Erkennung von Fahrbahnmarkierungen – Teil 2: Bildsegmentierung und wie sie genutzt werden kann
Auf dem Weg zur Erkennung von Fahrbahnmarkierungen werden Convolutional Neural Networks (kurz CNNs) benötigt. Diese wurden im ersten Teil dieser Blogserie vorgestellt. Die Erkennung der Fahrbahnmarkierungen fällt in den Bereich der Bildsegmentierung.
Wie man sich diesen Bereich vorstellen kann und wie CNNs dort verwendet werden, wird in diesem Beitrag gezeigt.
Arten der Bildsegmentierung
Um die Analyse von Bildern zu vereinfachen, werden Bilder im Computer Vision Bereich in verschiedene Segmente geteilt. Bestimmte Objekte, wie Menschen, Autos oder Fahrbahnmarkierungen werden durch eine Menge an Pixeln (=Segmente) repräsentiert. Dabei kann zwischen zwei Segmentierungsarten unterschieden werden.
Semantische Segmentierung
Die Semantische Segmentierung beschreibt die Zuordnung jedes Pixels eines Bildes zu einer bestimmten Klasse. In der folgenden Grafik ist beispielhaft die Einteilung der Pixel eines Bildes in einzelne Klassen dargestellt.

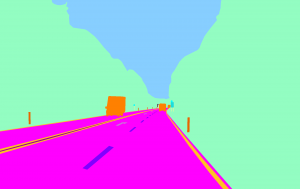
Abbildung 1: Semantische Segmentierung (links: Ausgangsbild, rechts: Bild mit klassifizierten Pixeln).
Instanz Segmentierung
Die Instanz Segmentierung beschreibt die Zuordnung der einzelnen Klassen zu separaten Instanzen. Gibt es beispielsweise mehrere Autos in einem Bild, wird jedes individuelle Auto als eine Instanz eingeordnet, wohingegen semantische Segmentierung alle Autos als eine Instanz einordnet (wie in Abbildung 1 dargestellt).
Das U-Net
Das Verwenden von CNNs ist Standard im Bereich der Bild Segmentierung. Ein klassisches CNN verringert jedoch durch „Pooling Layers“ und „Dense Layers“ die „Wo-Information“ und behält nur die „Was-Information“. Im Falle einer Bild Segmentierung benötigen wir auch die räumliche Information, also die „Wo-Information“. Um die räumliche Information eines klassischen CNNs zu erhöhen, werden unter anderem „fully connected Layers“ durch „convolutional Layers“ ersetzt. Dadurch entsteht ein sogenanntes Fully Convolutional Neural Network (FCN), das Bilder beliebiger Größe akzeptiert. FCNs ist die bevorzugte Architektur bei Segmentierungsproblemen.
Ein sehr bekanntes FCN für Bildsegmentierung ist das U-Net. Es wurde von der Uni Freiburg für die Bildsegmentierung im Bereich der Biomedizin entwickelt. Eine Beispielarchitektur des U-Nets sieht dabei wie folgt aus:
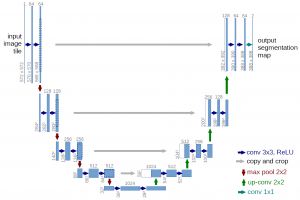
Die Architektur besteht aus einem Encoder und einem Decoder. Der Encoder folgt dem Aufbau eines klassischen CNNs. Hier werden die räumlichen Informationen („Wo“) reduziert, wobei Informationen über bestimmte Eigenschaften, sogenannte „Features“ („Was“) gelernt werden. Der Decoder verbindet die „Was-“ mit der „Wo-Information“ durch Transposed-Convolutions (Gegenteil einer Convolution, auch Up-Convolution genannt) und Verbindungen mit hochauflösenden Features vom Encoder. Die Ausgabe des U-Nets ist ein B×H×N-Tensor aus reellen Zahlen. Es gibt also N Masken für das Originalbild (BxH) zurück, die die Wahrscheinlichkeit vorhersagen, mit der jedes Pixel eine bestimmte Objektklasse repräsentiert.
Segmentierungsspezifische Verlustfunktionen
Im Bereich Bildsegmentierung gibt es verschiedene Verlustfunktionen. Zwei der bekanntesten, die Binary Cross Entropy und der Dice Loss werden im Folgenden genauer betrachtet.
Im Falle einer binären Segmentierung ist die Anwendung der „Binary Cross Entropy“ (BCE) sehr beliebt. Hier wird die Verlustfunktion pro Pixel berechnet. Dabei muss beachtet werden, dass ein Klassen-Ungleichgewicht nicht berücksichtigt wird. Im Fall der Erkennung von Fahrbahnmarkierungen gehört nur etwa 1 Pixel aus 50 zu einer Fahrbahnmarkierung. Das neuronale Netz kann also eine pixelweise berechnete Verlustfunktion bereits stark minimieren, indem sie für jeden Pixel die Wahrscheinlichkeit 0 zurückgibt. Pixelweise berechnete Verlustfunktionen müssen daher gewichtet werden. Der Verlust für Pixel der seltener auftretenden Klasse kann beispielswiese 50-mal so hoch gewichtet werden wie der Verlust eines Pixels der häufig auftretenden Klasse.
Hier wird die Motivation für eine andere Verlustfunktion deutlich: der Dice Loss. Der Dice Loss wird nicht pro Pixel berechnet, sondern berechnet die relative Überlappung der segmentierten Klassen von Vorhersage und realen Werten. Er hat die gleichen Werte für große und kleine Objekte. „Wurde die Hälfte der rechten Straßenbahnmarkierung richtig vorhergesagt? Ja! → Verlust von 0,5.“ Im weiteren Verlauf des Beitrags wird genauer auf die Definition des Dice Koeffizienten eingegangen. Der Dice Loss ist dessen Umkehrung: 0 ist der ideale Wert und 1 der schlechteste.
Segmentierungsspezifische Performance Metriken
Verbreitet ist das Berechnen sogenannter harter Metriken. Dabei werden die zurückgegebenen Wahrscheinlichkeiten eines FCN in ganze Zahlen konvertiert und ein Schwellwert bestimmt, beispielsweise 0,5. Alle Werte unter 0,5 werden dann im Falle eines binären Problems zu 0 (Hintergrundklasse) und alle Werte über 0,5 zu 1 (Vordergrundklasse). Bezogen auf die Erkennung von Fahrbahnmarkierungen würden die Fahrbahnmarkierungen die Vordergrundklasse und alles andere die Hintergrundklasse repräsentieren.
Dieser Schwellwert kann anhand einer bestimmten Metrik optimiert werden. Weiche Metriken werden hingegen basierend auf den Wahrscheinlichkeiten berechnet. Wir fokussieren uns für die Erkennung der Fahrbahnmarkierungen auf die harten Metriken. Der konkrete Anwendungsfall wird im dritten und letzten Teil der Blogserie näher betrachtet.
Klassische Performance Metriken wie die Genauigkeit (=Accuracy) können im Rahmen der Segmentierung irreführend sein. Sollten beispielsweise nur 5 Prozent der Pixel Teil einer Fahrbahnmarkierung sein und es werden nur Hintergrundpixel vorhergesagt, würde die Genauigkeit 0,95 betragen, da 95 Prozent der Pixel korrekt segmentiert wurden. In Wirklichkeit wurde jedoch kein Vordergrundpixel richtig eingeordnet. Das muss auch die Performance Metrik widerspiegeln. Bekannte Segmentierungs-Performance Metriken, die dieses Problem minimieren, sind der Intersection-Over-Union (kurz IoU) und der Dice Koeffizient.
Intersection-Over-Union (IoU, Jaccard Index)
Der IoU bildet sich aus der Fläche des Überlappungsbereichs zwischen der vorhergesagten Segmentierung und der echten Segmentierung, geteilt durch deren Vereinigung (wie in folgender Abbildung dargestellt).
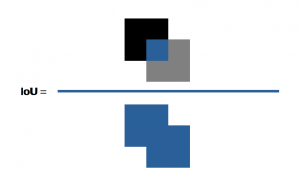
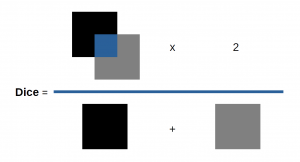
Dice Coefficient (F1 Score)
Der Dice Score bildet sich aus dem Überlappungsbereich zwischen der vorhergesagten Segmentierung und der echten Segmentierung mal zwei, geteilt durch die gesamte Anzahl an Pixeln beider Bilder.
Der IoU Score und der Dice Score werden pro Klasse berechnet und schließlich gemittelt. Beide Metriken reichen von 0 (schlechtestes Ergebnis) bis 1 (bestes Ergebnis). Sie sind sehr ähnlich und positiv korreliert, werden jedoch unabhängig verwendet.
Mithilfe der speziellen Metriken für die Bildsegmentierung können wir die Ergebnisse unseres Anwendungsfalles bei der Fahrbahnmarkierung auswerten. Dieser wird im dritten und letzten Teil dieser Blogserie vorgestellt.
Fazit
Bei der Bildsegmentierung gibt es einige Faktoren zu berücksichtigen – und auch ihre Unterschiede und Schwachstellen zu kennen. Wir haben einen Blick auf die semantischen Segmentierung und die Instanz Segmentierung geworfen und deren Unterschiede beleuchtet. Dafür wurde das U-Net als bekannte CNN Architektur im Bereich der Bildsegmentierung vorgestellt. Um Ergebnisse im Bereich der Bildsegmentierung bewerten zu können, werden spezielle Metriken, wie etwa Intersection-Over-Union (IoU) oder der Dice Koeffizient genutzt. Das Wissen aus Teil 1 zu den Convolutional Neural Networks und diesem Beitrag bieten die Basis für die Erkennung von Fahrbahnmarkierungen auf Bildern. Diese stellen wir im nächsten Teil dieser Reihe genauer vor.
Co-Autor: Nils Boerner
Mehr rund um das autonome Fahren gibt’s hier
Quellen:
1 https://ilmonteux.github.io/2019/05/10/segmentation-metrics.html, Zugriffsdatum: 23.12.2020
2 https://missinglink.ai/guides/computer-vision/image-segmentation-deep-learning-methods-applications/, Zugriffsdatum: 23.12.2020
