Erkennung von Fahrbahnmarkierungen – Teil 3: Der Showcase
Auf Basis der Grundlagen von Convolutional Neural Networks (im ersten Teil der Beitragsserie) und dem wesentlichen Verständnis der Bildsegmentierung (aus dem zweiten Teil der Beitragsserie) wurde ein Modell trainiert,
welches in der Lage ist, Fahrbahnmarkierungen auf Bildern zu erkennen und diese zu markieren. Im dritten und letzten Teil der Blogserie soll dabei genauer auf dieses Modell und die damit erzielten Ergebnisse eingegangen werden.
Die Datenbasis – Das Herzstück unseres Modells
Zur Erstellung guter Machine Learning Modelle werden Daten benötigt. Diese Daten müssen sowohl frei verfügbar sein, sowie einen großen Umfang besitzen, um ein Overfitting des Modells zu verhindern. Für unseren Anwendungsfall nutzen wir den A2D2 Datensatz von Audi. Dieser Datensatz erfüllt unsere Bedingungen in Sachen Umfang und Lizenzierung. Durch die Creative Commons Attribution-NoDerivatives 4.0 International License wird auch die kommerzielle Nutzung des Datensatzes erlaubt. Der von uns verwendete Semantic segmentation Datensatz umfasst 41.280 Bilder mit insgesamt 38 verschiedenen Objektkategorien, die auf den Bildern markiert wurden. Die Bilder wurden von Audi in Gaimersheim, Ingolstadt und München aufgenommen. Die folgende Abbildung gibt einen Überblick über die 38 vorhandenen Objektkategorien, sowie deren Häufigkeit (in Pixel).
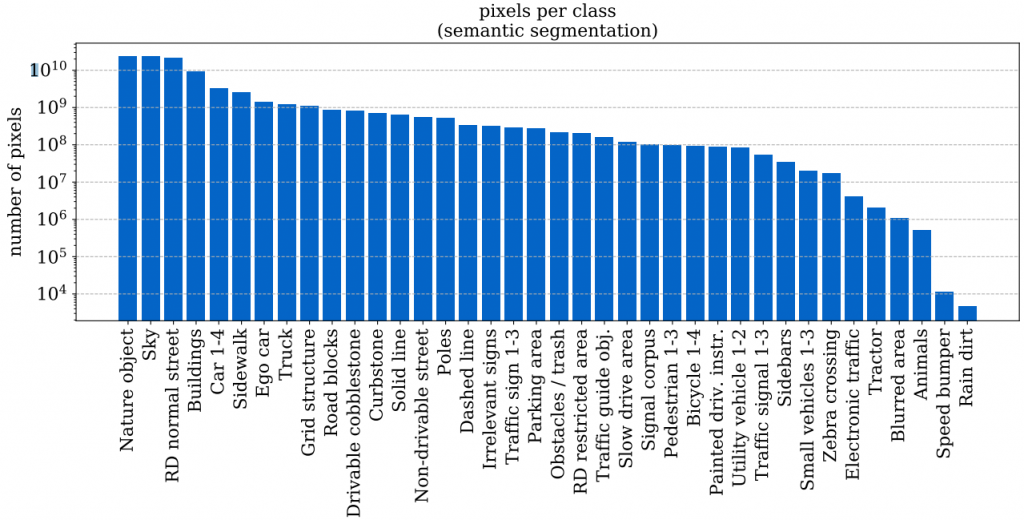
Abbildung 1: Klassenverteilung im A2D2 Datensatz. (Quelle: https://www.a2d2.audi/content/dam/a2d2/dataset/a2d2-audi-autonomous-driving-dataset.pdf)
Die Vorverarbeitung der Bilder – die Bildgröße ist entscheidend
Unser Modell wurde mit dem Open-Source Framework TensorFlow erstellt. Trainiert wurde auf einem Rechner mit 6 CPU Kernen, sowie 20 GB RAM. Für das Training des Modells sind neben der Erstellung der Segmentierungsmasken für die Bilder im Datensatz auch einige Vorverarbeitungsschritte der Bilder nötig. Diese werden nachfolgend genauer erklärt.
Segmentierungsmasken
Ein neuronales Netz benötigt für das Erlernen einer Bildsegmentierung neben dem eigentlichen Bild eine sogenannte Segmentierungsmaske. Eine Segmentierungsmaske weist jedem Pixel eine Klasse zu. In unserem Fall handelt es sich um eine binäre Segmentierung. Es muss also zwischen den Vordergrundpixeln (= Pixel der Fahrbahnmarkierung) und Hintergrundpixeln (= alle anderen Pixel, die nicht zur Fahrbahnmarkierung gehören) unterschieden werden. Jedem Pixel, der zur Fahrbahnmarkierung gehört, wird der Wert 1 zugewiesen, allen anderen der Wert 0. Der Datensatz enthält bereits für jedes Bild eine Segmentierungsmaske. Diese sind jedoch mit 38 enthaltenen Klassen zu umfangreich für unser Problem. Daher haben wir alle Klassen, die zu Fahrbahnmarkierungen gehören, gruppiert und diesen den Wert 1 zugewiesen. Alle anderen Klassen werden ignoriert bzw. mit dem Wert 0 definiert. Die Erstellung dieser Segmentierungsmasken wird vor dem eigentlichen Training auf allen Bildern durchgeführt. Hier ein Beispiel der Umwandlung einer Segmentierungsmaske aus dem originalen Datensatz zu einer binären Maske für unseren Anwendungsfall:
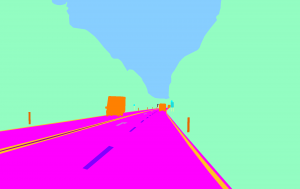

Abbildung 2: Umwandlung der originalen Segmentierungsmaske (links) zu einer binären Segmentierungsmaske (rechts) durch Gruppierung der Klassen
Vorverarbeitung
Aufgrund der Limitierung unserer Hardware wurden die Bilder nicht in der originalen Auflösung von 1920×1208 Pixeln genutzt. Einzig die Erstellung der Segmentierungsmasken (siehe vorheriger Abschnitt) wurde auf der originalen Auflösung durchgeführt. Die Bilder wurden, von der Mitte ausgehend, zunächst auf eine Größe von 1208×1208 Pixeln zugeschnitten, um eine Stauchung oder Streckung des Bildes bei der Umwandlung in ein quadratisches Format zu verhindern. Danach wurden die Bilder auf eine endgültige Größe von 256×256 Pixel herunterskaliert. Prinzipiell unterliegt die Wahl der Bildgröße nur einer Einschränkung unseres verwendeten Modells (des U-Nets): Die Höhe, sowie die Breite müssen durch 32 teilbar sein. Für die Größe von 256×256 haben wir uns nach einigen Experimenten entschieden, da mit dieser Größe sowohl die Ergebnisse gut waren, als auch die Trainingsdauer des Modells in einem akzeptablen Rahmen blieb.
Das Modell
Für die Auswahl des richtigen Modells haben wir die Python Bibliothek segmentation_models genutzt. Diese erlaubt den flexiblen Tausch von verschiedenen Modellen, Verlustfunktionen und Metriken für die Bildsegmentierung. Nach dem Testen verschiedener Modelle, unter anderem dem DeepLabv31, dem PSPNet2 und dem U-Net, haben wir uns für das U-Net als Modell entschieden. Dieses zeigte in Kombination mit unserer eingesetzten Hardware die beste Performance. Als Verlustfunktion haben wir den BCE-Loss ausgewählt, nachdem wir diesen mit dem Dice-Loss verglichen hatten. Dieser lieferte für unseren Anwendungsfall die besseren Ergebnisse.
Hyperparameter
Die Hyperparameter des Modells haben wir nach einigen Experimenten wie folgt eingestellt: Die Lernrate wurde mit 0,001 eingestellt. Zusätzlich nutzen wir einen Learning Rate Scheduler. Dieser sorgt dafür, dass sich die Lernrate um 0,1 verringert, sollte sich der Wert der Verlustfunktion für 5 Epochen nicht verringern. Das würde bedeuten, dass unsere Verlustfunktion unter Umständen in einem lokalen Minimum feststeckt. Durch die Verringerung der Lernrate könnte dieses lokale Minimum überwunden werden. Als Batchgröße hat sich für unsere verfügbare Hardware eine Größe von 16 als gut herausgestellt. Die Anzahl der Epochen wurde von uns nicht fest definiert. Stattdessen wird der sogenannte Early Stopping Callback von Keras genutzt. Dieser beendet das Training, falls sich der Wert der Verlustfunktion auf den Validierungsdaten für 15 Epochen nicht ändert. Das Stoppen des Trainings soll die Gefahr von Overfitting reduzieren.
Ergebnis
Für unser bestes Modell nutzen wir insgesamt 10.000 Bilder des Datensatzes. Diese wurden unterteilt in 7.000 Trainings-, 1.500 Validierungs- und 1.500 Testbilder. Auf diesen Daten erzielt unser Modell einen IoU-Score von ~75 Prozent und einen Dice-Score von ~85 Prozent. Der Verlauf der Verlustfunktion wird in folgendem Bild dargestellt:
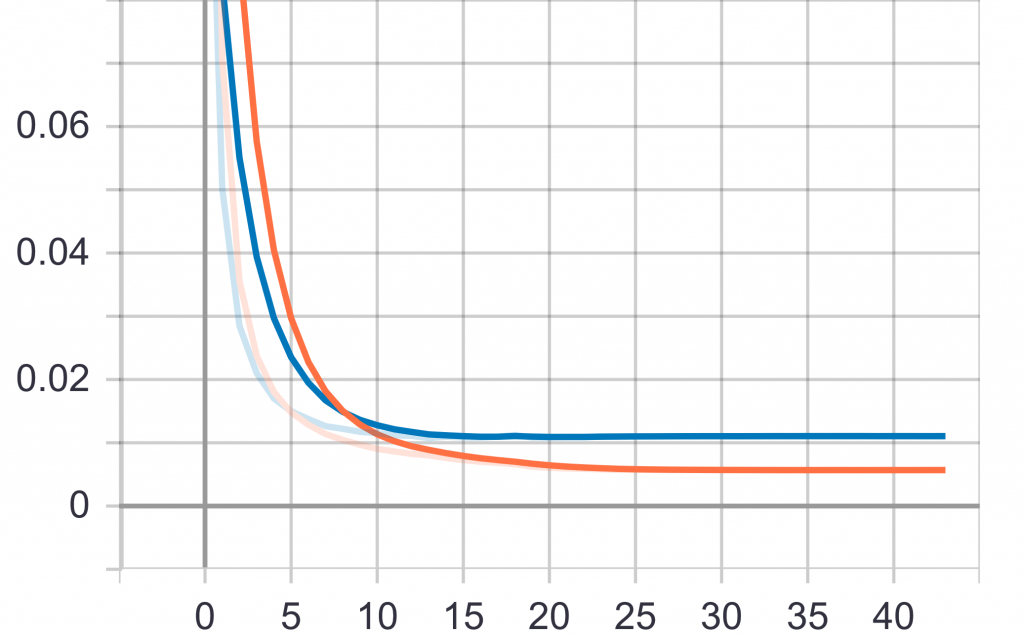
Abbildung 3: Verlauf der Verlustfunktion unseres Modells während des Trainings. Gezeigt wird der Verlauf für die Trainings- und die Validierungsdaten. Die x-Achse zeigt hierbei die Anzahl der Epochen des Trainings, die y-Achse den Wert der Verlustfunktion.
Ein direkter Vergleich mit den Ergebnissen des Modells von Audi kann und soll hier nicht durchgeführt werden. Audi hat eine Segmentierung von insgesamt 19 verschiedenen Klassen durchgeführt. Daher ist die Komplexität der beiden Modelle nicht vergleichbar. Für unseren Anwendungsfall ist das Ergebnis aber sehr gut. Da Bilder mehr als Worte sagen, haben wir hier noch ein paar Beispielbilder unseres Modells zusammengestellt. Die etwas verpixelte Qualität der Bilder ist unserer skalierten Auflösung von 256×256 Pixeln zu schulden.



Abbildung 4: Beispiele der Erkennung der Fahrbahnmarkierungen mit unserem Modell. Links jeweils das Originalbild, rechts das Originalbild mit einer Überlagerung der erkannten Markierungen.
Herausforderungen beim Erkennen von Fahrbahnmarkierungen im Modell
Trotz der guten Ergebnisse hat unser Modell natürlich auch Schwächen. Diese Schwächen haben wir uns genauer angesehen und verschiedene Szenarien identifiziert, in denen unser Modell noch Probleme hat.
- Spiegelungen: Treten Spiegelungen auf dem Straßenbelag auf, beispielsweise Pfützen, Ölstreifen oder ähnliches, werden diese manchmal fälschlicherweise als Fahrbahnmarkierung erkannt.
- Wechselnde Lichtverhältnisse: Teilweise hat unser Modell bei wechselnden Lichtverhältnissen, also bei Vorhandensein von sehr hellen und sehr schattigen Gebieten auf einem Bild, Probleme.
- Schlechte Markierungen: Fahrbahnmarkierungen, die bereits älter und daher schon sehr ausgebleicht sind, werden vom Modell schlecht erkannt.
Wir haben mit unserem Modell gezeigt, dass selbst mit überschaubarem Hardwareeinsatz, in unserem Fall mit 6 CPU Kernen und 20 GB RAM, ein gutes Modell für die Erkennung von Fahrbahnmarkierungen erstellt werden kann. Die Auswahl eines geeigneten Modells kann mit verschiedenen Bibliotheken, wie etwa segmentation_models für die Bildsegmentierung, vereinfacht werden. Auch helfen andere Bibliotheken, typische Probleme, wie etwa das Overfitting, zu vermeiden. Das kann etwa durch den von uns eingesetzten Early Stopping Callback durch eine frühzeitige Beendigung des Trainings bei unveränderten Werten der Verlustfunktion geschehen. Natürlich ist unser Modell nicht perfekt und hat noch Schwächen. Diese haben wir systematisch in Kategorien einteilen können, um sie in Zukunft noch gezielter beheben zu können. Unser entwickeltes Modell bietet eine solide Grundlage für zukünftige Erweiterungen. So kann durch den Einsatz von Grafikkarten (GPU) mit mehr Rechenleistung auch eine Erkennung auf Videodateien umgesetzt werden. Auch ist es denkbar, unsere Segmentierung auf weitere, im Datensatz enthaltene, Klassen wie etwa Menschen oder Fahrzeuge auszuweiten.
Co-Autor: Nils Boerner
Quellen:
1 https://arxiv.org/pdf/1706.05587.pdf, besucht am 13.02.2021 ^
2 https://arxiv.org/pdf/1612.01105.pdf, besucht am 13.02.2021 ^

Hallo Herr Klein,
es freut mich, dass Ihnen der Artikel gefällt. Danke auch für die Anfrage, ob der Code auch anderweitig nutzbar ist.
Im Code selbst sind neben dem eigentlichen Modell auch firmeninterne Dinge enthalten. Aus diesem Grund haben wir uns bewusst dagegen entschieden den Code als Open-Source Code frei verfügbar zu machen. Daher können wir Ihnen den Code leider nicht für Ihre Projektarbeit zur Verfügung stellen.
Mit freundlichen Grüßen,
Stefan Träger
Guten Tag Herr Träger,
vielen Dank für Ihren sehr guten Blogbeitrag. Ich selber studiere Computational Engineering Science an der RWTH Aachen und schreibe grade meine Projektarbeit zu dem Thema Machine Learning Ansätze zur kamerabasierten Erkennung von Fahrstreifenmakierung. In der Arbeit soll ich verschiedene Open Source Netzwerke trainieren und miteinander vergleichen. Gibt es die Möglichkeit ihren Code für meine Arbeit zu benutzen?
Vielen Dank!
Mit freundlichen Grüßen,
Florian Klein