IoT Prozessoptimierung und Big Data (Teil 2)
Im ersten Teil dieser Blogserie habe ich den Begriff Big Data sowie dessen Ursprung und Entwicklungsgeschichte erläutert. In diesem zweiten Teil soll der Zusammenhang zwischen Big Data und dem Reifegrad von IoT Geschäftsprozessen erläutert werden.
habe ich den Begriff Big Data sowie dessen Ursprung und Entwicklungsgeschichte erläutert. In diesem zweiten Teil soll der Zusammenhang zwischen Big Data und dem Reifegrad von IoT Geschäftsprozessen erläutert werden.
In Beratungsgesprächen und Workshops mit Kunden nutzen wir bei doubleSlash ein einfaches Reifegradmodell. Das Modell zeigt auf, wie weit ein Unternehmen in Bezug auf seine IoT Geschäftsprozesse bereits entwickelt ist.
In der ersten Phase CONNECT steht die Vernetzung im Vordergrund. In vielen Kundenszenarien sind die übermittelten Datenmengen auf ein einzelnes Endgerät bezogen relativ klein. Allerdings hat man es im Internet der Dinge in der Regel mit einer Vielzahl an Endpunkten zu tun. Daraus entstehen dann in der Summe sehr schnell sehr große Datenvolumina. Grundsätzlich gilt dabei, dass größere Datenmengen natürlich auch höhere Kosten, z.B. für die Netzinfrastruktur, zur Folge haben. Daher ist es wichtig, nur möglichst geringe Datenmengen zu „produzieren“ und diese so effizient wie möglich zu übertragen. Das erreicht man unter anderen durch möglichst schlanke Datenformate (z.B. JSON) und Protokolle (z.B. MQTT oder CoAP), aber auch durch ein, auf IoT zugeschnittenes, Design der Geschäftsprozesse.
Mit der richtigen Datenverarbeitung zum IoT Servicelevel
Sobald man beginnt die neu gewonnen Informationen in die unternehmensinternen Geschäftsprozesse zu integrieren, befindet man sich im Reifegradmodell in der zweiten Stufe SERVICE. In dieser Stufe sollen die Daten für einen mehrwertstiftenden Service bzw. ein Geschäftsmodell nutzbar gemacht werden. Hierzu muss eine Vielzahl von für sich genommen großen Datentöpfen zu einem großen Pool zusammengeführt werden. Ein Beispiel hierzu wäre die Integration eines ERP-Systems, eines CMS-Systems, verschiedenen externen Content Providern wie Google oder Yahoo und dann eben noch den jeweiligen IoT Daten. Da diese Daten in der Regel in kürzester Zeit zur Verfügung stehen müssen, ist es unverzichtbar eine effiziente Datenverarbeitung sicherzustellen. Eine Möglichkeit (neben dem Einsatz von sehr kostspieligen Großrechnersystemen) ist der Einsatz von verteilten Datenbanken. Man versucht also die steigenden Datenmengen mit zusätzlicher Hardware zu erschlagen. Herkömmliche relationale Datenbanksysteme (RDBMS) stoßen hier schnell an ihre Grenzen. RDBMs müssen zu jedem Zeitpunkt die Konsistenz aller Daten garantieren. Das ist aufgrund des ACID-Prinzips (Atomicity, Consistency, Isolation, Durability) so, denen RDBMS unterlegen sind. Dies hat zur Folge, dass mit steigender Zahl von Knoten immer mehr Daten repliziert und konsistent gehalten werden müssen. Kurzum: die Datenbank wird immer langsamer und geht in die Knie.
An dieser Stelle setzen NoSQL (Not Only SQL) Datenbanken, wie z.B. MongoDB an. Sie verzichten darauf, zu jedem Zeitpunkt eine vollständige Datenkonsistenz auf allen angebundenen Knoten zu garantieren. Stattdessen gehen sie davon aus, dass es genügt die Konsistenz der Daten irgendwann, zu einem späteren Zeitpunkt, herzustellen. In der Folge können diese Datenbanken bei sehr großen Datenmengen deutlich besser skalieren und gleichzeitig noch performant arbeiten. Der Vollständigkeit halber sei erwähnt, dass es aufgrund des CAP Theorem nicht möglich ist, Systemverfügbarkeit, Datenkonsistenz und Ausfalltoleranz gleichzeitig zu gewährleisten. Wer dieses Thema vertiefen will, findet weitergehende Informationen dazu in der Linksammlung am Ende dieses Artikels.
Automatisierung und Optimierung von IoT-Prozessen mit der Cloud
Ist die Integration der IoT Daten in die eigenen Geschäftsprozesse abgeschlossen, können diese automatisiert und optimiert werden. Dies passiert in der letzten Phase OPTIMIZE und erfordert im wesentlich drei Dinge: Leistungsfähige (skalierbare) Rechenleistung, eine gut strukturierte Datengrundlage und intelligente Algorithmen.
Rechenpower bekommt man – wie könnte es anders sein – aus der Wolke: Stichwort „Cloud Computing“. Damit ist man in der Lage, auch große Mengen an Rohdaten für eine weitergehende Analyse aufzubereiten. Das ist insbesondere dann notwendig, wenn man es mit unstrukturierten Daten, beispielsweise Textdaten einer Social Media Plattform, zu tun hat. Grob gesagt werden hierzu die unstrukturierten Daten auf relevante Informationen durchsucht und dann in strukturierte Daten transformiert. Die so strukturierten Daten können nun verwendet werden, um für bestimmte Geschäftsabläufe nach einer optimierten Lösungsalternative zu suchen. Hierzu gibt es ganz unterschiedliche Verfahren. Begriffe die in diesem Zusammenhang immer wieder fallen sind beispielsweise Data Mining, evolutionäre Algorithmen, MapReduce, Fuzzy Logik, Decision Support Systems, Machine Learning und künstliche Intelligenz. Jedes dieser Themen stellt für sich genommen schon ein eigenes Forschungsgebiet dar, so dass es leider den Rahmen dieses Blogartikels sprengt sie alle auch nur im Ansatz näher zu erläutern. Auch hierzu soll die bereits erwähnte Linkliste ganz am Ende dieses Blogbeitrags zumindest einen kleinen Einstieg liefern.
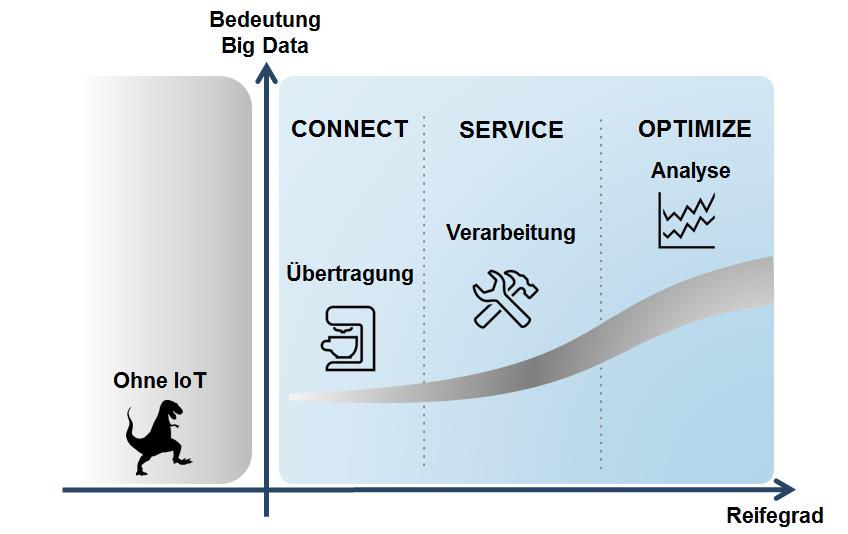
Will man die vorher beschriebenen Schritte auf dem Weg zu einem IoT Geschäftsmodell umsetzen, entstehen ganz klar auch Kosten. Eine IT-Infrastruktur muss aufgebaut, Geschäftsprozesse müssen angepasst und neue Tools und Verfahren müssen implementiert werden. Gleichzeitig bietet aber auch jede Phase die Möglichkeit, die gewonnen Daten und Informationen zu monetarisieren. Je mehr Informationen man gewinnt, desto mehr Geld kann man damit verdienen. Daraus folgt dann auch, dass die Bedeutung und auch der Anteil an der Wertschöpfung von Big Data steigt, je weiter man im Reifegradmodell voranschreitet.
Im dritten und letzten Teil dieser Blogserie wird ein ganz konkreter Anwendungsfall – der Ausfall einer Werkzeugmaschine – vorgestellt. Anhand dieses Beispiels soll dann der Zusammenhang zwischen Big Data und den einzelnen Phasen des Reifegradmodells plastisch beschrieben werden.
Quellen und Linkliste:
ACID, CAP und BASE:
http://www.norcom.de/de
https://de.wikipedia.org/wiki/ACID
http://db-engines.com/de/article/CAP+Theorem
https://de.wikipedia.org/wiki/CAP-Theorem
http://t3n.de/magazin/relationale-datenbanken-bekommen-konkurrenz-nosql-neues-224737/
Data Mining und Descision Support Systems:
https://www.th-nuernberg.de
http://dbs.uni-leipzig.de/file/dw-ss08-kap6.pdf
https://www.minet.uni-jena.de/fakultaet/schukat/ML/Scriptum/
http://www.gdrc.org/decision/dss-types.html
https://www.youtube.com/watch?v=o6-Ejw9vet8
https://www.youtube.com/watch?v=W44q6qszdqY
Maschinelles Lernen und Künstliche Intelligenz:
https://www.youtube.com/watch?v=qDbpYUbf3e0
https://cloud.google.com/prediction/docs/
https://www.youtube.com/watch?v=-rMMTv7XLYw
https://www.youtube.com/watch?v=TnUYcTuZJpM
https://www.ibm.com/watson/
http://t3n.de/news/twentybn-startup-kuenstliche-intelligenz-deep-learning-709698/
https://de.wikipedia.org/wiki/K%C3%BCnstliche_Intelligenz
Evolutionäre Algorithmen, MapReduce, Fuzzy Logik:
http://www.ra.cs.uni-tuebingen.de/mitarb/streiche/publications/Diplomarbeit.pdf
http://www.ki.informatik.uni-frankfurt.de/lehre/WS2012/KI/folien/06-suche-4.pdf
https://de.wikipedia.org/wiki/MapReduce
https://www.youtube.com/watch?v=bcjSe0xCHbE
http://www.urz.ovgu.de/
http://dbs.uni-leipzig.de/file/seminar_0910_findling_K%C3%B6nig.pdf
https://de.wikipedia.org/wiki/Apache_Hadoop
http://reinarz.org/dirk/fuzzykugel/fuzzy.html
http://www.spektrum.de/magazin/fuzzy-logic-am-praxisbeispiel/820701
https://www.youtube.com/watch?v=7FcMhTTG1Cs

Very Impressive Big Data tutorial.
https://www.youtube.com/watch?v=1jMR4cHBwZE