
Den Nutzen von Big Data auch ohne Big Data Technologien erreichen
Vor allem in mittelständischen Unternehmen gilt Big Data mitunter als eine Art „eierlegende Wollmilchsau“. Die Einschätzung „Heute macht man das halt mit BigData, Spark, SMACK-Stack, Hortonworks, in der Cloud mit AWS“ führt häufig zu sehr komplexen Lösungen mit hohen Anforderungen an die Hardware. Ein Aufwand, der in vielen Fällen aber gar nicht erforderlich wäre oder gar ungeeignete Lösungen bringt. Zumal die Kosten oft den Nutzen deutlich übersteigen. Vor diesem Hintergrund gerieten klassische Technologien wie relationale Datenbanken durch neue Technologien, Produkte und Paradigmen im Big Data Umfeld in den Hintergrund.
Davon ausgehend beleuchten wir nachfolgend klassische Technologien, die in der Literatur im Big Data Umfeld als nicht leistungsfähig eingestuft werden, hinsichtlich Skalierungsmöglichkeiten. Ziel ist es zu validieren, wie zum Beispiel auch mit relationalen Datenbanken der Nutzen von Big Data Instrumenten erreicht werden kann und ob es eindeutige Indikatoren dafür gibt, ab wann man tatsächlich sinnvollerweise auf Big Data Technologien setzen sollte.
Es muss nicht immer Big Data sein
Grundsätzlich gilt: Mit der Einführung von Big Data Technologien muss auch die IT-Infrastruktur angepasst werden, um die Anwendungen auch optimal betreiben zu können.
Eine solche Anpassung an Big Data Technologie ist vor allem dann notwendig, wenn es darum geht, semistrukturierte oder unstrukturierte Daten zu analysieren. Klassische Technologien wie relationale Datenbanken sind hier durch ihre technischen Restriktionen weniger geeignet, denn mit diesen kann nur auf strukturierten Daten direkt gearbeitet werden.
Liegen allerdings bereits strukturierte Daten vor, muss es nicht zwingend eine Big Data Technologie sein. Hier sollte man zunächst anhand des Anwendungsfalls bewerten, ob eine Optimierung der bestehenden Technologie oder eine Anpassung der Fragestellung ausreichend ist. Möglicherweise genügt eine Ja/Nein Entscheidung anstatt der exakten Berechnung mit feingranularer Wahrscheinlichkeitsrechnung.
3-V Model als Indikator für Big Data
Eine eindeutige Einstufung, ab wann Big Data Technologien eingesetzt werden sollten, existiert nicht. Allerdings ist es anhand des sogenannten 3-V-Modells möglich zu erkennen, ob der Einsatz von Big Data Technologien hilfreich wäre.
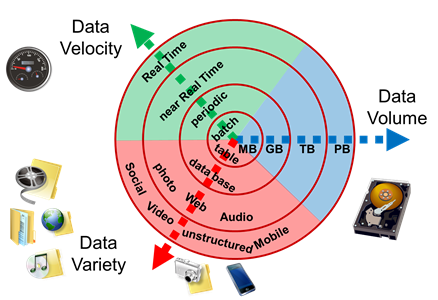
(Quelle: https://gi.de/informatiklexikon/big-data/)
Die Metriken Datenvolumen, -geschwindigkeit und -vielfalt charakterisieren die Anforderungen für einen Anwendungsfall. Je nach Ausprägung der drei Eigenschaften lässt sich abschätzen, ob moderne Technologien eingesetzt werden sollten.
Liegen in mehreren Datenbereichen die höchsten beziehungsweise zweithöchsten Anforderungen vor (äußerster und zweiter Ring von außen), ist der Einsatz moderner Technologien bzw. Big Data sinnvoll. Stellen hingegen nur einzelne Anforderungen in einem Bereich hohe Anforderungen (zum Beispiel „besonders schnell, aber kein hohes Datenvolumen“, oder „sehr hohes Datenvolumen per Batchjobs“), muss jeder Anwendungsfall individuell beurteilt werden, ob sich Big Data Technologien anbieten oder ob es bessert ist, klassische Technologien zu optimieren.
Optimierungsmöglichkeiten von klassischen Technologien
Best Practices um Skalierungspotenziale relationaler Datenbanken auszuschöpfen:
- Grundsätzlich sind die Daten in relationalen Systemen unsortiert, aufgrund dessen kann das Anlegen von Indizes zu schnelleren Zugriffszeiten führen.
- Das Verlagern von Teilrelationen in den Arbeitsspeicher kann zur schnelleren Verarbeitung der Daten führen, da die Daten nicht mehr zwischen Arbeitsspeicher und Festplattenspeicher übertragen werden.
- Das Erstellen von Partitionen und Replikationen führt zu parallelen oder einzelnen Zugriffen auf verschiedene Teilrelationen einer Datenbank. Dadurch ist eine parallele Verarbeitung gewährleistet, oder es werden nur relevante Daten einer Relation zur Analyse verwendet.
- Das Einrichten einer Master-Slave-Architektur orientiert sich am verteilten Datenmanagement, das auch Hadoop verwendet. Dadurch können Datensätze auf unterschiedlichen Servern verteilt und parallele Analysen durchgeführt werden, indem die Last einer Anfrage aufgeteilt wird.
- Für die „Vorverarbeitung“ der Daten und zur späteren Präsentation der Ergebnisse lassen sich materialisierte Sichten verwenden, um Zeit zu sparen.
Fazit:
Big Data Technologien können in vielen Situationen eine Lösung bieten, die ohne diese nicht möglich gewesen wäre. Die Entscheidung zum Einsatz solcher Technologien muss aber gut überlegt sein, denn der Einsatz ist kostspielig und aufwändig. Das 3-V-Modell kann helfen zu entscheiden, ob nicht auch schlankere und damit günstigere Ansätze ebenso zum Ziel führen können.
Co-Autor Bartu Uysal
Mehr zu Datenintegration gibt’s hier
Diese weiteren Blogbeiträge könnten auch interessant sein:
IoT Prozessoptimierung und Big Data (Teil 1)
