
Predictive User Experience in Business Anwendungen
Laut einer Studie1 beschäftigen sich bereits die Hälfte der deutschen Unternehmen mit dem Thema KI und deren Anwendung in Geschäftsprozessen und in Form neuer Produkte – Tendenz steigend.
Auch im Bereich User Experience bei Business Anwendungen gibt es schon Ansätze und Produkte, die maschinelles Lernen sinnvoll einsetzen. Wir haben uns angeschaut, ob und wie sich auch das Benutzererlebnis von Anwendungen durch den Einsatz von künstlicher Intelligenz verbessern lässt und wo die Grenzen liegen.
Predictive User Experience (PUX)
Mit Hilfe von Predictive User Experience (PUX) soll sich eine Anwendung oder ein Produkt proaktiv auf den Benutzer einstellen. Durch Analyse des bisherigen Nutzerverhaltens soll vorhergesagt werden, welche Aktionen ein Anwender als nächstes vornehmen wird. Dadurch kann individuell die Arbeitsweise optimiert werden. Eine der ersten Herangehensweisen in diesem Gebiet ist das Anticipatory Design. Das Ziel von Anticipatory Design ist es, im Interesse des Nutzers (User Centered Design) Entscheidungen zu treffen, um ihn damit von unnötigen Aufgaben und Stress zu befreien. Da das Anticipatory Design die erste und bisher einzige Methode innerhalb der Predictive User Experience ist, werden die Begriffe meist synonym verwendet.
Anticipatory Design
Das Anticipatory Design ist mehr eine Designvorlage, als ein genereller Begriff zur Beschreibung von intelligenter User Experience. Diese Vorlage ergibt sich aus dem Zusammenspiel des Lernens, Vorhersagen und Antizipieren:
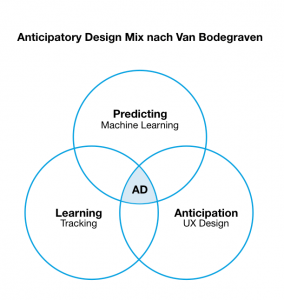
Smarte Geräte im Bereich IoT oder Tracking-Methoden in Software sammeln große Mengen an Daten. Diese werden durch Machine Learning (ML) Algorithmen verarbeitet, um Vorhersagen bezüglich des Nutzerverhaltens zu treffen. Anschließend wird versucht, aus diesen Vorhersagen intelligente Features für die Anwendung zu entwickeln und diese zu integrieren.
„Learning“ durch Datenerhebung
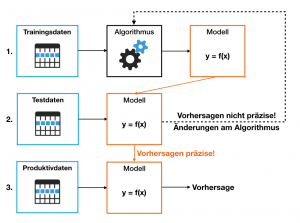
Die Menge der verfügbaren Daten ist ausschlaggebend dafür, wie präzise ein intelligentes Feature Vorhersagen treffen kann. Zusätzlich hängt die Menge von der Komplexität des Einsatzes ab: Ein Fahrzeug, das autonom im Straßenverkehr fahren soll, braucht ein sehr komplexes Modell und somit sehr viele Daten. Ein Fahrzeug, dass nur innerhalb einer Halle im Kreis fahren soll, wird mit deutlich weniger Daten auskommen. Dabei gibt es zwei Wege an Daten zu kommen, die für das ML Training und den produktiven Einsatz genutzt werden können.
Nutzer-Tracking
Es wird gezielt die tatsächliche Interaktion mit der Anwendung aufgezeichnet. Ein Nutzer-Tracking muss in den meisten Fällen erst implementiert werden, da dieses in Businessanwendungen nur selten bereits existiert. Anschließend müssen über einen längeren Zeitraum Daten gesammelt werden, um eine ausreichend große Datenmenge zu haben.
Anwendungsdaten
Daten, die der Nutzer in die Anwendung eingibt und damit in der Datenbank gespeichert sind. In Business Anwendungen liegen diese meist in großen Mengen vor und liefern daher eine gute Basis für das ML Training.
„Predicting“ durch Machine Learning
Für das Training unterscheidet man die Lernverfahren in drei algorithmischen Ansätzen. Jedes Verfahren bietet dabei einen anderen Lösungsweg, für die unterschiedlichsten Arten von Daten und zu erreichenden Zielen.
| Was steckt eigentlich hinter dem Begriff „Machine Learning“? Mehr dazu unter https://blog.doubleslash.de/machine-learning-was-steckt-eigentlich-dahinter/ |
Überwachtes Lernen
Beim überwachten Lernen (engl. Supervised Learning) sind die Trainingsdaten gekennzeichnet. Das bedeutet, dass zu einem Eingabewert das richtige Ergebnis (auch „Label“ genannt) bekannt ist. Möchte man zum Beispiel ein System auf Handschrifterkennung trainieren, müssten bei den Trainingsdaten jeweils die richtigen Lösungen stehen. Bei einem handgeschriebenen „A“ müsste das Label „A“ als korrekte Antwort stehen. Der Algorithmus füllt dann die Lücke zwischen Eingabe und Ergebnis. Das überwachte Lernen kommt also zum Einsatz, wenn das Ergebnis bereits bekannt ist.
Unüberwachtes Lernen
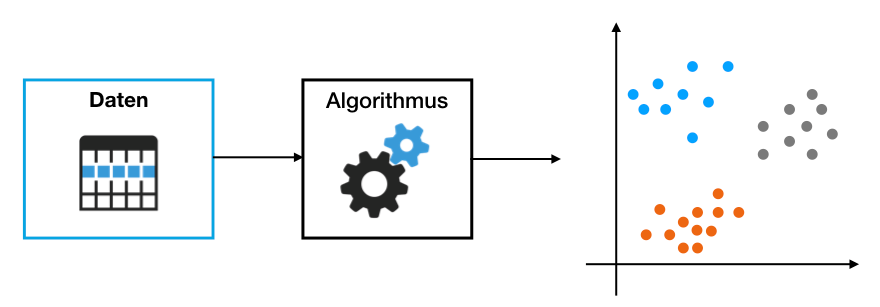
Beim unüberwachten Lernen (engl. Unsupervised Learning) sind die Testdaten nicht gekennzeichnet. Das System weiß nicht, was es erkennen soll. Es wird versucht, versteckte Muster und Zusammenhänge in einer Menge unstrukturierter Daten zu erkennen. Allerdings weiß das System nicht, was die Kategorien bedeuten, da keine Labels vorhanden sind. Dabei soll der Algorithmus die großen Datenmengen so strukturieren, dass wir Menschen sinnvolle Informationen aus ihnen gewinnen können. Dabei müssen die Daten nicht zwingend visualisiert werden, dennoch wird dies häufig gemacht, damit das menschliche Gehirn die Daten in einen Kontext bringen kann. Beispielsweise könnte ein Algorithmus mit unüberwachtem Lernen alle vorhandenen Nutzerdaten und -aktivitäten analysieren und dadurch Nutzergruppen identifizieren oder Anomalien in Systemen erkennen. Das unüberwachte Lernen kommt also dann zum Einsatz, wenn das Ergebnis unbekannt ist.
Bestärkendes Lernen
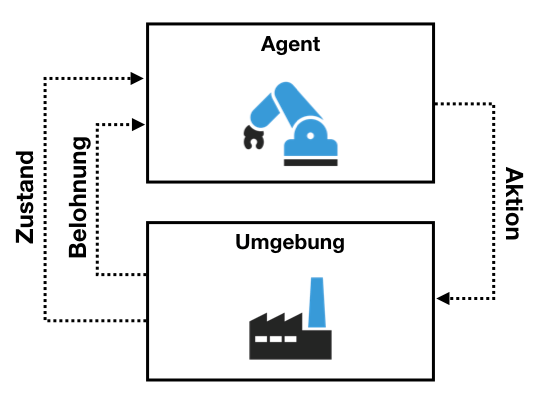
Das bestärkende Lernen (engl. Reinforcement Learning) ist das dritte große Lernverfahren innerhalb des Machine Learnings. Dieser Ansatz orientiert sich am natürlichen Lernverhalten des Menschen. Dabei werden verschiedenste Handlungen innerhalb eines Aktionsraums von der Umgebung bewertet. Diese Bewertung kann in Form einer Belohnung oder einer Bestrafung erfolgen. Dadurch soll das System durch das „Trial & Error“ Prinzip (ugs. „ausprobieren“) die Auswirkungen verschiedener Handlungen lernen. Über tausende Iterationen hinweg erkennt der Agent den Zusammenhang zwischen seinen Aktionen und dem Nutzen. Er wird anschließend versuchen, den Nutzen immer zu maximieren.
| Wo sind die Grenzen von künstlicher Intelligenz? Mehr dazu unter https://blog.doubleslash.de/ki-kann-alles-die-aktuellen-grenzen-von-ki-und-deep-learning/ |
Stand PUX heute
Um den aktuellen Stand von PUX einschätzen zu können, haben wir uns diese Plattformen angeschaut, da es aus dem Bereich von Unternehmensanwendungen bisher kaum öffentliche Beispiele gibt. Die folgenden Beispiele zeigen, wie viele Daten diese Unternehmen zur Verfügung haben, um ihre Algorithmen trainieren und damit sehr gute Ergebnisse im PUX erzielen zu können. Allerdings ist laut einer aktuellen Studie der Crisp Research AG1, bereits bei 22% der deutschen Unternehmen Machine Learning produktiv im Einsatz. Dabei variieren die Einsatzgebiete für Machine Learning.
Instagram und Facebook haben schon früh den Ansatz verfolgt, dem Nutzer nur Dinge anzuzeigen, die ihm potenziell gefallen könnten. Die Newsfeeds beider Plattformen wurden dementsprechend verändert, sodass potenziell interessantere Dinge weiter oben platziert wurden.
Spotify verfolgt mit den automatisch erstellen Playlists ein ähnliches Prinzip. Dabei nutzt Spotify die Playlists aller Nutzer der Plattform, um eine neue Playlist nach dem Musikgeschmack des Nutzers zu erstellen.
Das smarte Thermostat „Nest“ von Google lernt ebenfalls durch Beobachtung des Nutzers dazu. Dabei wird beobachtet, wann und wie der Nutzer die Temperatur anpasst und das Thermostat regelt dann in der Zukunft automatisch aufgrund der Vorlieben und den eingestellten Temperaturen der Vergangenheit.
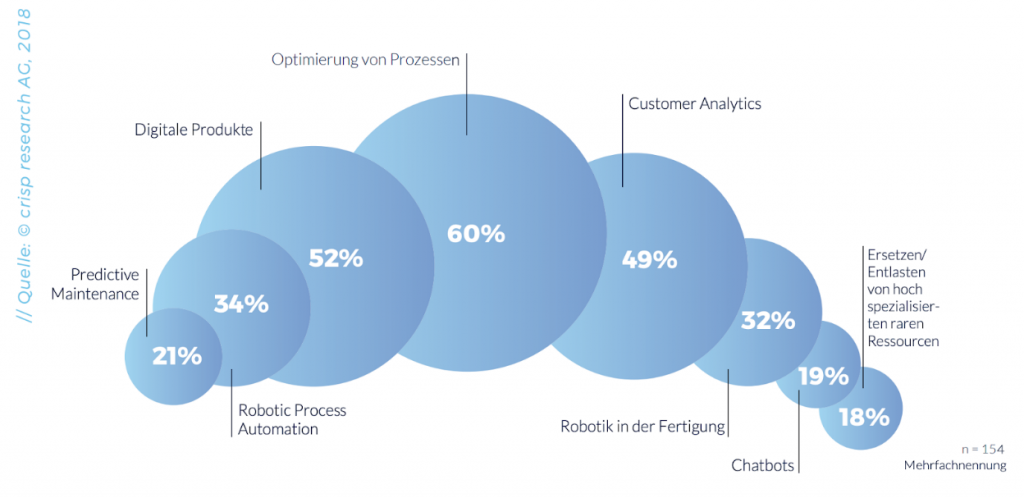
Mit 60% ist die Optimierung von Prozessen der meist genutzte Use Case von ML in deutschen Unternehmen. Dabei geht es beispielsweise um die Vernetzung von Anlagen in der Produktion, um durch Analyse der Anlagen Einsparungen zu generieren oder Prozesse zu optimieren. Auch in der Kundenanalyse hat man bereits erkannt, dass ML bei der Auswertung von großen Mengen Nutzerdaten hilfreich sein kann. Das Thema Machine Learning erlebt aktuell wieder einen Aufschwung. Laut der Studie beschäftigen sich bereits die Hälfte der deutschen Unternehmen mit dem Thema – Tendenz steigend.
Datenschutz
Hier muss einiges beachtet werden, damit eine Umsetzung von Predictive User Experience in B2B-Anwendungen (also im Unternehmenskontext) überhaupt rechtlich möglich wird. Um DSGVO-konform zu handeln, muss dem Nutzer transparent gemacht werden, auf welcher Berechtigungsgrundlage seine Daten verarbeitet und zu welchem Zweck diese genutzt werden. Im unternehmensinternen Umfeld gibt es verschiedene Wege, die Einwilligung des Anwenders/Angestellten einzuholen:
- Arbeitsvertrag
- Unternehmensrichtlinien
- Opt-In Verfahren
Nach der Zustimmung muss der Anwender zusätzlich jederzeit die Möglichkeit haben, sich diese wieder anschauen und ggfs. widersprechen zu können. Des Weiteren hat er das Recht, alle über ihn gesammelten Daten einzusehen oder diese löschen zu lassen. Ein Mechanismus hierfür muss bei der Entwicklung intelligenter Features im Voraus berücksichtigt werden.
Hat man also die Zustimmung des Anwenders, dessen Nutzungsdaten zu verarbeiten, dürfen intelligente Features in firmeninterner Software auf Basis von Nutzungsdaten problemlos umgesetzt werden.
Einsatzzwecke
Der Einsatz intelligenter Features ist so individuell wie vielseitig. Jede Anwendung bietet andere Möglichkeiten und muss daher individuell betrachtet werden. Ein konkretes Beispiel, das in vielen Anwendung Einsatz finden könnte, sind vorausgefüllte Felder.
Vorausgefüllte Felder
Das Ziel ist es, die Auswahl innerhalb einer Anwendung oder Prozessschritts für den Anwender zu filtern und ihm dadurch Entscheidungen abzunehmen und schneller in der Bearbeitung zu werden. Das bedeutet, dass ein ML Algorithmus Anwendungsdaten auswertet und vorhandene Muster erkennt. Damit lassen sich Vorhersagen treffen, wie verschiedene Dropdown- und Freitextfelder in Verbindung stehen. Diese Vorhersagen werden dann genutzt, um die Felder mit einer Vorauswahl zu versehen.
Ist eine Vorhersage nicht korrekt, muss der Anwender beispielsweise die Wahl im Dropdown Menü anpassen oder den vorausgefüllten Text ändern. Hierbei würde man dann zwar keine Zeit sparen, aber auch keine verlieren. Ist die Vorhersage allerdings für alle Felder korrekt oder muss nur wenig angepasst werden, dann spart der Nutzer Zeit und ist effizienter.
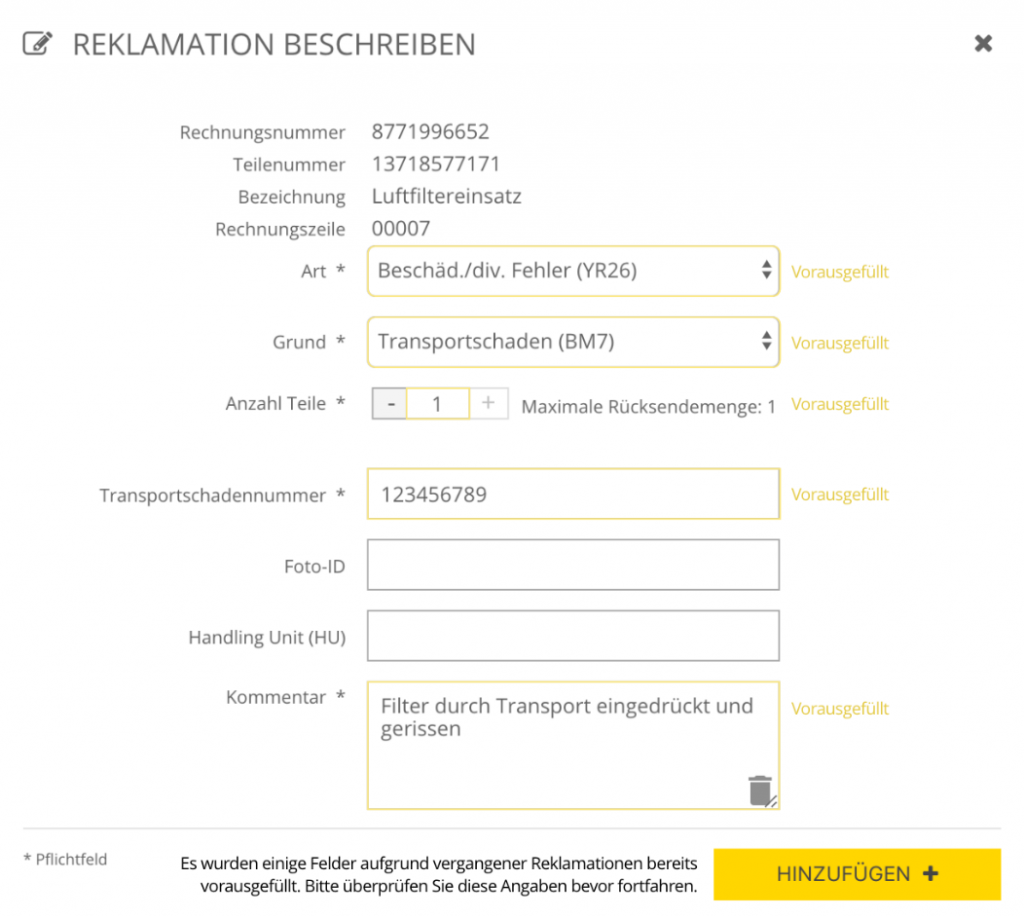
Bei dem oben gezeigten Beispiel werden Dropdowns und Freitextfelder vorausgefüllt. Dafür wird analysiert, was beispielsweise die häufigste Art und Grund für die Reklamation eines bestimmten Teiles ist. Wenn Teil X fast immer mit Art Y und Grund Z reklamiert wurde und dabei gleiche Kommentare verwendet wurden, könnten eben diese Felder bereits vorausgewählt werden. Dies wäre ein Beispiel für unüberwachtes Lernen, indem der ML Algorithmus Muster und Verbindungen in einer großen Datenmenge erkennt.
Dieses sehr simple Beispiel soll einen Eindruck davon vermitteln, was möglich ist. Die Menge an verschiedenen Anwendungen, Prozessen und Workflows, die es alleine im Bereich der Business Anwendungen gibt, ist enorm. Dadurch ergibt sich ein Sammelsurium an verschiedensten Einsatzmöglichkeiten:
- Anomalie-Erkennung zur Fehleranalyse und -behebung
- Erkennung von Usability Schwachstellen (z.B. nicht oder falsch genutzte Funktionen)
- Schnellzugriff Shortcuts je nach Nutzung
Ziele von PUX
Produktivität
Intelligente Features können der Entscheidungsmüdigkeit entgegenwirken und somit die kognitive Belastung reduzieren. Mitarbeiter, die in ihrem Arbeitsalltag eine Anwendung mit Anticipatory Design verwenden, könnten so später an einem Arbeitstag noch eine höhere Produktivität ausweisen und nicht aufgrund einer Entscheidungsmüdigkeit eventuell Fehler machen.
Effizienz
Durch weniger Entscheidungen können Nutzer neue Workflows entwickeln und schneller/effizienter die Anwendung nutzen. Fallen Entscheidungen für den Nutzer weg oder werden sie ihm erleichtert, so hat das durchaus Auswirkungen auf die Effizienz in der Bedienung.
Bedingungen für eine erfolgreiche Umsetzung
Datenmenge
Für eine erfolgreiche Umsetzung intelligenter Features wird eine große Menge Daten benötigt, um möglichst akkurate Vorhersagen zu treffen.
Analytics Know How
Für die Wahl des passenden Machine Learning Algorithmus und das Training eines intelligenten Features bedarf es Expertenwissen in diesem Bereich.
UX Know How
Vor der Entwicklung solcher Features muss analysiert werden, wo ein Einsatz Mehrwert bringen könnte und wo die aktuelle User Experience Nachholbedarf hat. Denn nicht jedes intelligente Feature erhöht die Produktivität und Effizienz.
Fazit
Predictive User Experience bietet die Möglichkeit, Prozesse und Workflows effizienter zu gestalten und die Akzeptanz der Mitarbeiter gegenüber der Anwendung zu erhöhen, weil man sich proaktiv auf das Nutzerverhalten einstellen kann. Arbeiten können schneller erledigt werden, wodurch Mitarbeiter produktiver sind und für bessere Ergebnisse sorgen. PUX bietet somit große Möglichkeiten der Prozessoptimierung innerhalb des eigenen Unternehmens und kann richtig umgesetzt Geld sparen und Fehler in der Bedienung vermeiden. Möglich wird das mithilfe von KI und Machine Learning Methoden. Aber natürlich lässt sich PUX nicht pauschal in jeder Anwendung gewinnbringend umsetzen und es sollte daher im Einzelfall geprüft werden, ob und wie eine Anwendung von diesen Methoden profitieren kann.
Weiterführende Links
- doubleSlash als Experte im Bereich Datenintegration
- doubleSlash als Experte im Bereich Advanced Analytics und ML
- doubleSlash als Experte im Bereich User Experience Design
Quellen
1 Schwalm; Velten: Machine Learning in deutschen Unternehmen (https://www.crisp-research.com/publication/machine-learning-deutschen-unternehmen/) ^
2 Van Bodegraven, J. (2017): Introduction to Anticipatory Design, eBook (www.uxdesign.cc) ^
3 Benjamin Aunkofer: Überwachtes vs unbewachtes maschinelles Lernen (https://data-science-blog.com/blog/2017/07/02/uberwachtes-vs-unuberwachtes-maschinelles-lernen/) ^
4 Sebastian Heinz: Einführung in Reinforcement Learning – wenn Maschinen wie Menschen lernen (https://www.statworx.com/de/blog/einfuehrung-in-reinforcement-learning-wenn-maschinen-wie-menschen-lernen/) ^
