
Data Mesh: Data Lake Evolution
Motiviert durch den spannenden Vortrag „Data Mesh in Practice – How Europe’s Leading Online Platform for Fashion Goes Beyond the Data Lake“1 von Max Schultze (Lead Data Engineer bei Zalando) und Arif Wider (Lead Technology Consultant bei ThoughtWorks),
möchten wir in diesem Beitrag beschreiben, warum ein Data Lake nicht die Lösung für alle Daten-Probleme moderner und vernetzter Systeme ist und welche dieser Probleme mit dem Data Mesh Ansatz besser gelöst werden können.
| Was ist eigentlich ein Data Lake? Beim Data Lake handelt es sich um einen sehr großen Datenspeicher, der die Daten aus den unterschiedlichsten Quellen in ihrem Rohformat aufnimmt. Er kann sowohl unstrukturierte als auch strukturierte Daten enthalten und lässt sich für Big-Data-Analysen einsetzen. (https://www.bigdata-insider.de/was-ist-ein-data-lake-a-686778/). Beispiele für Datenquellen können ERP- oder CRM-Systeme, aber auch Systeme für Produktnutzungs-, Verkaufs-, Website-Besuchsdaten oder sonstige Systeme sein.
Ziele von Big-Data-Analysen können zum Beispiel das Finden von relevanten Kundengruppen, Kundenverhaltensmustern oder Ableiten von Produktverbesserungen sein. |
Mittlerweile sind Data Lakes vom Hype-Thema in das „Tal der Tränen“ abgestiegen. Die großen Erwartungen, die an den Data Lake Ansatz gestellt wurden, haben sich nur teilweise erfüllt.
Während der Ansatz – Daten aus mehreren Quellen und Formaten zusammenzubringen, um neue Erkenntnisse zu erlangen – zu Beginn sehr vielversprechend ist, verwandelt er sich mit zunehmender Größe und Komplexität eher in einen Sumpf aus Daten, der nicht mehr zu überblicken ist, den aber auch keiner abschalten möchte.2 Ist dieser Zustand eingetroffen, kostet der Data Lake Geld, ohne einen Nutzen zu erzeugen.
Ein großes Problem ist zumeist, dass es keine klar verortete Verantwortung für die Aufrechterhaltung von guter Datenqualität gibt: Korrektheit, Relevanz, Verlässlichkeit und Konsistenz der Daten oder Verfügbarkeit auf verschiedenen Systemen.3
Herausforderungen bei Data Lakes
Häufig werden in der Organisation bestehende Datenquellen an den Data Lake angebunden. Die Quellsysteme haben von der Nutzung ihrer Daten durch andere (z.B. im Rahmen von Analysen) keinen direkten Vorteil. Daher haben sie auch keine oder nur eine geringe Motivation, ihre Systeme so anzupassen, dass sie Daten mit guter, bzw. besserer Qualität erzeugen. Auf der anderen Seite stehen die Nutzer des Data Lakes vor einer intransparenten Anhäufung von Daten, den sie nicht durchdringen können. Sie wenden sich im Zweifel an die Betreiber des Data Lakes, da sie die Quellsysteme der Daten im Lake nicht kennen (diese sollen ja durch den Data Lake in gewisser Weise abstrahiert werden). Die Betreiber des Data Lakes haben aber oftmals keine inhaltliche Kenntnis der Daten. Sie sind fokussiert darauf, eine technische Plattform für die Datenspeicherung und -nutzung zur Verfügung zu stellen. Bei inhaltlichen Fragen können sie lediglich als Vermittler zwischen Datenproduzenten und Datennutzern agieren. Damit werden sie zu einem Nadelöhr für die Vermittlung, was über kurz oder lang zu Unzufriedenheit auf allen Seiten führen kann.
Das zentralisierte Modell kann für Organisation funktionieren, die eine geringere Anzahl unterschiedlicher Verbrauchsfälle haben. Bei einem Unternehmen mit einer großen Anzahl an Quellen und einem vielfältigen Verbraucherkreis ist das Scheitern vorprogrammiert.4
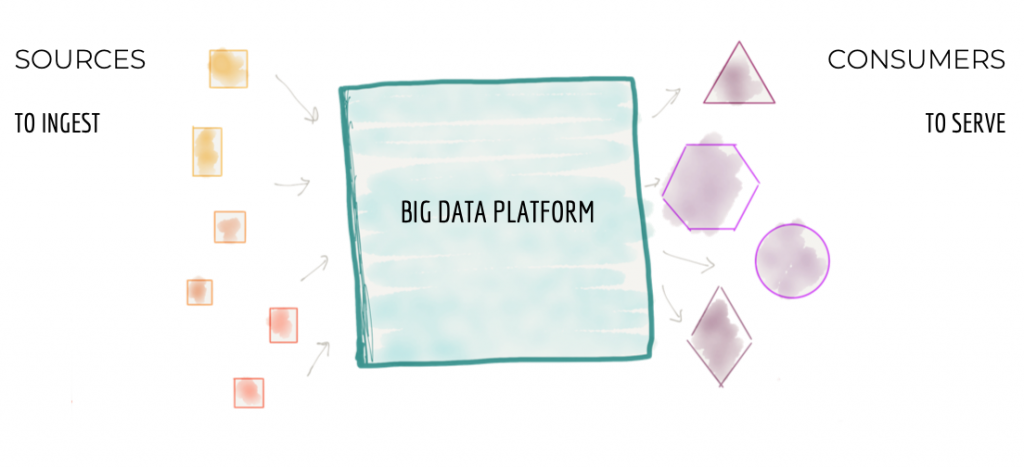
Data Mesh Ansatz bricht Fronten auf
Um diese Frontenbildung aufzubrechen, bringt der Data Mesh Ansatz die Idee von sog. „Datenprodukten“ ein. Ein maßgeblicher Beeinflusser dieser neuen Strömung ist ein alter Bekannter: Martin Fowler. Der Gedanke ähnelt dem, was wir aus dem agilen Vorgehen und anderen Ansätzen wie z.B. DevOps, Microservices etc. oder von den Functional Ownern (FOs) kennen: Statt einer Trennung von Verantwortlichkeiten in Schichten (Analogie: Frontend, Middleware, Datenbank), erfolgt eine Fokussierung auf ein „Produkt“, welches dann ganzheitlich über alle Teilbereiche hinweg entwickelt und gepflegt wird. Diese Produkte lassen sich natürlich auch beliebig vernetzen und kombinieren.
| Data mesh is an architectural and organizational paradigm that challenges the age-old assumption that we must centralize big analytical data to use it, have data all in one place or be managed by a centralized data team to deliver value. Data mesh claims that for big data to fuel innovation, its ownership must be federated among domain data owners who are accountable for providing their data as products (with the support of a self-serve data platform to abstract the technical complexity involved in serving data products); it must also adopt a new form of federated governance through automation to enable interoperability of domain-oriented data products. Decentralization, along with interoperability and focus on the experience of data consumers, are key to the democratization of innovation using data. Quelle: https://www.thoughtworks.com/de/radar/techniques/data-mesh |
Der Daten Product Owner
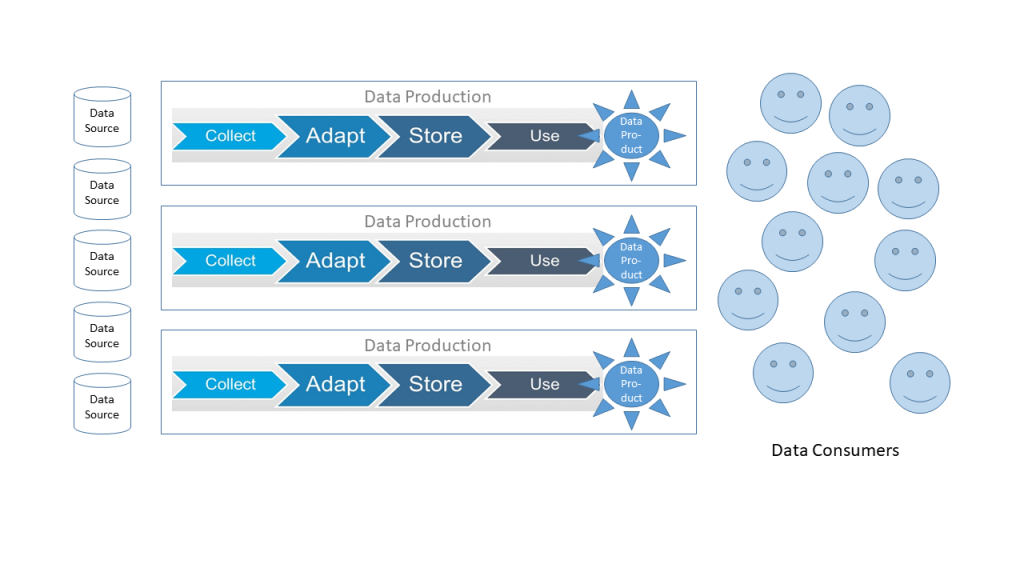
Für jedes der innerhalb einer Organisation angebotenen Datenprodukten gibt es dann einen Daten-PO (Daten Product Owner), der folgende Aufgaben hat:
- Er ist dafür verantwortlich, dass sein Produkt „funktioniert“. Dazu steht er sowohl mit den Nutzern des Datenprodukts in Verbindung, als auch mit den „Herstellern“ (Entwicklungsteam, Data Engineers, Data Scientists) und den „Zulieferern“ (Quellsysteme).
- Er pflegt sein Datenprodukt wie ein reales Produkt: Er vertreibt und erläutert sein Produkt, sammelt Verbesserungsvorschläge von seinen Kunden ein, entwickelt neue Produktideen, prüft, ob sein Produkt noch „Gewinn“ abwirft bzw. genutzt wird und begleitet dieses über einen Produkt-Lebenszyklus.
Hinter jedem Datenprodukt kann ein eigenes Team stehen. Dadurch lässt sich die Anzahl der Datenprodukte mit diesem Ansatz leichter skalieren als mit dem zentralen Data Lake, bei dem das Betreiber-Team im Prinzip für alle, aus den Data Lake Daten entstehenden Produkte verantwortlich ist. Dabei kann es einfache (Datenprodukte, die sehr nah an den Quelldaten sind) und komplexe Datenprodukte (Datenprodukte, die aus Quelldaten mehrere Quellen oder sogar anderen Datenprodukten zusammengesetzt sind) geben.
Positive User Experience entscheidend
Ein Datenprodukt sollte nicht nur aus den Nutzdaten an sich, sondern auch aus einer Beschreibung der Daten (was sagen die Daten genau aus) sowie weiteren Metadaten (z.B. wie viele Datensätze gibt es, wie aktuell sind sie, wie oft werden sie genutzt) bestehen. Liegen nur die Nutzdaten vor, bedarf ein Nutzer einer Anleitung zur Nutzung. Er kann die Daten nicht selbstständig nutzen – was letztendlich die „User Experience“ der Daten negativ beeinflusst. Positiv auf die User Experience wirkt es sich aus, wenn die Daten in einem gemeinsamen Standard vorliegen und der Zugriff standardisiert möglich ist. Für die Wahrung einer guten Data User Experience kann wiederum ein zentrales Gremium eingesetzt werden, welches über alle Datenprodukte hinweg Standards definiert und deren Umsetzung ermöglicht.
Diese Gedanken fasst nachfolgende Grafik übersichtlich zusammen:
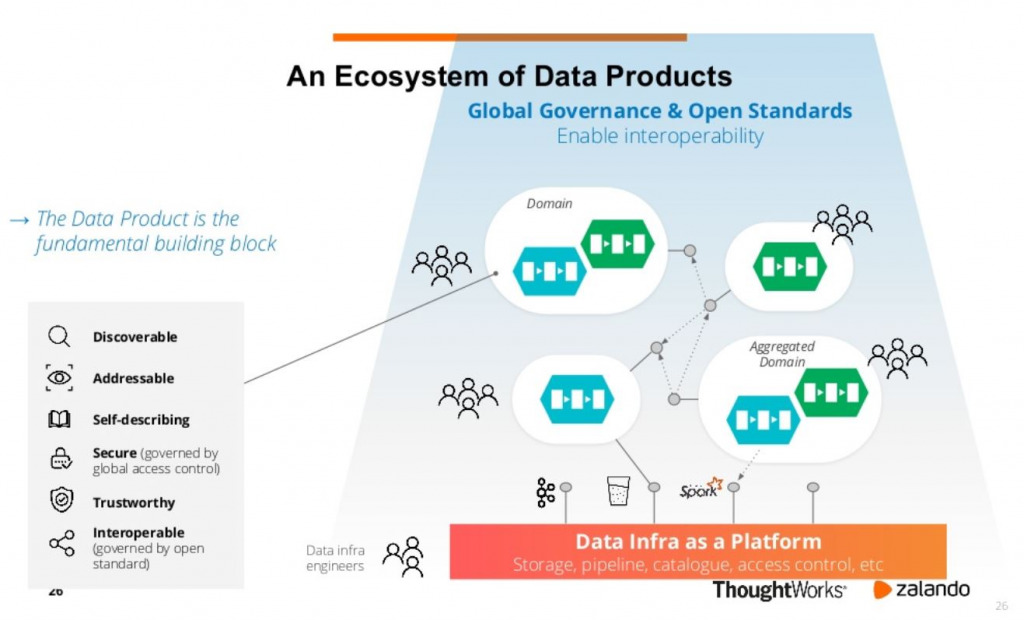
Darin erkennbar sind sowohl die einzelnen Datenprodukte (und die Anforderungen an diese), welche in einer Beziehung zueinanderstehen können und jeweils durch ein Datenprodukt-Team betreut werden. Die Bereitstellung der Datenprodukte kann auf einer gemeinsamen „Data Infra as a Platform“ erfolgen, welche Standards definiert und die einfache Herstellung und Nutzung der Datenprodukte gewährleistet, ohne die in der Plattform befindlichen Daten im Detail kennen zu müssen (dafür sind ja die Daten-Produkt-Teams da).
Fazit
Auch ein Data Mesh löst nicht alle Probleme moderner vernetzter IT Systeme. Es erweitert den Data Lake aber um die Idee der Datenprodukte und des Ansatzes der übergreifenden Bearbeitung dieses Produktes.
Ein Data Lake selbst kann in überschaubaren Umfeldern durchaus ein guter Startpunkt für das Zusammenbringen von Datenquellen, bzw. Datenangeboten und Datennutzern, bzw. Datenbedarfen sein. Ein Data Lake ist so lange erfolgreich, wie die Anzahl an Datenquellen und Datennutzern überschaubar ist und von einem zentralen Team betreut werden kann. Wenn aber die Anzahl auf einer oder sogar auf beide Seiten überhandnimmt, ist alleine schon die Verwaltung des Data Lakes aufwändig. Durch den reinen Verwaltungsaufwand leiden inhaltliche Aufgaben wie z.B. die Sicherstellung von Datenqualität.
Kommt dann noch ein sehr dynamisches Umfeld von Datenquellen und Datennutzern (hochfrequente Änderungen von Schnittstellen, Datenmodellen, etc.) hinzu, wie es in modernen Microservice-Architekturen zunehmend der Fall ist, ist Unzufriedenheit auf allen Seiten vorprogrammiert. Der Data Lake und das Data Lake Team wird zum Nadelöhr für alle Parteien. Durch sinkende Datenqualität wird der Data Lake zum Datensumpf.
Das Data Mesh setzt an diesem Punkt an. Durch die Trennung der Verwaltung von Data Lake Infrastruktur von der inhaltlichen Zusammenführung von Daten zu Datenprodukten erfolgt eine klare Fokussierung und somit Aufgabenteilung.
Die Fokussierung von Querschnittsteams auf konkrete Datenprodukte von der oder den Datenquellen bis zu den Datennutzern bietet diese Teams die Möglichkeit, nicht nur Daten zu verwalten, sondern sich auf Dateninhalte zu konzentrieren. Dadurch kann unter anderem die Datenqualität sichergestellt und eine gute „User Experience“ der Daten gewährleistet werden.
Doch auch diese klare Konzentration auf Datenprodukte ist nur dann erfolgreich, wenn alle Parteien dabei in Einklang sind. Sämtliche Technik und alle Prozesse sind nutzlos, wenn nicht Menschen (Datennutzer und Datenanbieter) miteinander sprechen, bzw. durch Datenproduktteams in den Dialog gebracht werden, um ihre Bedürfnisse und ihre Vorhaben miteinander abstimmen.
Brauchen Sie Unterstützung dabei, Datenangebote und Datenbedarfe in Ihrem Unternehmen aufzuspüren? Dann schaue hier vorbei.
Dieser Blogbeitrag zum Thema Data Lake könnte dich auch interessieren: Wie viel Data Lake steckt in einem Scalable Data Hub?
Quellen:
1 https://www.meetup.com/de-DE/ThoughtWorks-Muenchen/events/270948960/
2 https://www.computerwoche.de/a/wie-ihr-data-lake-sauber-bleibt,3331146
4 https://martinfowler.com/articles/data-monolith-to-mesh.html
