
EntityGraphs – Dynamischer Performanceschub bei Datenbankabfragen mit JPA
Die Verwendung von Datenbanken ist in der heutigen Zeit unerlässlich. Die Zahl der Datensätze steigt ständig und die Struktur, in der diese abgespeichert sind, wird immer komplexer. Dadurch benötigen Datenbankabfragen auf zwei Arten stetig mehr Zeit:
- Suchen des geforderten Datensatzes
- Laden der verketteten Struktur in den Arbeitsspeicher
Bevor aus Quellcode auf eine Datenbank zugegriffen werden kann, muss zuerst eine Datenbankanbindung erfolgen. Im Java Umfeld wird hierfür bevorzugt die Spezifikation der Java Persistence API (JPA) verwendet. Implementiert wird diese wiederum von sogenannten Persistence Providern, wie beispielsweise Hibernate oder EclipseLink.
In diesem Beitrag soll beschrieben werden, welche Möglichkeiten es derzeit im Java Umfeld gibt, die Performance bei Datenbankzugriffen mittels JPA zu verbessern. Damit die Funktionsweisen und die Vor- und Nachteile der angeführten Möglichkeiten besser nachvollziehbar sind, werden diese an Hand eines Beispiels verdeutlicht, welches sich durch diesen Beitrag zieht:
Ein Unternehmen hat die Möglichkeit auf seine Kundendaten (Customer), sowie deren Rechnungen (Bills) mit den gekauften Artikeln (Items) aus einer Datenbank zuzugreifen. Außerdem lassen sich die Lieferadressen (Addresses) des Kunden abrufen. Diese Struktur ist in der nachfolgenden Abbildung dargestellt.
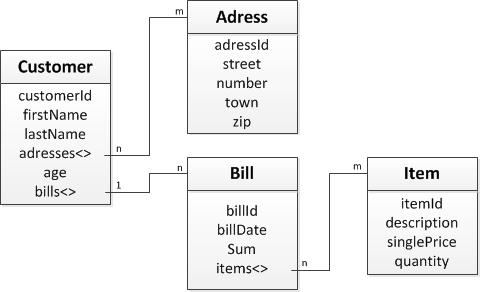
Ohne Optimierung: Ohne den Einsatz von Optimierungen werden bei der Abfrage einzelner Attribute, auch sämtliche andere Objekt-Referenzen mitgeladen. Bezogen auf das Beispiel bedeutet dies: Es soll über eine Kunden-ID die Lieferadresse ermittelt werden. Unnötigerweise werden die Rechnungen und deren Artikel auch angefordert, ohne dass sie benötigt werden.
Fetchtypes: Eine Möglichkeit, mit der die Performance einer Datenbankabfrage verbessert werden kann ist, nicht den kompletten Datensatz, sondern nur Teile davon abzufragen. Um ein selektiveres Laden von Datenbankentitäten zu ermöglichen, wurde in der JPA ein sogenannter „Fetchtype“ eingeführt [Link]. Hierbei werden komplexe Datentypen (Referenzen auf andere Tabellen) mit dem Wert „Fetchtype-LAZY“ versehen. Das hat zur Folge, dass sämtliche Daten, auf die über einen Fremdschlüssel referenziert wird, beim initialen Laden einer Entität vom Persistence Provider nicht mehr aus der Datenbank angefordert werden. Das Fetchtype Attribut wird fest in den Quellcode geschrieben, weshalb es bei jeder künftigen Abfrage gesetzt und nicht mehr dynamisch geändert werden kann.
Im Beispiel mit den Kundendaten wird davon ausgegangen, dass die Werte „Addresses“ und „Items“ auf Fetchtype=LAZY gesetzt wurden, weil diese nur selten benötigt werden. Sollte dennoch auf Attribute dieser Entitäten zugegriffen werden müssen, werden sie vom Persistence Provider automatisch nachgeladen.
An dieser Stelle lässt sich vermuten, dass es optimal wäre, alle Referenzen mit „LAZY“ zu versehen und die benötigten Daten automatisch nachladen zu lassen. Diese Vorgehensweise würde zwar funktionieren, der nachträgliche Ladevorgang benötigt allerdings mehr Zeit, als wenn direkt der geforderte Satz von Daten geladen worden wäre.
Fazit des Fetchtypes: Es kann eine Verbesserung der Performance mit sich bringen, ist allerdings noch zu wenig flexibel.
EntityGraph: Abhlife schaffen sogenannte „EntityGraphs“, welche im April 2013 von der JPA 2.1 erstmals spezifiziert wurden [Link] . Ein EntityGraph ist ein Konstrukt, mit dem es möglich ist, bei jeder Abfrage exakt die Daten anzufordern, die auch tatsächlich benötigt werden. Ein EntityGraph kann auf drei Arten erstellt werden:
- dynamisch über die API
- XML
- Annotationen
Im folgenden Listing wird ein EntityGraph mit dem Namen „GraphWithCustomerAndBills“ über Annotationen definiert. Er fordert speziell Daten aus den Entitäten „Customer“ und „Bill“ an.
@NamedEntityGraph(
name = „GraphWithCustomerAndBills“,
attributeNodes = {
@NamedAttributeNode(„firstName“),
@NamedAttributeNode(value = „bills“, subgraph = „billGraph“)
},
subgraphs = {
@NamedSubgraph(
name = „billGraph“,
attributeNodes = {
@NamedAttributeNode(„sum“)
}
)
}
)
EntityGraphs bauen auf der Strategie der Fetchtype-Definition auf. Dabei ist es möglich, mehrere verschiedene EntityGraphs zu erstellen und jeden einzelnen einer eigenen Abfrage zuzuweisen. Die EntityGraphs können des Weiteren sogar dynamisch zur Laufzeit erzeugt werden, wodurch die Flexibilität nochmals stark zunimmt.
Bezogen auf das obige Beispiel ist es durch den Einsatz von EntityGraphs möglich, auf die Attribute der Tabelle „Address“ ohne einen Nachladevorgang zugreifen zu können. Außerdem müssen die Rechnungsdaten nur mitgeladen werden, wenn sie auch tatsächlich benötigt werden. Bei Benutzung des Fetchtypes wurden diese immer angefordert.
Nachfolgende Tabelle fasst diese Erkenntnisse nochmals zusammen und gibt einen Überblick darüber, wie das Ladeverhalten der Entitäten durch den Einsatz von EntityGraphs optimiert werden kann. Jede Zeile stellt eine Abfrage mit verschiedenen Attributen der Entitäten dar. Die Tabelle trifft eine Aussage darüber, welche Daten effektiv, unter der Verwendung der genannten Möglichkeiten, geladen werden und wie gut diese Ladestrategie in dem beschriebenen Beispiel ist. Dabei kann das Ergebnis drei Farben annehmen:
- Rot: Es wurden neben den geforderten auch unnötige Daten mitgeladen
- Orange: Es mussten Felder nachgeladen werden
- Grün: Es wurden exakt die Daten geladen, die auch benötigt werden

Aus der Tabelle lässt sich feststellen: Ohne den Einsatz von Lade-Optimierungen werden immer alle Daten geladen, was lediglich das gewünschte Ergebnis zur Folge hat, wenn auch alle Daten benötigt werden. In jedem anderen Fall werden unnötige Daten zurückgeliefert, was neben dem Datenüberfluss auch die vermeidbare Auslastung von Ressourcen mit sich bringt.
Bei der Verwendung von Fetchtypes kann speziell eine Verbesserung beim Laden von „Customer“ und „Bill“ erzielt werden. Die orange-markierten Ergebnisse deuten auf ein automatisches Nachladen von Daten hin, was im letzten Fall sogar eine schlechtere Performance ergibt, als wenn alle Daten direkt geladen werden. Fetchtypes sollten in diesem Beispiel verwendet werden, wenn vorher feststeht, dass nur selten alle Daten benötigt werden und stattdessen oft auf Daten von „Customer“ und „Bill“ zugegriffen werden soll.
Betrachtet man die Spalte „EntityGraph“ stellt man fest, dass jedes Ergebnis grün markiert ist. Es ist also möglich, für jede Datenbankabfrage einen eigenen EntityGraph zu erstellen und exakt die Daten zurückzugeben, die angefordert wurden.
Abschließend stellt sich nun die Frage, warum EntityGraphs nicht immer verwendet werden. Die Gründe für diese Frage sind schnell erklärt:
- EntityGraphs sind in der Praxis noch wenig verbreitet; nur wenige Entwickler kennen und verwenden diese auch
- Es gibt wenig Dokumentation über EntityGraphs
- Die Implementierung entspricht teilweise noch nicht 100% der Spezifikation (z.B. folgender Hibernate Defect)
(Unser Thesant Sebastian Wild erarbeitet gerade ein Konzept zum Einsatz von EntityGraphs in mehrschichtigen Businessanwendungen. Ihm vielen Dank für die zusammengetragenen Informationen, die diesen Blogbeitrag ermöglicht haben.)
