Machine Learning – Was steckt eigentlich dahinter?
Machine Learning (ML) ist momentan eines der Schlagwörter, wenn über heiße Trends in der IT Welt diskutiert wird. Einige Anwendungen kennt man bereits aus dem Alltag. So basieren zum Beispiel Missbrauchserkennung von Kreditkarten oder die Filmvorschläge von Netflix auf ML Modellen.
Gerade im Zuge der Digitalisierung und dem Zeitalter von Big Data spielen Machine Learning Modelle für die Eroberung neuer Geschäftsfelder und damit den Erfolg von Unternehmen eine immer größere Rolle. Ein Grund, sich dem Thema also intensiver zu widmen.
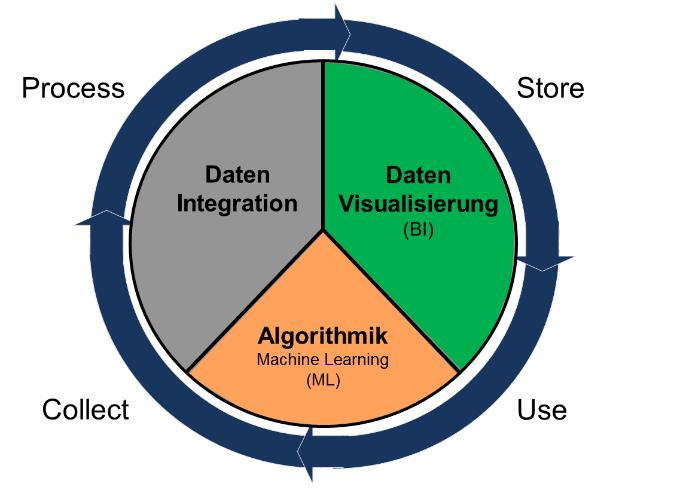
Unsere Erfahrung hat gezeigt, dass sich in den meisten Big Data Anwendungen die folgenden drei Themen wiederfinden:
- Datenintegration / Verarbeitung
- Datenanalyse/Algorithmik
- Datenvisualisierung/BI
Folglich haben wir bei doubleSlash unsere interne Big Data Arbeitsgruppe nach dieser Struktur ausgerichtet.
Machine Learning
Dieser Beitrag soll einen Einblick in das Thema Machine Learning geben und folgende Fragen beantworten:
- Was ist Machine Learning und welche Ziele werden verfolgt?
- Wo ist Machine Learning im Kontext Künstliche Intelligenz einzuordnen?
- Was sind Teilbereiche und Methoden von Maschinellem Lernen?
In seiner simpelsten Interpretation ist Machine Learning das Schaffen von Intelligenz in einem System mit dem Ziel, menschliche Entscheidungsfindung zu vereinfachen und zu optimieren.

Das Ziel von Machine Learning ist das selbstständige „Erlernen“ eines möglichst passenden Prognose- bzw. Klassifizierungsmodells durch ein System, in Bezug auf einen bestimmten Zielwert oder die Identifikation bestimmter Muster in Daten.
Prognose- bzw. Klassifizierungsmodells durch ein System, in Bezug auf einen bestimmten Zielwert oder die Identifikation bestimmter Muster in Daten.
Prognose- bzw. Klassifizierungsmodells durch ein System, in Bezug auf einen bestimmten Zielwert oder die Identifikation bestimmter Muster in Daten.
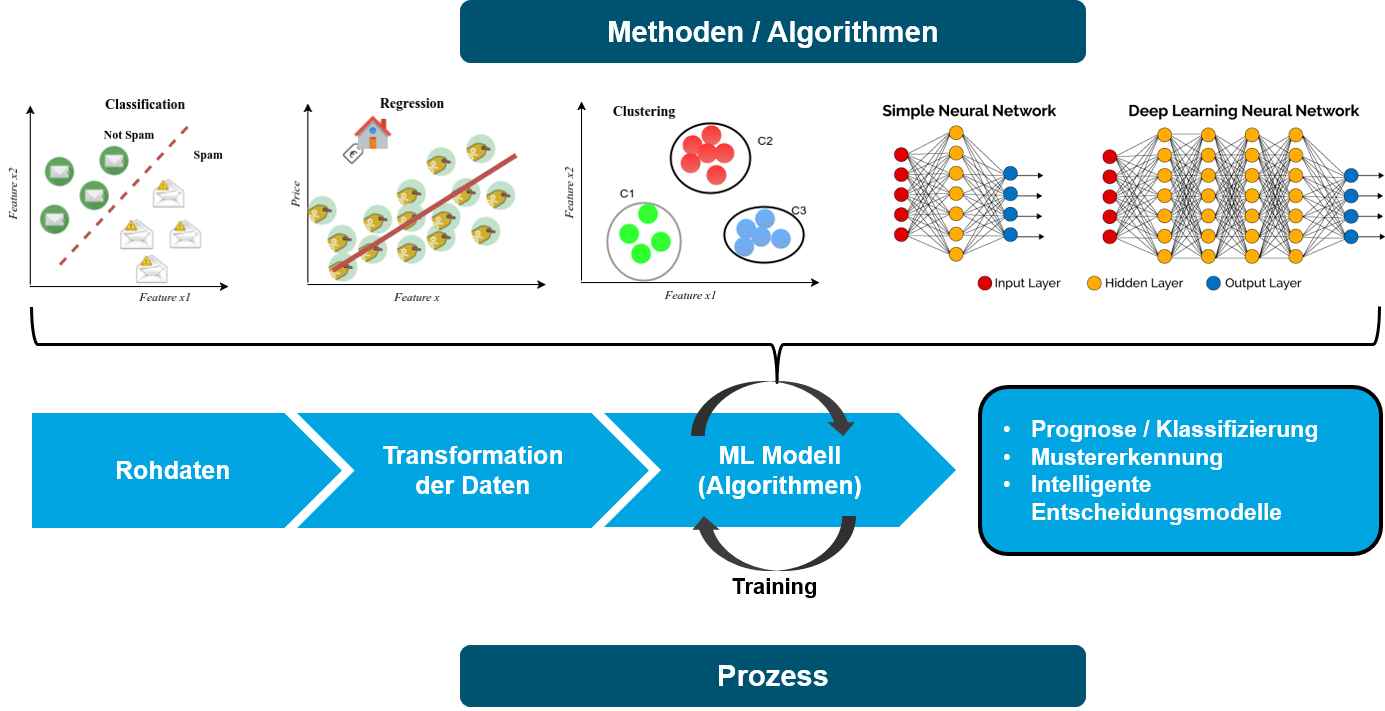
Die Methoden des ML entscheiden darüber, wie passend ein Modell im Hinblick auf die Realität ist und bestimmt damit seine Aussagekraft. Im letzten Abschnitt schauen wir uns das noch genauer an.
Dazu kommt der spezifische ML Prozess (Workflow), mit dem das Erlernen bzw. Optimieren des Modells realisiert wird.
Wir wollen uns den Machine Learning Workflow hier genauer anschauen. Er ist darauf ausgelegt, Modelle zu trainieren, indem in zahlreichen Durchläufen die Annahmen des Modells durch Testdaten validiert werden.
Der ML Workflow teilt sich zwei Phasen auf:
- Trainingsphase: Nach Wahl des ML Modells (Algorithmik) wird mit Hilfe von Trainings- und Testdaten in zahlreichen Durchläufen das Modell trainiert. Die Daten durchlaufen zunächst eine Transformation, man spricht hier auch von Feature Extraction. Hier werden die Eingabedaten auf bestimmte Zielattribute „reduziert“.
Nach Trainingsläufen mit dem Modell werden diese evaluiert und entsprechende Anpassungen an den Parametern des Modells vorgenommen. - Anwendungsphase: Hat sich ein ML Modell in der Trainingsphase bewährt wird das Modell auf reale Daten losgelassen. Auch hier wird die im Modell vorgenommene Feature Extraction durchgeführt. Prognosen, Klassifizierung oder Strukturierung der Daten findet dann in Geschäftsmodellen Anwendung.
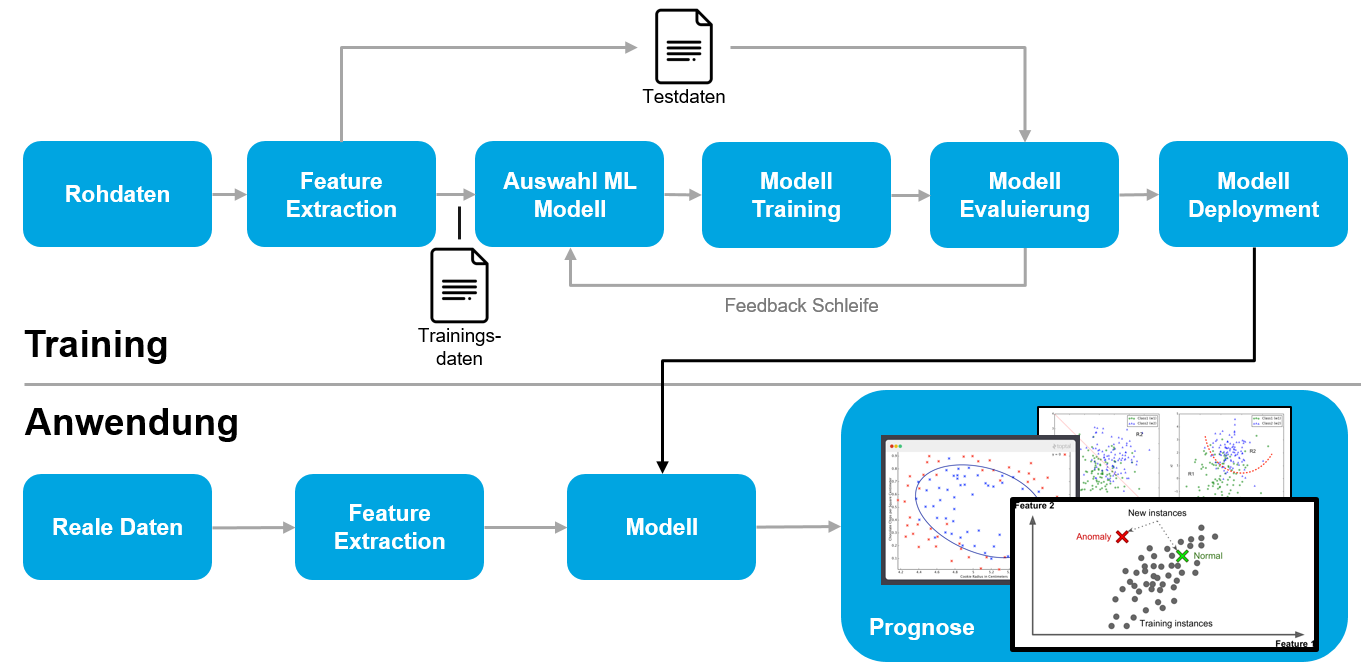
Der Schritt der Feature Extraction wird auch gerne als Teil der übergreifenden Dimensionsreduktion genannt. Hier werden die Eingabedaten auf eine für sie repräsentative Teilmenge reduziert, um die Komplexität im Modell zu verringern. Eine gängige Methode der Dimensionsreduktion ist die Hauptachsentransformation.
Machine Learning im Kontext AI
In den zahlreichen Diskussionen um Künstliche Intelligenz, Machine Learning oder auch Deep Learning werden diese Begriffe oft vermischt oder als Synonym verwendet. Wir wollen das Ganze einmal Auflösen.
Schauen wir auf „Abbildung 4 – Machine Learning Kontext“, so sehen wir folgenden Zusammenhang: Deep Learning ist ein Teilbereich des Machine Learnings, das wiederum ein Teil von Künstlicher Intelligenz ist.
Die Teilbereiche der Künstlichen Intelligenz unterscheiden sich durch ihr Anwendungsfeld, haben aber zum Teil große Überschneidungen was die Verwendung der Algorithmen angeht. So basiert Natürliche Spracherkennung (Natural Speech Recognition) mittlerweile größtenteils auf Machine Learning Modellen.
Deep Learning ist die komplexeste und mächtigste Kategorie des Machine Learning. Unter Deep Learning versteht man im Allgemeinen die Verwendung und Optimierung von künstlichen neuronalen Netzen (Deep Neural Networks). Populärstes Beispiele für eine Deep Learning Anwendung ist AlphaGo Zero.

- Supervised Learning
- Unsupervised Leaning
- Reinforcement Learning
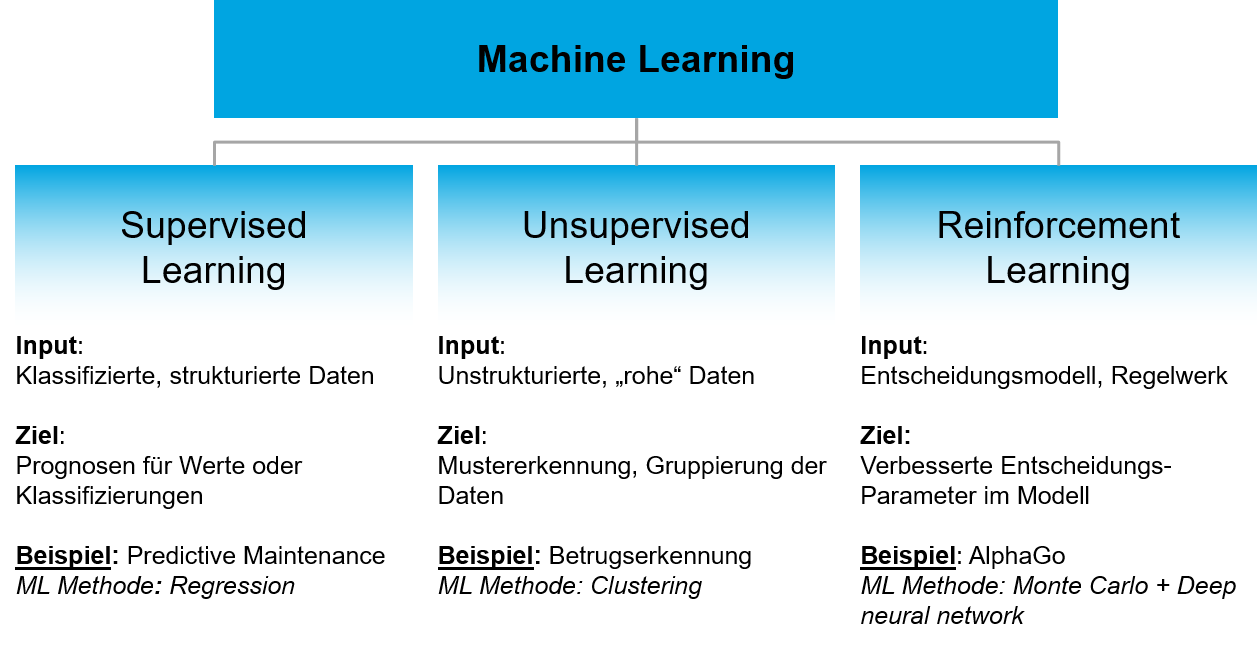
Die drei Kategorien unterscheiden sich dabei in ihren Eingabedaten, der Art des Lernprozesses und ihrem Aussageziel.
Beim Supervised Learning sind sowohl Eingabeparameter (Features) als auch Zielwerte (die richtigen Antworten) bereits bekannt. Mit Hilfe von Trainingsdaten wird dann ein Modell gebildet, welches in der Lage ist für neue, bis dato unbekannte Eingangsdaten eine entsprechende Prognose zu berechnen. Vereinfacht ausgedrückt lernt das System ähnliche Eingangsdaten ähnlichen Zielwerten zuzuordnen. Das System weiß also, wie und was es zu lernen hat. Man spricht vom Überwachten Lernen (oder eben Supervised Learning).
Supervised Learning lässt sich in zwei Problemkategorien unterteilen:
- Regressionsprobleme: D.h. der Zielwert ist ein realer Wert, z.B. Einnahmen oder Regenmenge
- Klassifikationsprobleme: Der Zielwert ist die Einordnung in eine Kategorie, z.B. Krebszelle vs. gesunde Zelle
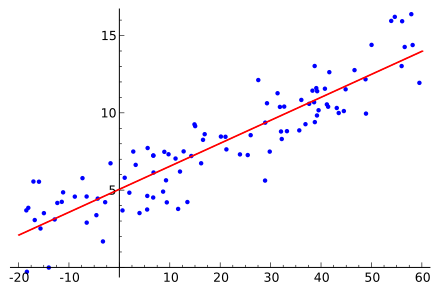
Für diese Probleme kommen die folgenden Algorithmen am häufigsten zum Einsatz:
- Regression (linear, logistisch, multivariat)
- Support Vektor Maschinen
- Naive Bayes’sche Schätzer
- Einfache Neuronale Netze
Auch das Unsupervised Learning lässt sich noch einmal in zwei Kategorien aufteilen:
- Clustering: Ziel ist es, die inhärenten Gruppen (Cluster) in den Daten identifizieren und die Daten danach zu strukturieren
- Assoziationsmodelle: Ziel ist es, logische Zusammenhänge (Regeln) zwischen Datengruppen zu identifizieren (z.B. Kunden, die Produkt A kaufen wählen auch Produkt B)
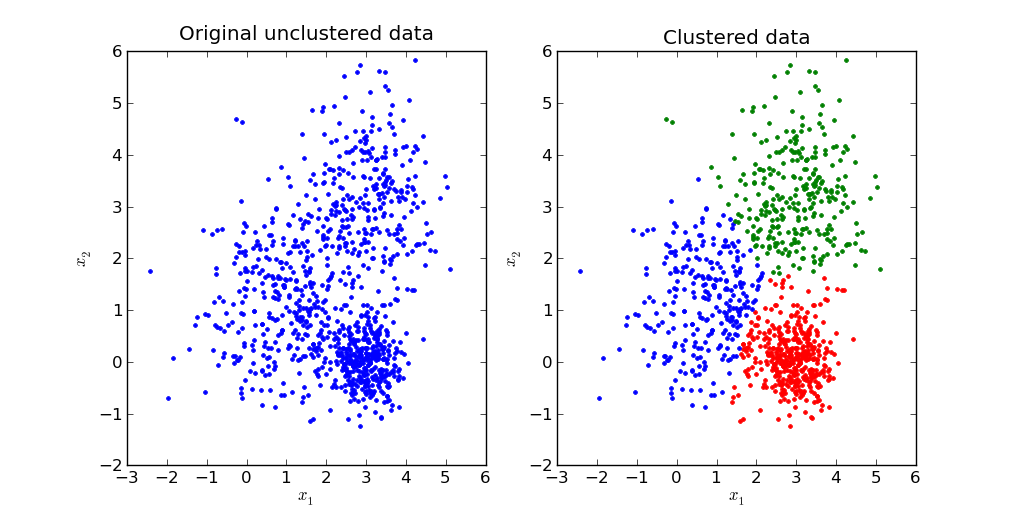
Für Modelle des Unsupervised Learnings werden unter anderem die folgenden Methoden verwendet:
- K-Means
- K-NN (k-nearest-neighbour clustering
- Autonencoder (als Anwendung von Neuronalen Netzen)
Ziel beim Reinforcement Learning ist es, dass ein Agent eines Entscheidungsmodells selbstständig eine Strategie erlernt, mit der die erhaltene „Belohnung“ maximiert wird. Eine Belohnung kann zum Beispiel Sieg oder Niederlage in einem Spiel sein.
Agenten sind in Modellen des Reinforcement Learnings ausführende Einheiten, aus welchen die komplexen Berechnungsschritte aufgeteilt werden. Der Agent evaluiert hierbei nicht in jedem Schritt, welche Aktion gerade optimal ist, sondern erhält zu einem bestimmten Zeitpunkt eine Belohnung, die auch negativ sein kann (z.B. Gewinn / Verlust). Je nach Belohnung gewichten die Agenten ihre Entscheidungen im Modell.
Da die Zielfunktion in komplexen Modellen mit großen Aktionsräumen nicht mehr numerisch berechnet werden kann, verwendet man künstliche neuronale Netze (Deep Neural Networks), um die Funktion zu approximieren.
Um die Agenten zu trainieren, werden als Algorithmen häufig Monte-Carlo-Methoden oder das Temporal Difference Learning eingesetzt.
elektroniknet.de beschreibt, was es mit dem Projekt „Fast&Slow“ des DFKI zum Thema Deep-Learning auf sich hat.
Quellen:
[1] https://www.researchgate.net [2] https://www.datascience.com [3] https://www.innoarchitech.com/machine-learning-an-in-depth-non-technical-guide/ [4] https://www.quora.com/ [5] https://www.prnewswire.com/news-releases/fico-machine-learning-algorithms-improve-card-not-present-fraud-detection-by-30-300529629.html [6] https://deepmind.com/blog/alphago-zero-learning-scratch/ [7] https://deeplearning4j.org/neuralnet-overview [8] https://cloud.google.com/vision/?hl=de [9] https://quickdraw.withgoogle.com/ [10] https://research.adobe.com/project/scribbler-controlling-deep-image-synthesis-with-sketch-and-color/Bildquellen:
[11] Abbildung 4: https://www.ibm.com/blogs/business-analytics/why-finance-professionals-need-artificial-intelligence/ [12] Abbildung 6: https://de.wikipedia.org/wiki/Einfache_lineare_Regression [13] Abbildung 7: https://mubaris.com/2017/10/01/kmeans-clustering-in-python/