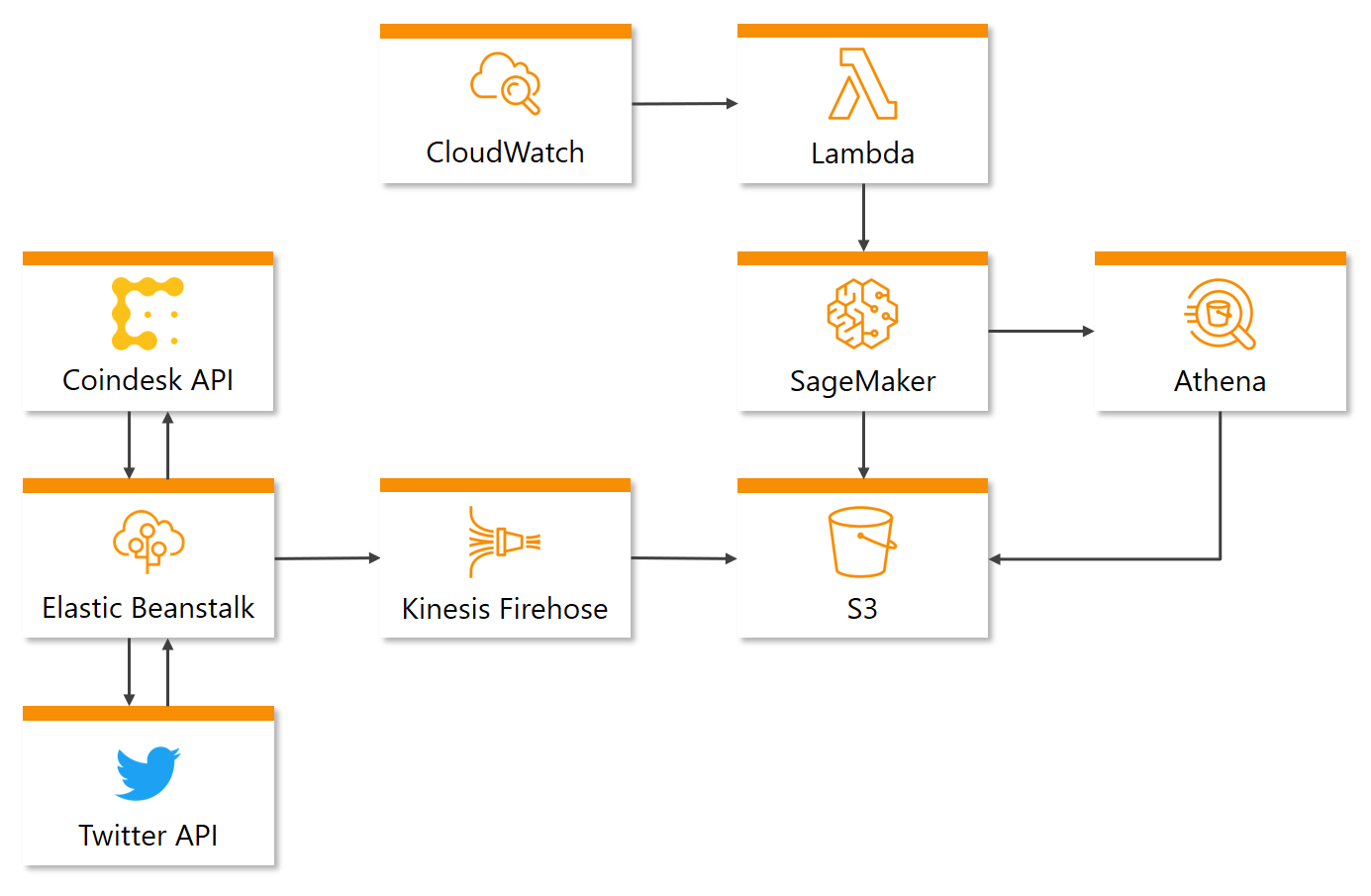
Mit dem Zusammenfügen der Architekturen für die Datensammlung bzw. Modelltraining und Vorhersage ergibt sich nun die Gesamtarchitektur wie in Abbildung 5 dargestellt.
Jetzt haben wir euch die technische Implementierung im Wesentlichen vorgestellt, im zweiten Teil unserer Sapphire-Reihe geht es dann ums Eingemachte: Wie sieht die implementierte Business Logik genau aus und welche Lessons Learned ziehen wir aus dem Projekt?
Co-Autor: Danny Claus
Zu Teil 2 der Bitcoinkursvorhersage mit AWS
Advanced Analytics Projekte mit Machine Learning erfolgreich umsetzen
