
Künstliche Intelligenz (KI)? Ja bitte, aber mit Verstand!
Spätestens mit der von der Bundeskanzlerin ausgesprochenen Forderung, dass Deutschland beim Thema künstlicher Intelligenz eine führende Rolle einnehmen muss [1], ist der Begriff am Höhepunkt der öffentlichen Aufmerksamkeit angelangt.
Mit der damit einhergehenden Popularität ist der Begriff durch die breite Verwendung zunehmend unscharf geworden. In diesem Beitrag möchte ich einerseits den Begriff „KI“ in seiner ursprünglichen Bedeutung vorstellen und andererseits aufzeigen, dass auch „KI“ auf altbekannten Prinzipien aufbaut und diese erweitert.
Starke und schwache KI
Künstliche Intelligenz lässt sich grob in zwei unterschiedliche Teilbereiche einteilen: die starke und die schwache KI. Die starke KI ist der Traum der KI-Forschung: ein Programm, das die geistigen Fähigkeiten des Menschen in allen Facetten wie Bewusstsein, Emotionalität, oder zum Beispiel Kreativität nachbildet. Davon sind wir noch weit entfernt und die Erforschung dieser aufregenden Möglichkeiten: werden wir vermutlich weiterhin den Science-Fiction-Autoren überlassen müssen.

Stattdessen gab es in den letzten Jahren beeindruckende Fortschritte im Bereich der schwachen KI. Hierunter fallen Programme, die klar abgegrenzte geistige menschliche Fähigkeiten nachbilden und darin den Menschen heute häufig sogar in vielen Aspekten übertreffen. Dies umfasst heute praktisch alle Anwendungsfälle von künstlicher Intelligenz. Hierunter fallen zum Beispiel die Erkennung von Objekten und Gesichtern auf Bildern, oder auch Spielprogramme wie „AlphaGo“, die von Google entwickelte KI für das hochkomplexe Brettspiel „Go“.
KI – alter Wein in neuen Schläuchen?
Grundlage dieser revolutionären Fortschritte sind jedoch altbekannte Prinzipien. So zum Beispiel das EVA (Eingabe, Verarbeitung, Ausgabe)-Prinzip (siehe Abbildung). Eine Bilderkennung nutzt beispielsweise ein Bild als Eingabe, verarbeitet dieses und gibt ein Schlagwort als Ausgabe aus.
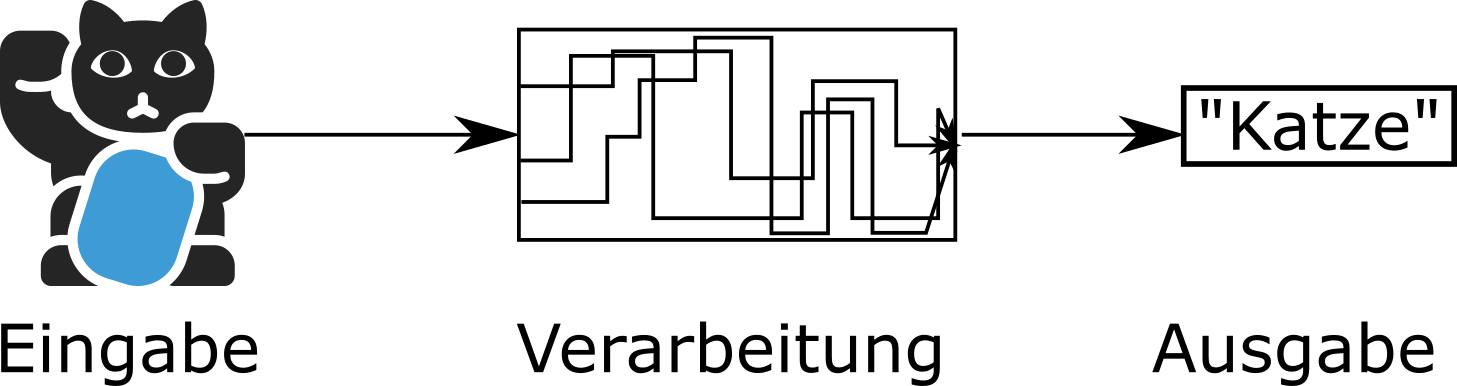
Der Fortschritt besteht in der Art der Verarbeitung, beziehungsweise darin wie die Verarbeitungsvorschrift gefunden wird. Eine Verarbeitungsvorschrift bedeutet hier einfach eine mathematische Vorschrift, mit der zum Beispiel aus dem Bild die Bezeichnung „Katze“ generiert wird.
Dabei haben alle Probleme, die mit KI-Verfahren gelöst werden eine Gemeinsamkeit: sie sind zu komplex, als dass ein Mensch diese Verarbeitungsvorschrift von Hand finden kann. Daher bedient man sich „intelligenter“ Algorithmen, die versuchen, automatisch eine möglichst gute Vorschrift zu finden mit der ein bestimmtes Problem gelöst werden kann.
Betrachten wir hierzu wieder das Beispiel zur Bilderkennung einer Katze. Als Ausgangspunkt dient ein Bilddatensatz. Die vorhandenen Bilder sind zusätzlich mit Schlagworten versehen (z.B. „Katze“, „keine Katze“). Ein Machine Learning Algorithmus versucht nun eine Verarbeitungsvorschrift zu finden, die Bilder von Katzen möglichst gut erkennt. Der Machine Learning Algorithmus testet iterativ, ob die Qualität der Ergebnisse besser oder schlechter geworden ist. Die Qualität der Ergebnisse wird mathematisch über eine sogenannte Zielwertfunktion ausgedrückt. Dafür wird die Verarbeitungsvorschrift leicht geändert und der Wert der Zielwertfunktion berechnet. Wird dieser Wert kleiner, ist das Ergebnis besser geworden. Der Algorithmus führt dann weitere gezielte Anpassungen aus, um noch bessere Zielwerte zu erreichen.
Es gibt jedoch eine Vielzahl an Machine Learning Algorithmen. Je nach Anwendungsfall eignen sich diese unterschiedlich gut, eine bestimmte Problemstellung effizient zu lösen.
Welcher Machine Learning Algorithmus passt zu welchem Problem?
Auf der Suche nach einer möglichst guten Verarbeitungsvorschrift ist daher ein strukturiertes Vorgehen wichtig:

- Problemklassifikation
Im ersten Schritt muss die Problemstellung abstrahiert und klassifiziert werden. Die meisten Probleme lassen sich in drei Hauptkategorien unterteilen: die Vorhersage von Zahlenwerten (Regression), das Erkennen von Labeln (Klassifikation) und das Finden von Ähnlichkeiten in Daten (Clustering). - Auswahl des Algorithmus
Im nächsten Schritt wird aus der sehr großen Anzahl möglicher Machine-Learning-Algorithmen ein geeigneter Ansatz gewählt. Die Auswahl des korrekten Algorithmus ist dabei der Schlüssel zum Erfolg. Häufig arbeitet man sich von einfacheren Ansätzen zu komplexeren Ansätzen vor. Damit ist auch sichergestellt, dass ein Vergleichswert existiert: falls ein komplexer KI-Ansatz nicht in der Lage ist, ein einfaches Modell in der Ausgabequalität zu schlagen, sollte das einfache Modell bevorzugt werden. - Anwendung und Iteration
Schließlich wird der Algorithmus angewandt und die Verarbeitungsvorschrift in vielen kleinen Schritten angepasst. Dazu werden die vorhandenen Daten vereinfacht aufgeteilt in Trainings- und Testdatensatz. Mit dem Trainingsdatensatz sucht der Algorithmus die beste Verarbeitungsvorschrift. Daraufhin wird die Qualität der resultierenden Verarbeitungsvorschrift mit dem Testdatensatz geprüft um sicherzustellen, dass sie allgemeingültig ist.
KI – Think before you act
Was man beim Einsatz der jeweiligen Verfahren nicht vergessen sollte: KI ist kein Selbstzweck. Man muss nicht für jeden Anwendungsfall die komplexesten Machine Learning Algorithmen einsetzen. Häufig haben auch altbekannte, einfachere Methoden wie einfache statistische Analyseverfahren weiterhin ihre Berechtigung. Der Einsatz von KI-Methoden sollte immer auch einen Mehrwert mit sich bringen.
KI wird häufig als sehr schwammiger Begriff genutzt. Heutige Anwendungsfälle bilden ganz klar abgegrenzte menschliche geistige Fähigkeiten nach, wie zum Beispiel eine Gesichtserkennung. Begriffe wie „Bewusstsein“ liegen außerhalb der heutigen Möglichkeiten. Die Grundlagen künstlicher Intelligenz basieren auf altbekannten Prinzipien wie EVA (Eingabe, Verarbeitung, Ausgabe). Die Kunst in der Anwendung von KI liegt darin, die richtige Verarbeitungsart zu wählen und KI überhaupt erst anzuwenden, wenn althergebrachte Methoden versagen.
Diese Beiträge könnten Dich auch interessieren:
Die fünf ultimativen KI Trends für das nächste Jahrzehnt
Buzzword Dschungel Künstliche Intelligenz (KI) – die wichtigsten Begriffe auf einen Blick
Quellen:
[1] https://www.faz.net/aktuell/wirtschaft/diginomics/merkel-deutschland-muss-bei-kuenstlicher-intelligenz-fuehren-15920734.html
