
Datenvisualisierung in Python
In Big Data ist die Visualisierung von Daten besonders wichtig, um daraus Erkenntnisse zu gewinnen, die beispielsweise zum Trainieren von Machine Learning-Modellen verwendet werden können. Im Rahmen dieses Blogbeitrags werden Methoden zur Datenvisualisierung in Python vorgestellt.
Die Datenvisualisierung ist ein zentraler Aspekt im Bereich Big Data, mit welchem sich wichtige Kennzahlen und sonstige Informationen visuell darstellen lassen. Generell wird diese mit Software wie Tableau ausgeführt und baut auf die initiale Datenanalyse auf, welche üblicherweise mit Python durchgeführt wird – da haben wir uns gedacht, dass wir die Datenvisualisierung auch mal mit Python probieren und uns somit einen Überblick über eine „low-level Datenvisualisierung“ verschaffen könnten. Zudem wäre es mit Python möglich, prototypische Dashboards zu erstellen, bevor eine dafür spezialisierte Software verwendet wird.
In diesem Blogbeitrag wollen wir einige Bibliotheken zur Datenvisualisierung, die in Python zur Verfügung stehen, vorstellen und erläutern, inwiefern diese sich voneinander unterscheiden. Diese sind:
matplotlibplotlyseaborn
matplotlib [1] stellt hierbei die bei weitem gängigste Datenvisualisierungsbibliothek für Python dar und erstellt Diagramme in Form von statischen Bildern, welche beispielsweise für Druckerzeugnisse verwendet werden können. Aufgrund der Tatsache, dass matplotlib eine low-level-Bibliothek darstellt, können die durch matplotlib erzeugten Diagramme nach Belieben geändert werden. Allerdings ergibt sich dadurch auch einen höheren Aufwand, Diagramme zu erzeugen.
seaborn [2] ist eine Bibliothek, die auf matplotlib aufbaut, d. h. ein Wrapper, welche das Erstellen von Diagrammen erheblich vereinfacht. Aktionen, die in matplotlib explizit definiert werden müssen, wie zum Beispiel das Setzen von Labels für die einzelnen Achsen des Koordinatensystems, übernimmt seaborn im Hintergrund.
plotly [3] ermöglicht im Gegensatz zu matplotlib und seaborn, interaktive Diagramme zu erstellen, indem es eine JavaScript-Bibliothek verwendet. Damit ist es möglich, mit der Maus über einzelne Diagrammelemente zu bewegen und genauere Informationen zu erhalten, was bei den anderen Datenvisualisierungsbibliotheken nicht möglich ist.
Im Folgenden werden verschiedene Diagrammtypen dargestellt, die mit den unterschiedlichen Bibliotheken implementiert werden. Dadurch wird ersichtlich, welche visuellen und praktikablen Unterschiede die Bibliotheken zueinander haben. Als Datensatz soll dazu eine Liste von Aufträgen verwendet werden, bei welchen Kunden verschiedene Arten von Produkten gekauft haben. In jeder Zeile werden verschiedene Informationen über einen Kauf gespeichert, wie z. B. der erzielte Umsatz oder Gewinn.
Mithilfe der Bibliothek pandas, welche für die Datenanalyse genutzt wird, können die Daten wie folgt eingelesen werden:
import pandas as pd
df = pd.read_excel("datensatz.xls", sheet_name="sheet_2")Balkendiagramm
Ein einfaches und häufig verwendetes Diagramm in der Datenvisualisierung ist das Balkendiagramm, welches Balken enthält, deren Länge den dazugehörigen Daten entsprechen. Im Folgenden soll ein Balkendiagramm erstellt werden, welches darstellt, wie viel Umsatz nach Produktkategorie erwirtschaftet wurde.
matplotlib
Zunächst soll mit matplotlib visualisiert werden, wie viel Umsatz nach Produktkategorie gemacht wurde. Da matplotlib low-level ist und die meisten Anpassungen am Diagramm daher explizit gemacht werden müssen, ist selbst das Erstellen eines solchen Diagramms gewissermaßen aufwendig.
Bevor allerdings ein Diagramm erstellt werden kann, ist zu beachten, dass die Daten zunächst so vorverarbeitet werden müssen, sodass diese sich in einer für die jeweilige Datenvisualisierungsbibliothek geeigneten Form befinden. Für diesen Anwendungsfall müssen die Daten nach Produktkategorie gruppiert werden und anschließend die Summe des Umsatzes pro Produktkategorie berechnet werden.
Beim Ausführen des Codes ergibt sich folgendes Diagramm:
fig, ax = plt.subplots(figsize=(14, 6))
ax.set_xlabel("Umsatz")
ax.set_ylabel("Kategorie")
ax.set_title("Darstellung von Umsätzen nach Kategorie")
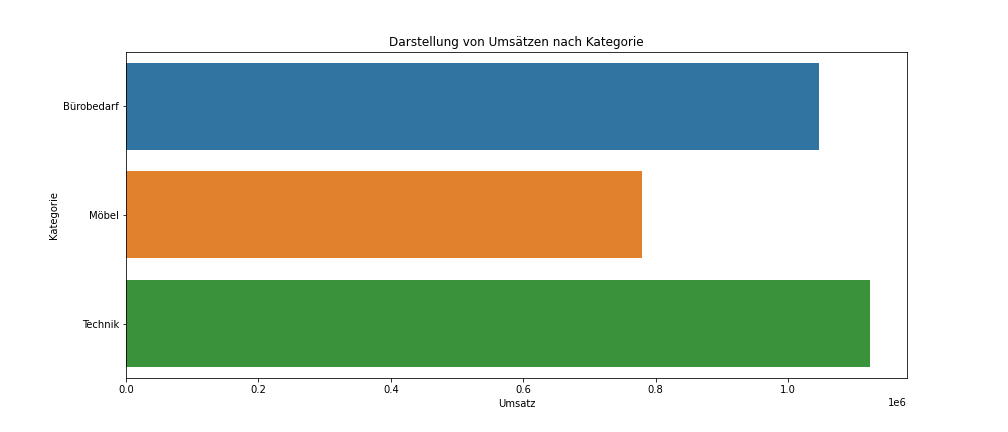
ax.barh(df_contracts["Kategorie"], df_contracts["Umsatz"], 0.8, color=["tab:red", "tab:blue", "tab:orange"])Wird dieser Code nun ausgeführt, kommt folgendes Ergebnis heraus (siehe Abbildung 1):
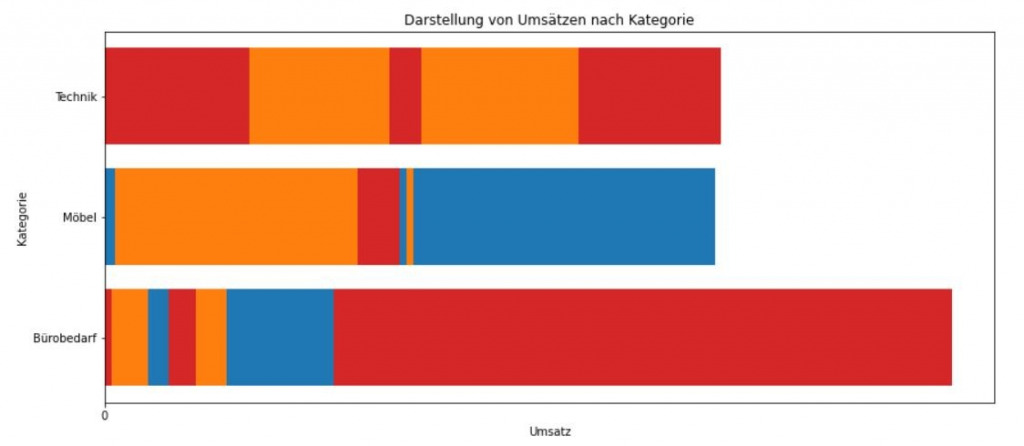
Da die Daten nicht ausreichend vorverarbeitet wurden, hat matplotlib die Daten falsch interpretiert und somit ein falsches Diagramm erstellt. Im Gegensatz zu Tableau ist es in Python häufig notwendig, Daten zuerst aufzubereiten, bevor diese in Diagrammen verwendet werden können. Um demnach ein korrektes Ergebnis zu erhalten, müssen die Daten nach Produktkategorie gruppiert werden, wodurch anschließend eine Summierung nach Umsatz möglich ist. Mithilfe von pandas kann die gewünschte Vorverarbeitung wie folgt realisiert werden:
df_sum = df.groupby("Kategorie", as_index=False)["Umsatz"].sum()Beim erneuten Ausführen des oben dargestellten Codeblocks mit df_sum anstatt von df wird nun folgendes Diagramm erstellt (siehe Abbildung 2):
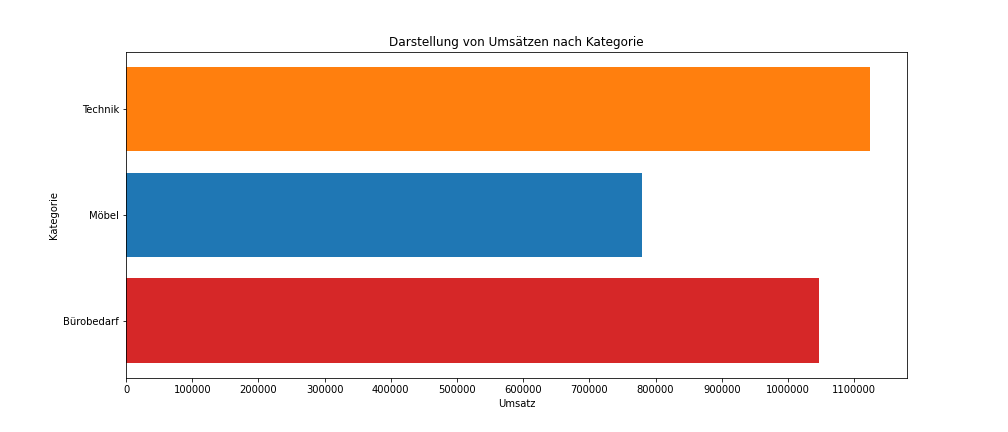
matplotlibplotly
Nun soll das Balkendiagramm mit plotly implementiert werden. Das Erstellen des Diagramms ist hier wesentlich einfacher – es wird nur eine Zeile Code benötigt, alle anderen Aspekte des Diagramms wie zum Beispiel Beschriftung werden von plotly übernommen:
px.bar(df_sum, x="Umsatz", y="Kategorie", orientation="h", title="Darstellung von Umsätzen nach Kategorie")Als Ergebnis wird das in Abbildung 3 dargestellte Diagramm ausgegeben:
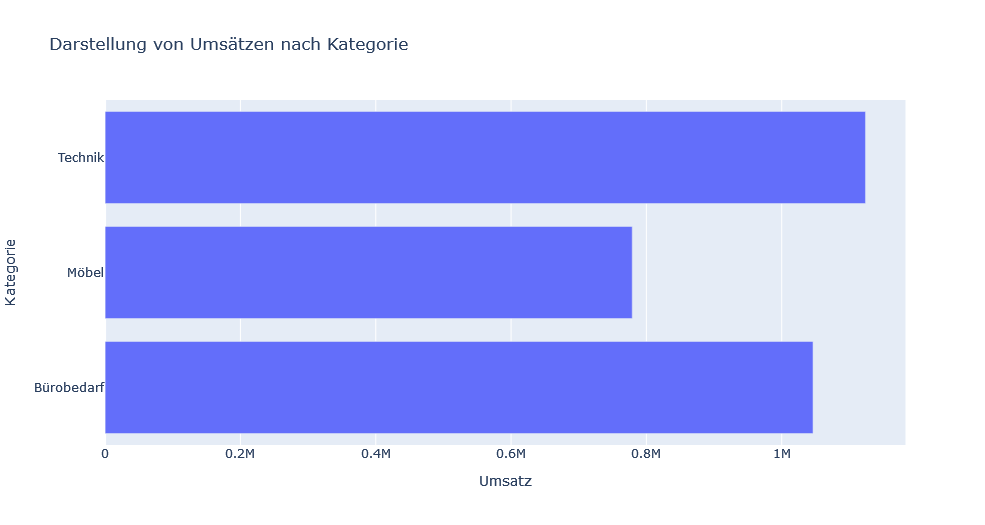
plotlyWird die Maus über die einzelnen Balken bewegt, können weitere Details eingesehen werden, wie beispielsweise die genaue Menge an Umsatz, die für eine bestimmte Kategorie erwirtschaftet wurde (siehe Abbildung 4):
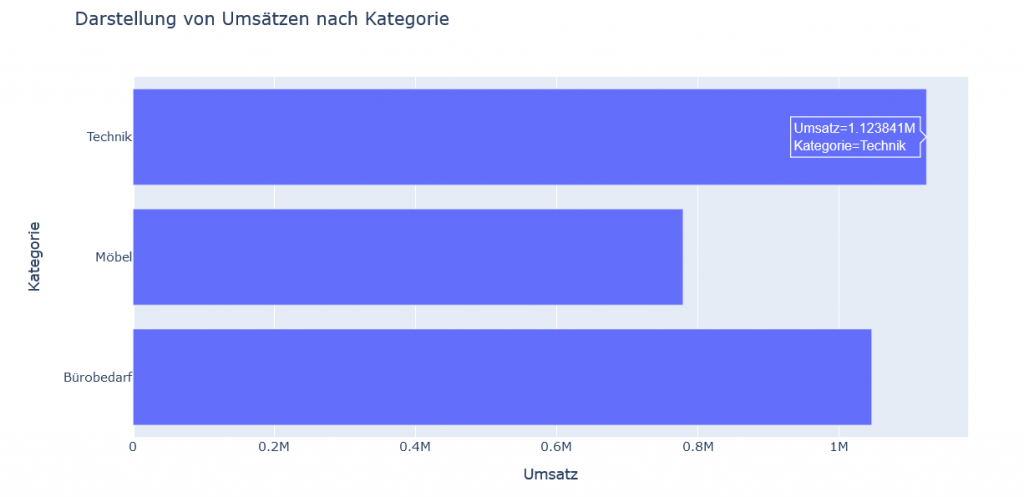
plotly, wobei die Interaktivität mit der Maus dargestellt wird.Mit plotly ist es demnach im Gegensatz zu matplotlib und seaborn möglich, interaktive Diagramme wie in Tableau zu erstellen, anstatt nur statische Bilder zu erzeugen.
seaborn
Weil seaborn auf matplotlib aufbaut, können hier alle Funktionen von matplotlib verwendet werden. Zusätzlich stellt seaborn Funktionen bereit, mit welchen ebenfalls Diagramme erstellt werden können, allerdings wesentlich einfacher. Für das Balkendiagramm wird beispielsweise wie bei plotly nur eine Zeile Code benötigt, während matplotlib fünf Zeilen erfordert:
sns.lineplot(data=df, x="Jahr", y="Umsatz", hue="Kategorie")Beim Ausführen des Codes wird folgendes Diagramm angezeigt (siehe Abbildung 5):
seabornDas dadurch entstandene Diagramm ist hinsichtlich Formatierung praktisch dem von matplotlib identisch. Zusätzlich ist auch hier das Diagramm lediglich ein statisches Bild. Aus diesem Grund soll im Folgenden zur Einfachheit nur noch seaborn betrachtet werden, da sich Diagramme durch die high-level Funktionen von seaborn schneller erstellen lassen.
Liniendiagramm
Ebenfalls ein häufig verwendetes Diagramm in der Datenvisualisierung ist das Liniendiagramm. Mit dieser ist es möglich, diskrete Datenpunkte in einem Koordinatensystem darzustellen und mit einer Linie zu verbinden. Üblicherweise wird ein Liniendiagramm dazu verwendet, den Verlauf der Daten innerhalb eines Zeitraums zu zeigen. Als Beispiel soll hier der Umsatz je Produktkategorie von 2018 – 2021 dargestellt werden.
Wie beim Balkendiagramm muss zunächst erneut die entsprechende Vorverarbeitung der Daten durchgeführt werden, indem diese nach Jahr und Kategorie gruppiert und anschließend nach Umsatz summiert werden. Anschließend kann das Diagramm erstellt werden.
Nun soll mit plotly ein Liniendiagramm gezeichnet werden, welches den Umsatz nach Produktkategorie und Jahr darstellt. Zunächst muss erneut die entsprechende Vorverarbeitung der Daten durchgeführt werden, indem diese nach Jahr und Kategorie gruppiert und anschließend nach Umsatz summiert werden:
df["Jahr"] = df["Bestelldatum"].apply(lambda x: x.year)
df = df.groupby(["Jahr", "Kategorie"], as_index=False)["Umsatz"].sum()Anschließend kann mit folgendem Code das Diagramm erstellt werden:
fig = px.line(category_sum, x="Jahr", y="Umsatz", color="Kategorie", title="Umsatz nach Kategorie und Jahr")
fig.update_layout(xaxis={"tickmode": "linear", "dtick": 1})Wird dieser Codeblock ausgeführt, so erscheint das in Abbildung 6 gezeigte Liniendiagramm:
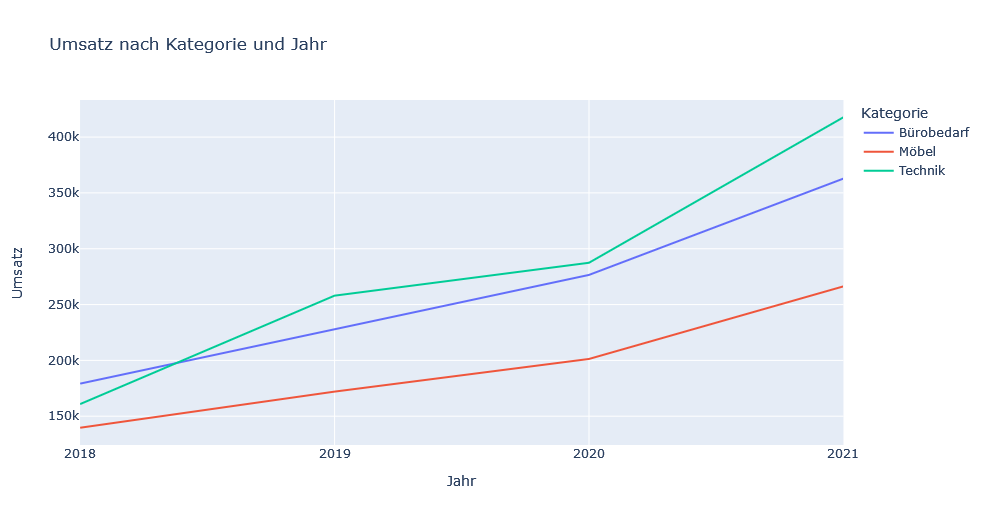
plotly. Diese ist ebenfalls interaktiv.seaborn
Auf Basis der vorverarbeiteten Daten kann in seaborn wie folgt ein Liniendiagramm erstellt werden:
fig, ax = plt.subplots(figsize=(14, 10))
ax.set_xticks(category_sum["Jahr"].unique())
ax.set_title("Umsatz nach Kategorie und Jahr")
sns.lineplot(data=category_sum, x="Jahr", y="Umsatz", hue="Kategorie")Daraus entsteht folgendes Diagramm (siehe Abbildung 7):
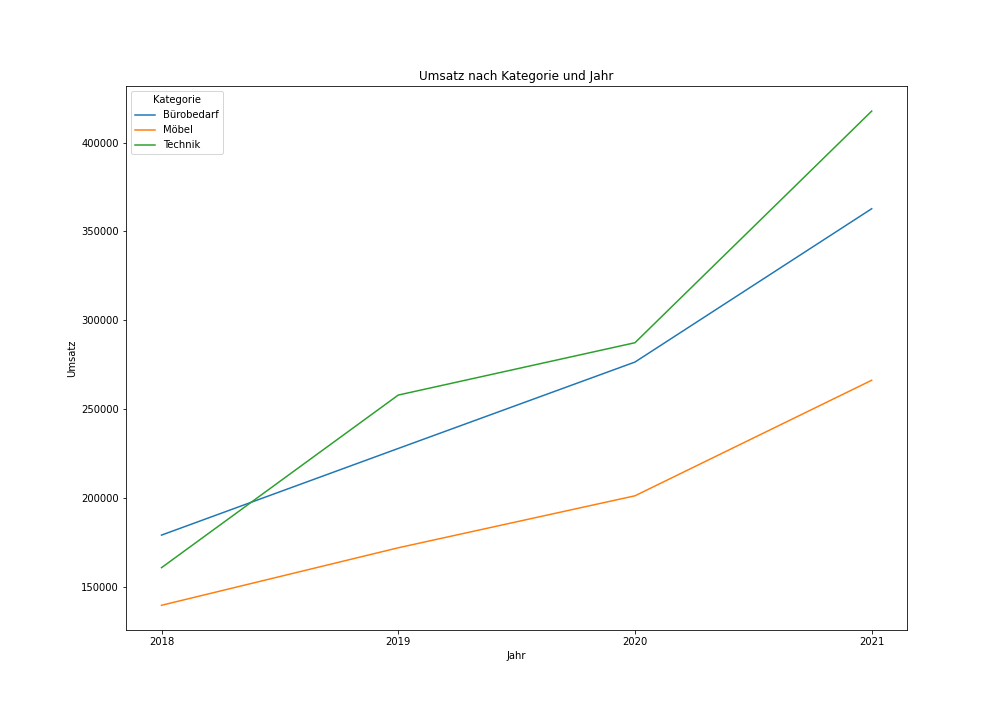
seaborn.Tortendiagramm
plotly
Mithilfe eines Tortendiagramms lassen sich Anteile an einem gesamten Wert darstellen. Hier soll gezeigt werden, wie viel Anteil am Umsatz jede Produktkategorie besitzt. Mit plotly lässt sich nach der entsprechenden Vorverarbeitung wie folgt implementieren:
px.pie(category_sum, values="Umsatz", names="Kategorie", title="Anteil am Umsatz nach Kategorie")Durch das Ausführen dieses Codeblocks wird folgendes Diagramm erstellt (siehe Abbildung 8):
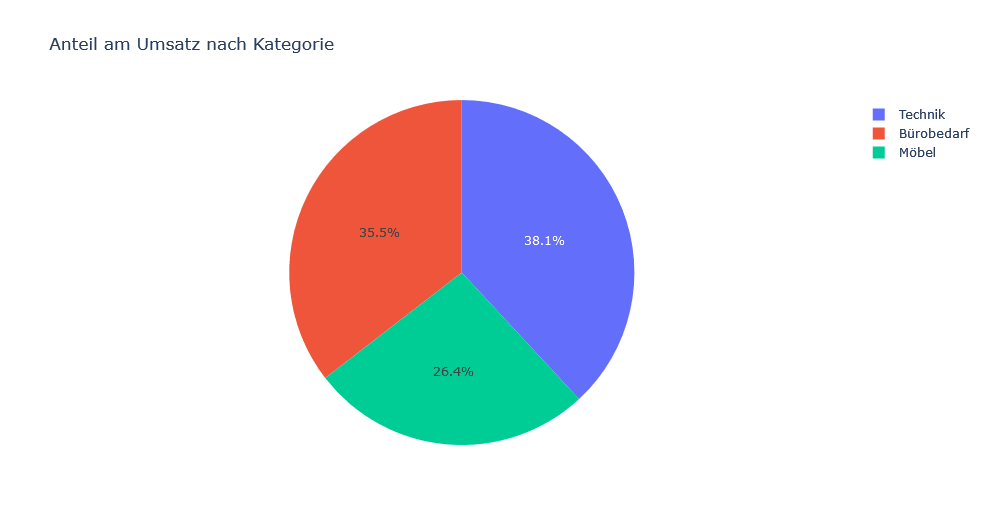
plotly.seaborn
Die Erstellung eines Tortendiagramms erfolgt mit seaborn wie folgt:
fig, ax = plt.subplots(figsize=(10, 10))
pie_colors = sns.color_palette("pastel")
ax.set_title("Anteil am Umsatz nach Kategorie")
ax.pie(category_sum["Umsatz"], labels=category_sum["Kategorie"], colors=pie_colors, autopct="%.1f%%")Dadurch entsteht das in Abbildung 9 dargestellte Diagramm:
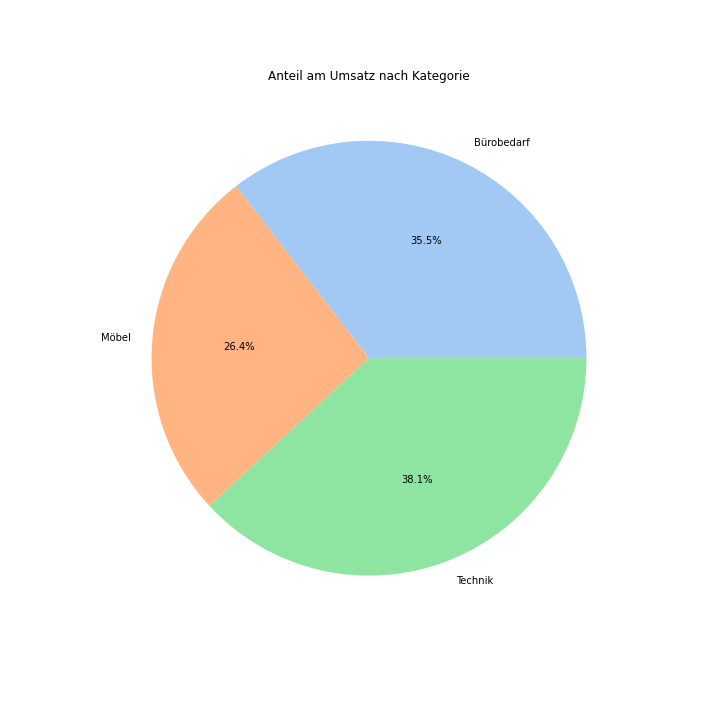
seaborn.Scatterplot
plotly
Mit einem Scatterplot lassen sich Datenpaare in Bezug auf beliebige Merkmale darstellen. Im Folgenden soll dargestellt werden, wie viel Umsatz und Gewinn Datenpaare von Hersteller, Produktkategorie und Unterkategorie erzielt haben. Zunächst muss der Datensatz entsprechend vorverarbeitet werden:
df["Hersteller"] = df["Produktname"].apply(lambda x: str(x).partition(" ")[0])
df_scatter = df.groupby(["Kategorie", "Unterkategorie", "Hersteller"], as_index=False)
revenue_profit = df_scatter[["Umsatz", "Gewinn"]].sum()In plotly lässt sich ein Scatterplot auf Basis der vorverarbeiteten Daten wie folgt erstellen:
px.scatter(revenue_profit, x="Gewinn", y="Umsatz", color="Kategorie", title="Scatterplot")Dadurch entsteht folgendes Diagramm (siehe Abbildung 10):
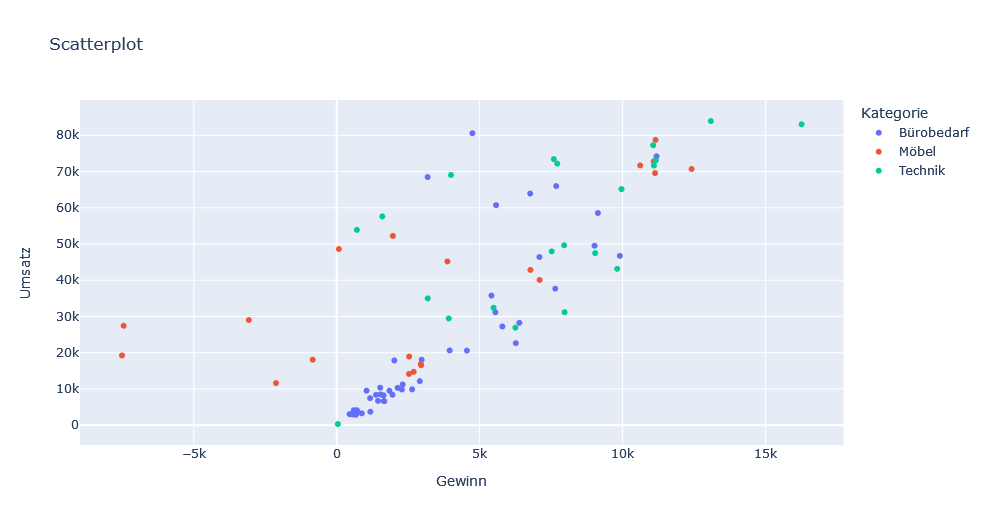
plotly.seaborn
Mit seaborn lässt sich ein Scatterplot wie folgt realisieren:
fig, ax = plt.subplots(figsize=(16, 10))
ax.set_title("Scatterplot")
sns.scatterplot(data=revenue_profit, x="Gewinn", y="Umsatz", hue="Kategorie")Beim Ausführen des Codeblocks entsteht das in Abbildung 11 dargestellte Diagramm:
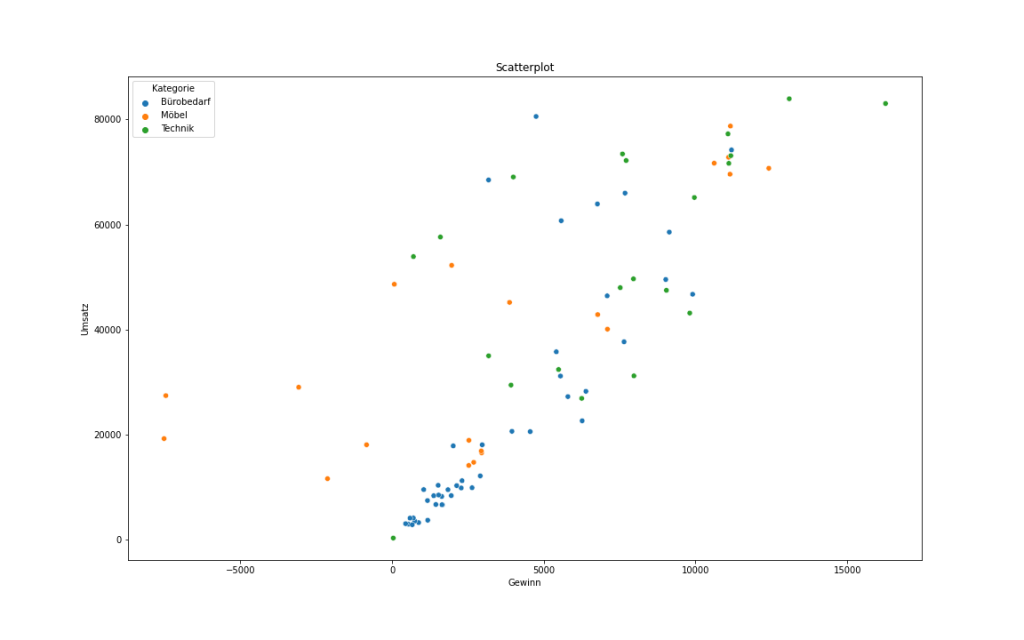
seaborn.Map
plotly
Werden Daten auf Länderebene oder Ähnliches erhoben, ist es sinnvoll, diese in einer Karte darzustellen. Im Folgenden soll betrachtet werden, wie viel Umsatz je Land erwirtschaftet wurde. Dazu muss zunächst der Datensatz vorverarbeitet werden:
country_sum = df_contracts.groupby("Land/Region", as_index=False)["Umsatz"].sum()
country_dict = {
"Belgien": "BEL",
"Deutschland": "DEU",
# ...
}
country_sum["ISO"] = country_sum["Land/Region"].apply(lambda x: country_dict[x])Auf Basis der ISO-Codes kann plotly die Daten auf eine geeignete Karte plotten:
Bei seaborn und matplotlib ist dieser Prozess allerdings deutlich aufwendiger. Hier werden out-of-the-box keine fertigen Karten zu Länder / Regionen bereitgestellt, weshalb diese selbst erstellt werden müssen. Dazu sind unter anderem folgende zwei Ansätze möglich:
- Verwendung von basemap [4]
Mit derBasemap-Klasse wird prinzipiell ein Globus bereitgestellt, der nach Belieben angepasst werden kann. Damit kann die Ansicht beispielsweise auf einen bestimmten Bereich eingeschränkt und bestimmte Regionen farbig markiert werden. - Verwendung von geopandas [5]
geopandasist eine Bibliothek, die aufpandasaufbaut und es ermöglicht, mit Geodaten zu arbeiten und auch zu plotten. Zum Plotten auf einer Karte werden allerdings geeignete Daten benötigt, wie zum Beispiel ein Polygon oder ein Tupel mit Breiten- und Längengrad, welchesgeopandaszum Zeichnen verwenden kann. - Manuelles Plotten
Grundsätzlich ist es möglich, die einzelnen Umrisse der Länder / Regionen selbst zu plotten und entsprechend zu füllen. Allerdings ist dieser Ansatz mit sehr viel Aufwand verbunden, weshalb bevorzugt andere Ansätze betrachtet werden sollen.
Das Plotten einer Karte mit seaborn oder matplotlib soll hinsichtlich des Aufwands in diesem Blogbeitrag außen vor gelassen werden. Dennoch soll kurz gezeigt werden, wie eine mit seaborn bzw. matplotlib erstellte Karte aussehen kann. In Abbildung 12 ist ein Diagramm dargestellt, welches unter Zuhilfenahme von geopandas erstellt wurde und den Anteil der Weltbevölkerung pro Land visualisiert:
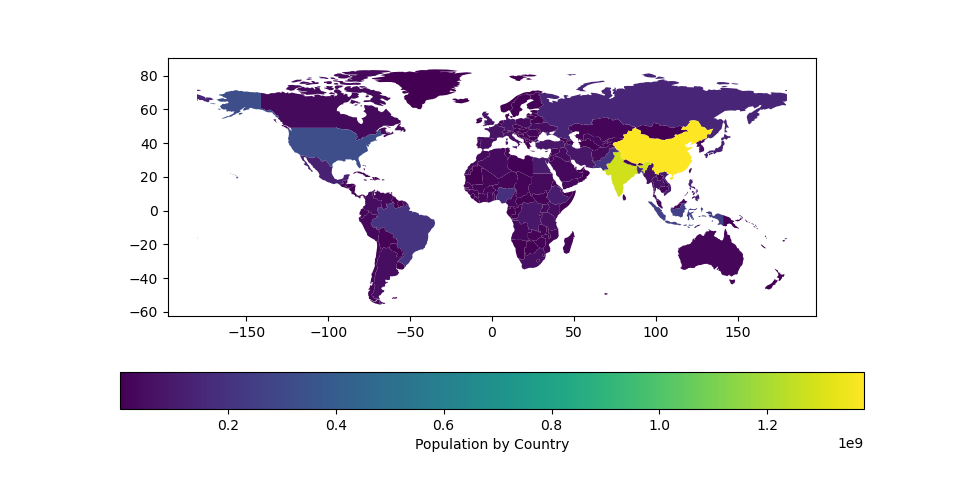
geopandas generierte Karte [6].Fazit
Um einen ersten Einblick in die Daten zu bekommen, bedarf es nicht unbedingt eine Datenvisualisierungssoftware – auch mit Python lassen sich sogar interaktive Diagramme ohne großen Aufwand realisieren und darstellen lassen. Diese lassen sich zwar nicht in Dashboards gruppieren, weshalb in solchen Fällen immer noch eine dafür geeignete Software zu bevorzugen ist, aber mit Python können durchaus Prototypen implementiert werden, auf deren Basis ein passendes Dashboard erstellt werden kann.
Quellen
[1] matplotlib. Matplotlib – Visualization with Python. [Online]. URL: https://matplotlib.org/ (besucht am 10.05.2022)
[2] seaborn. seaborn: statistical data visualization. [Online]. URL: https://seaborn.pydata.org/ (besucht am 10.05.2022)
[3] plotly. Plotly: The front end for ML and data science models. [Online]. URL: https://plotly.com/ (besucht am 10.05.2022)
[4] matplotlib. The Matplotlib Basemap Toolkit User’s Guide. [Online]. URL: https://matplotlib.org/basemap/users/index.html (besucht am 10.05.2022)
[5] geopandas. About GeoPandas. [Online]. URL: https://geopandas.org/en/stable/about.html (besucht am 10.05.2022)
[6] geopandas. Mapping and Plotting Tools. [Online]. URL: https://geopandas.org/en/stable/docs/user_guide/mapping.html (besucht am 10.05.2022)
