
IoT Prozessoptimierung und Big Data (Teil 1)
 Jede Firma ist bestrebt ihre Geschäftsprozesse so schlank und effizient wie möglich zu gestalten. Genauso ist jedes Unternehmen heutzutage daran gewöhnt, mit großen Datenmengen umzugehen. Und vernetzt ist inzwischen sowieso alles und jeder. Hierzu muss man nur mal kurz das eigene Handy aus der Hosentasche nehmen und die letzten 50 E-Mails checken.
Jede Firma ist bestrebt ihre Geschäftsprozesse so schlank und effizient wie möglich zu gestalten. Genauso ist jedes Unternehmen heutzutage daran gewöhnt, mit großen Datenmengen umzugehen. Und vernetzt ist inzwischen sowieso alles und jeder. Hierzu muss man nur mal kurz das eigene Handy aus der Hosentasche nehmen und die letzten 50 E-Mails checken.
Kein Wunder also, dass Buzzwords wie das Internet der Dinge oder Geschäftsprozessoptimierung in aller Munde sind. Doch was steckt wirklich dahinter? Wo fängt Big Data eigentlich an? Und noch viel wichtiger: Was haben all diese Themenfelder überhaupt miteinander zu tun? Mit diesen Fragen soll sich diese Blogserie beschäftigen. Der Schwerpunkt in diesem Beitrag liegt auf einer Einführung zu Big Data. In Teil zwei wird dann erläutert, wie der Reifegrad von IoT Geschäftsprozessen mit dem Thema Big Data zusammenhängt. Der dritte Teil dieser Blogserie erläutert diesen Zusammenhang abschließend an einem ganz konkreten Anwendungsfall.
Der Ursprung von Big Data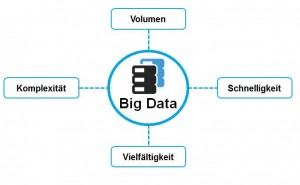
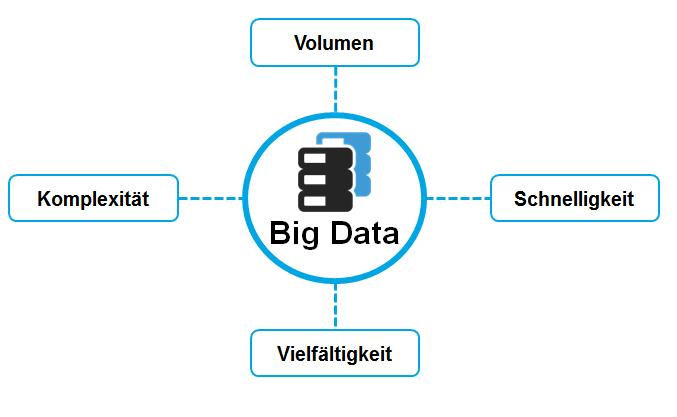
Je nach Quelle erhält man unterschiedliche Aussagen dazu was Big Data ist. Im Wesentlichen beschreibt dieser Begriff Massendaten, die in einem extrem hohen Volumen auftreten. Gleichzeitig sind sie sehr komplex und uneinheitlich und müssen dazu auch noch in kürzester Zeit verarbeitet werden. Ein anschauliches Beispiel hierzu wäre ein System, dass in Real Time Audio-, Video- und Textdateien aus einer Vielzahl von unterschiedlichen Quellen verarbeiten und analysieren muss.
Der eine oder andere denkt jetzt vielleicht: „Ja, aber große Datenmengen effizient zu verarbeiten ist kein neues Thema. Diese Problemstellung gibt es schon so lange wie es Computer gibt.“ Das ist korrekt. Trotzdem ist das Themenfeld Big Data anders. Um das besser zu verstehen, muss man einen kurzen Blick auf die Entstehungsgeschichte dieses Begriffs werfen.
Ganz am Anfang dieser Entwicklung standen bis etwa in die 70er Jahre Flat Files: Datendateien ohne einheitliche Beschreibung oder Struktur. Eine ganz wesentliche Weiterentwicklung fand dann durch die Entstehung von relationalen Datenbanken statt, die bis heute in vielen Bereichen einen de facto Standard darstellen. Mit SQL und dem Entity Relationship Model konnten diese entsprechend modelliert und bearbeitet werden. In diesem Umfeld entwickelten sich auch weitere Datenbankmodelle, wie beispielsweise objekt- oder graphenorientierte Datenbanken. Mit dem Boom von PCs und des Internets sowie mit der Verbreitung von Content-Management- oder ERP Systemen nahmen auch die Datenmengen rapide zu. Um diese besser zu beherrschen, entwickelte man beispielsweise Data Warehouses und Data Marts um Daten effizient zu managen. Die Entstehung des Web 2.0 brachte auch ein wachsendes Volumen an Videos, Musik und Bildern mit sich und stellte eine weitere Herausforderung dar, wodurch Themen wie Virtualisierung und Cloud Computing immer mehr in den Fokus gerieten.
Ist Big Data nun also wirklich neu oder doch nur eine Weiterentwicklung bestehender Technologien?
Die Antwort darauf ist: Es ist beides. Denn viele Ansätze aus dem Big Data Umfeld, wie z.B. nicht relationale Datenbanken, existieren schon seit geraumer Zeit. Die bestehenden Ansätze allein sind aber nicht zielführend, wenn es beispielsweise darum geht mehrere Petabyte an Daten auf eine bestimmte Problemstellung hin auszuwerten (den teuren Einsatz von Großrechnersystemen mal außen vor gelassen).
Neu ist nun, dass beispielsweise Speicher und CPU extrem günstig geworden sind. Auch der Reifegrad vieler Technologien – Stichwort Virtualisierung und Cloud Computing – hat sich wesentlich weiterentwickelt. Somit ist es nun so einfach wie nie, Infrastrukturen(aaS), Plattformen(aaS) und Software(aaS) nahezu beliebig zu skalieren. Und genau hier setzen, ebenfalls neue, Frameworks wie beispielsweise Hadoop gezielt an. Sie ermöglichen es durch einen gezielten Einsatz bestehender und neuer Technologien/Algorithmen riesige Datenmengen auf Computerclustern effizient zu verarbeiten und zu analysieren.
Dies hat in der Konsequenz natürlich unterschiedliche Auswirkungen auf die Geschäftsmodelle von Unternehmen. Umso mehr, wenn sich ein Unternehmen mit Vernetzung und IoT beschäftigt. Der zweite Teil dieser Blogserie wird darum näher darauf eingehen und erläutern, wie genau der Zusammenhang zwischen dem Reifegrad von IoT Geschäftsprozessen und Big Data ist.
Im zweiten Teil dieser Blogserie soll der Zusammenhang zwischen Big Data und dem Reifegrad von IoT Geschäftsprozessen erläutert werden.
Für alle die weiter in das Thema Big Data abtauchen möchten und Ihr Wissen zu bestimmten Technologien aus diesem Umfeld vertiefen wollen, bietet doubleSlash einen sehr spannenden und interessanten Big-Data-Workshop an.
Mehr zu IoT-Services und Connected Products erfahren Sie hier
