Gestenerkennung mit Hilfe von Convolutional Neural Network (CNN)
In unserem Beitrag „Was sind künstliche Neuronale Netze: Ein praktischer Einstieg“ sind wir bereits auf die Grundlagen zu künstlichen neuronalen Netzwerken eingegangen. In der dort vorgestellten Demoanwendung zur Erkennung von Handgesten wurde ein relativ simples Feed Forward Netz verwendet, welches in der Handhabung für den Nutzer aber mit einigen Regeln verbunden ist.
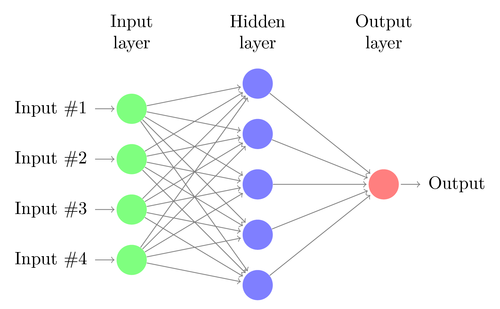
- Die zu klassifizierenden Bilder müssen quadratisch auf die Hand im Zentrum zugeschnitten sein.
- Der Hintergrund musste einfarbig sein und einen entsprechend hohen Kontrast zur Hautfarbe wiederspiegeln (z.B. eine weiße Wand im Hintergrund).
- Es musste sich immer um eine rechte Hand handeln, die von unten gerade ins Bild ragt und die Fingerzahl auf die im Trainingsdatensatz präsentierte Art und Weise darstellt.
Wurden diese Regeln eingehalten, dann konnten wir auf neuen Testdaten, die wir bei uns aufgenommen haben, eine Genauigkeit von etwas über 90 Prozent erreichen. Das ist ein sehr gutes Ergebnis, dafür dass hier ein einfaches künstliches neuronales Netzwerk mit zwei relativ kleinen versteckten Ebenen verwendet wurde.
In diesem Artikel möchte ich zeigen, mit welchen Ansätzen es gelungen ist unser Modell:
- zu verbessern, also eine höhere Genauigkeit zu erzielen und
- zu verallgemeinern, also möglichst beide Hände in verschiedenen Positionen, mit weiterem Bilderausschnitt und beliebigem Hintergrund klassifizieren zu können.
Hier geht´s direkt zum Demomodell
Austausch der verwendeten Architektur: Convolutional Neural Network (CNN)
Im letzten Jahrzehnt hatten Convolutional Neural Networks (CNN) – also faltbare neuronale Netzwerke – ihren Durchbruch bei vielen Klassifizierungsaufgaben mit Bild- und Audiodaten und konnten sich für diese als State-of-the-Art-Methode etablieren.
Ein CNN setzt sich aus mehreren Bausteinen zusammen:
- Filter, die als Convolutional Layer bezeichnet werden
- Aggregations-Schichten, die als Pooling Layer bezeichnet werden und
- klassische Neuronale Netze, die als Dense oder Fully Connected Layer bezeichnet werden.
Dabei wiederholen sich sich Convolutional (1.) und Pooling (2.) Layer abwechselnd und werden dann von einer oder mehrerer Schichten Dense/Fully Connected (3.) am Ende abgeschlossen.

Die Convolutional Layer repräsentieren die Vorverarbeitung der Eingabedaten und filtern bestimmte Eigenschaften des Bildes wie z.B. Kanten, bestimmte Flächen, Farben oder Strukturen. Hierzu tastet ein Filter (auch als Sliding Window bezeichnet), fester Größe (z.B. 3 x 3 Pixel) über das Eingabebild. Dieser Filter versucht dabei den Input auf gewisse Eigenschaften zu reduzieren. Über die Nutzung mehrerer Filter, können nun unterschiedliche Eigenschaften herausgefiltert werden.
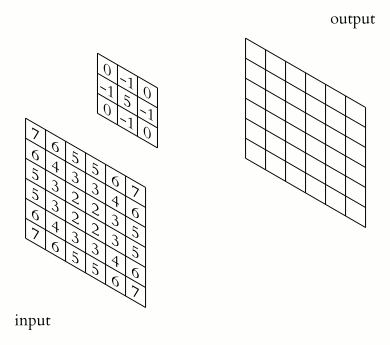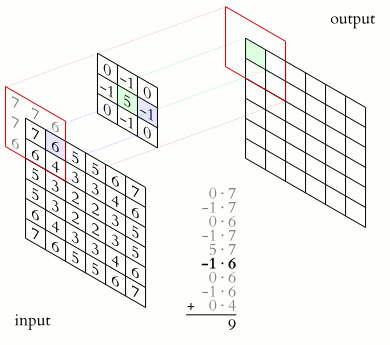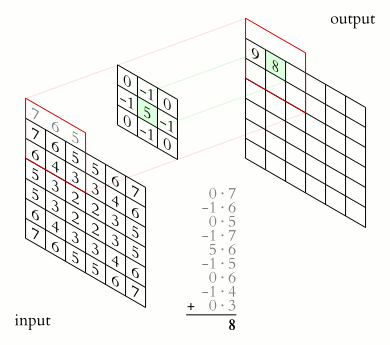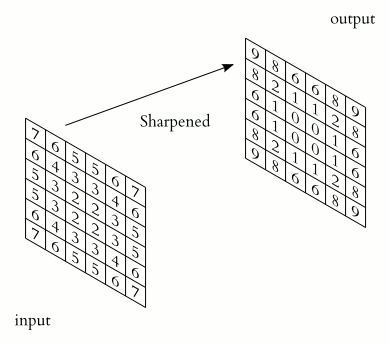
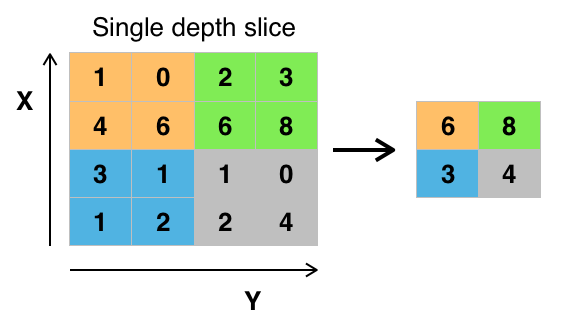
Da jeder Filter jedoch ein eigenes, verändertes Bild erzeugt, erhöht sich die zu verarbeitende Datenmenge mit jeder weiteren Convolutional Ebene im CNN deutlich. Daher versucht man die Daten mit Hilfe von Pooling Layern zu verdichten. Hierzu werden mehrere Pixel zu einem reduziert, z.B. indem eine 4 x 4 Pixel Matrix auf ein Pixel reduziert wird, indem man aus dieser Matrix den Maximalwert herauszieht.
Angelehnt ist dieses zweistufige Vorgehen an das Verhalten des visuellen Cortex des Menschen, der für die visuelle Wahrnehmung zuständig ist.
Anschaulich lässt sich das zum Beispiel am Training mit Gesichtern visualisieren:

Ein weiteres, sehr plastisches Beispiel ist hier zu finden.
Implementierung des Convolutional Neuronal Network mit dem Framework Keras
Zur Implementierung des CNNs wurde Keras genutzt. Keras ist eine high-level API für Tensorflow. Sie erlaubt schnelles Experimentieren mit verschiedenen Netzwerkkonfigurationen und liefert einige Features zur abstrahierten Datenvorverarbeitung.
Schließlich entschieden wir uns für ein CNN mit vier Convolutional-Ebenen mit jeweils 32, 64, 128 und 128 Filtern, gefolgt von einem neuronalen Netzwerk mit 512 Neuronen. Mit dieser Konfiguration konnten wir die Genauigkeit auf über 95 Prozent anheben.
Vergrößern des Trainingsdatensatzes für das Convolutional Neural Network
Schließlich widmeten wir uns der Verallgemeinerung des Modells. Um dies zu tun, benötigen wir vor allem eines: Daten, Daten, Daten.
Im ersten Schritt haben wir also weitere Daten gesammelt. Das geschah über einen weiteren Datensatz (senz3d) und durch Bilder, die wir selbst aufgenommen haben. Die auf diese Weise hinzugefügten Bilder enthielten keinen einfarbigen ruhigen Hintergrund mehr und zeigten beide Hände. Sie waren auch nicht unbedingt groß oder zentriert sondern in verschiedenen Positionen abgebildet. Außerdem waren sie nicht mehr nur quadratisch.


Mit diesem Vorgehen vergrößerten wir den Datensatz von etwa 1000 Bildern auf rund 4000 Bilder. Da diese Anzahl jedoch weiterhin unter dem typischen Minimum zum Training tiefer neuronaler Netzwerke liegt, bedienten wir uns darüber hinaus der Image Augmentation, die Keras mitliefert. Darunter versteht man in diesem Kontext die künstliche Vervielfältigung der Daten mit leichten Abwandlungen, bzw. die künstliche Erzeugung neuer Daten.
Somit lässt sich beispielsweise durch spiegeln aus einer rechten eine linke Hand produzieren oder durch rotieren, reinzoomen, zuschneiden und verzerren verschiedene Aufnahmewinkel simulieren.
All dies führt dazu, dass viele neue Bilder generiert werden mit jeweils leichten Abwandlungen. Jedes dieser künstlich erzeugten Bilder ist dennoch für das Training des CNN geeignet, da es jeweils eine neue Situation abbildet (linke Hand, rechte Hand, Winkel der Hand,…) und dadurch hilft die Genauigkeit des trainierten Modells zu verbessern.
Auf einem weiteren selbstgesammelten Testdatensatz mit mäßiger Schwierigkeit (relativ ruhiger, aber nicht einfarbiger Hintergrund, Hand zentriert von unten ins Bild, …) ließ sich so die Genauigkeit von knapp 30 Prozent mit der alten Architektur auf über 85 Prozent steigern.
Da die Daten durch diese Erweiterung nicht mehr „so sauber“ waren wie der originale Datensatz und das Netzwerk mit dieser Methode selbst die Hände in den Bildern finden, als solche erkennen und klassifizieren muss, ist das Ergebnis sehr zufriedenstellend.
Das so trainierte Modell ersetzt inzwischen die vorherige Demoversion und kann hier getestet werden:
Für die Verbesserung der Gestenerkennung in unserer Demoversion haben wir eine spezielle Art künstlicher neuronaler Netze, sogenannte Convolutional Neural Networks eingesetzt, die ihre besondere Stärke in der Verarbeitung von Bild- und Audiodaten haben. Gleichzeitig haben wir die Anzahl der Trainingsdatensätze stark erhöht. Beides hat dazu geführt, dass wir eine große Verbesserung in der Qualität der Gestenerkennung erreichen konnten. Nun ist es mit der Anwendung auch möglich, Handzeichen in komplexeren Situationen korrekt zu klassifizieren.
Mehr zu neuronalen Netzen erfahren

{kind=link}
{kind=link}
{kind=link}