
Technische Umsetzung von Machine Learning Lösungen mit Spark MLIib
Im ersten Teil der Blogserie haben wir eine Einführung in das Thema Machine Learning (ML) gegeben, ML im Kontext von AI vorgestellt und die verschiedenen Teilbereiche und Methoden vorgestellt. In diesem Blogartikel will ich die technische Umsetzung detaillierter beschreiben.
Entsprechend der zuletzt vorgestellten Aufteilung unserer Big Data Arbeitsgruppe betrachten wir in diesem Beitrag die folgenden Fragestellungen:
- Datenintegration: Wie müssen die Datenquellen an das System angebunden, aufbereitet und gespeichert werden?
- Datenanalyse: Wie und mit welchen Verfahren müssen die verfügbaren Daten analysiert und weiterverarbeitet werden?
- Datenvisualisierung: Wie werden die Ergebnisse für den Nutzer in geeigneter Weise dargestellt?
Um das Ganze praxisnah zu verproben haben wir das Projekt „SAPPhiRE“ (Social mediA Price PREdiction) ins Leben gerufen: Auf Basis von Tweets und dem historisierten Bitcoin-Kurs wird ein Prognosemodell für den Kurs der digitalen Währung geschaffen. Technologisch haben wir uns bei der Umsetzung der Datenintegration auf eine Auswahl aus dem Hadoop Ecosystem entscheiden, bei der Visualisierung setzen wir auf Tableau.
Für das Machine Learning Modell fiel unsere Wahl auf Spark MLlib. Die Technologie wird im Verlauf des Beitrags näher beschrieben.
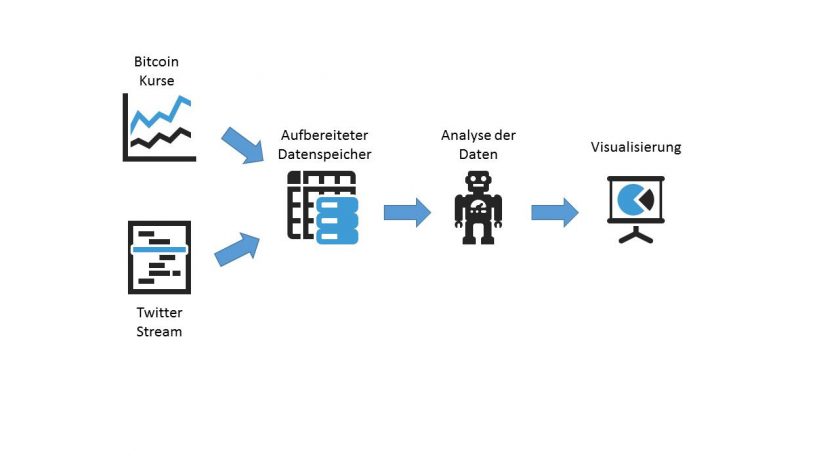
Der Bitcoin Kurs lässt sich relativ einfach über eine REST-Schnittstelle von CoinDesc auslesen. Hierzu wird ein selbstgeschriebenes Bash-Skript laufen, das einmal pro Minute den aktuellen Kurs ausliest (https://api.coindesk.com/v1/bpi/currentprice.json) und speichert. Um einen Informationsverlust zu vermeiden, soll auch das gesamte JSON abgespeichert werden.
Beim Auslesen der Tweets von Twitter erwarten wir einen permanent hohes Datenaufkommen. Aus diesem Grund haben wir uns für einen Streaming Ansatz entschieden (Twitter bietet eine entsprechende API an). Dieser unterscheidet sich von dem erstgenannten REST Prinzip dadurch, dass eine feste Verbindung zwischen unserem Client und dem Twitter Server aufgebaut wird und die Daten dann kontinuierlich übermittelt werden.
Da wir sowohl für die Bitcoin- als auch die Twitter-Daten sämtliche Rohdaten über einen längeren Zeitraum speichern wollen ist auf jedem Fall davon auszugehen, dass relativ schnell sehr große Datenmengen zusammenkommen werden. Damit sind für uns die drei V’s – Volume, Variance und Velocity – die ein Big Data Problem beschreiben, erfüllt.
Aus diesem Grund werden wir in der Umsetzung auf eine möglichst gut skalierbare Microservice Architektur auf Basis von Docker mit Spark (welches auch eine entsprechende Streaming API mitbringt) und Hive als Datenbank setzen.
Datenanalyse: Verarbeitung der Daten mit Spark MLlib
Für die weitergehende Analyse der Daten haben wir uns für den Einsatz von Spark MLlib entschieden. MLlib bietet eine API für die populärsten Machine Learning Algorithmen an, beispielsweise zur Erkennung von Clustern, der Berechnung Klassifikationen und Regressionen oder aber auch speziellere Verfahren wie kollaboratives Filtern. Auf der anderen Seite gibt es verschiedene APIs (Scala, Java, Phyton oder R) über die man Spark anprogrammieren kann.
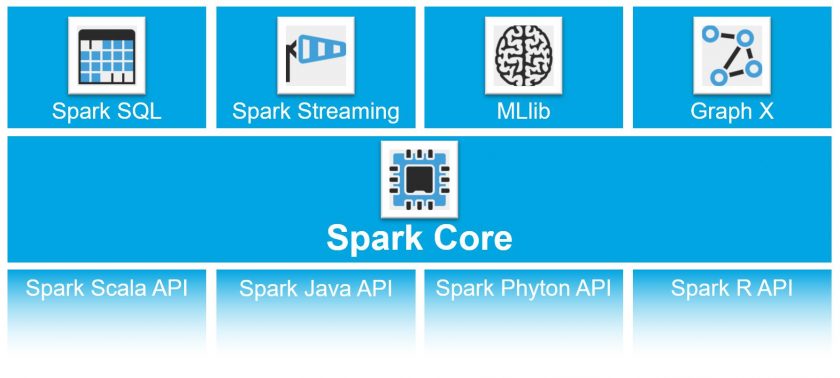
Da Spark auf verteilten Datenstrukturen und In Memory arbeitet, ist es möglich, auch sehr große Datenmengen effizient zu verarbeiten und zu analysieren. Dadurch hat Spark MLlib bei der Verarbeitung von Big Data Problemen einen erheblichen Geschwindigkeitsvorteil gegenüber anderen Technologien.
Spark hat hierzu das Konzept der DataFrames eingeführt. Damit ist es dem Programmierer möglich, „SQL-like“ auf den verwendeten Daten zu arbeiten, während Spark die gesamte „Magic“, d.h. die Verteilung und das Management der Daten im Cluster, im Hintergrund übernimmt. Gleichzeitig kann man mit DataFrames unterschiedliche Datenquellen anbinden, beispielsweise strukturierte Datendateien oder Hive.

Ein einfaches Anwendungsbeispiel – implementiert mit Spark MLlib
Um ein besseres Verständnis dafür zu bekommen wie Spark MLlib funktioniert, will ich im Folgenden ein einfaches Anwendungsbeispiel vorstellen. Darin soll eine einfache lineare Regression auf den Verlauf des Bitcoin-Kurses über 30 Tage (vom 24.12.2017-24.01.2018) angewendet werden. Auf Basis dieser Regression soll dann eine Prognose für die nächsten 30 Tage (den 23.02.2018) erfolgen. Uns ist bewusst, dass die Aussage dieser Prognose gering ist. Nichtsdestotrotz eignet sich dieses Beispiel gut, um einen ersten Einblick in die zugehörige Java API zu bekommen.
Im ersten Schritt werden die Daten aus einer Textdatei ausgelesen. Die in der Datei hinterlegten Werte bilden den Kurs (label) und das zugehörige Datum als eine fortlaufende Zahl (seit 01.01.1900) ab.

Anschließend wird die lineare Regression auf Basis der eingelesenen Trainingsdaten berechnet.
![]()
Zum Schluss lassen wir uns die wichtigsten Daten aus dem optimierten Modell ausgeben und berechnen eine entsprechende Vorhersage des Bitcoin Kurses.
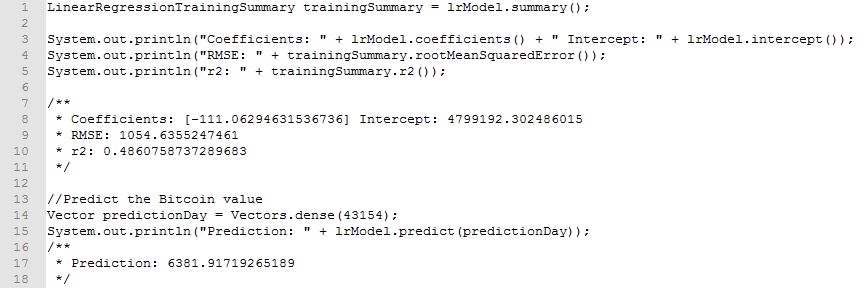
Die ausgegebenen Daten können nun wie folgt interpretiert werden:
- Der berechnete Wert R²=49% sagt aus, dass die Regression die Trainingsdaten relativ schlecht abbildet (100% entspricht einer perfekten Abbildung)
- Die Abweichung der Trainingsdaten von dem trainierten Modell beträgt RMSE≈1054,64 €
- Der Kurs lässt sich mittels
BitcoinKurs=4799192.302486015-111,06294631536736×DatumAlsFortlaufendeZahl berechnen
- Auf Basis der Regression wird der Bitcoin Kurs für den 23.02.2018 mit ≈ 6381.92 € prognostiziert
Die jeweiligen Ergebnisse müssen dann noch in einem letzten Schritt erneut zwischengespeichert werden, damit diese dann für die graphische Darstellung weiterverarbeitet werden können.
Für die Visualisierung der Analyseergebnisse haben wir uns für Tableau entschieden, welches von Gartner im Gartner Magic Quadrant fünf Jahre in Folge in der Kategorie Business Intelligence und Analyseplattformen als Leader eingestuft wurde.
Tableau ist eine Self-Service BI Lösung, die es dem Benutzer ermöglicht, verschiedene Datenquellen anzubinden und diese Daten dann zu visualisieren und zu analysieren. Tableau bietet hierbei einen extremen Variantenreichtum an Visualisierungsmöglichkeiten. Der Benutzer kann relativ schnell und einfach individualisierte Dashboards erstellen und durch die interaktive Visualisierung neue Erkenntnisse aus den Daten gewinnen. Tableau ermöglicht zudem ein gemeinschaftliches Arbeiten, indem die erstellen Dashboards in der gesamten Organisation mit anderen Benutzern geteilt werden können.
Für das Anbinden diverser Datenquellen bietet Tableau aktuell ca. 68 integrierte Konnektoren. Neben beliebten Datenquellen wie Oracle, AWS Redshift, Cubes, Teradata, Microsoft SQL Server findet sich hierunter auch eine Schnittstelle zu Cloudera Hadoop, welche für unser Projekt besondere Relevanz hat und ein wichtiges Auswahlkriterium bei der Wahl des Visualisierungstools war.
Neben Tableau Desktop und Tableau Server werden nicht nur unterschiedliche Produkte, sondern auch mehrere Lizenzmodelle angeboten. Tableau Server beispielsweise bietet die nötige Flexibilität für die Integration in eine bestehende Dateninfrastruktur oder das Speichern der Daten on-premise in der Cloud. Wir wollen die Visualisierung auf Tableau Desktop erstellen und auf dem seit Januar 2018 neu verfügbaren Tableau Server unter Linux bereitstellen.
Wir haben nun geklärt, wie die grundlegende Architektur unseres Systems aussehen soll, welche Komponenten notwendig sind und mit welchen Technologien wir ins Rennen gehen wollen. Wir haben einen ersten, sehr einfachen Algorithmus vorgestellt, der grundsätzlich zeigt wie eine Umsetzung mit MLlib aussehen kann.

Im nächsten Beitrag werden wir beschreiben, wie wir unser Modell erweitert haben, um dessen Aussagekraft zu verbessern. Hierzu wollen wir insbesondere die Daten von Twitter analysieren und versuchen eine mögliche Korrelation mit dem Bitcoin Kurs herzustellen.

Hallo Jürgen,
das ist korrekt und ist uns auch vollkommen bewusst. Eine lineare Regression ist in keinster Weise dazu geeignet um die Komplexität des Problems abzubilden. Im Vordergrund unseres Use Cases stand die technische Umsetzung, d.h. der Umgang mit den jeweiligen Technologien. Aus diesem Grund weise ich in meinem Blogbeitrag auch auf folgendes hin: „Uns ist bewusst, dass die Aussage dieser Prognose gering ist. Nichtsdestotrotz eignet sich dieses Beispiel gut, um einen ersten Einblick in die zugehörige Java API zu bekommen.“
Um eine NICHT-Lineare (unbekannte) Funktion zu lernen ist eine Methode die nur lineare Funktionen abbilden kann denkbar die ungünstigste Wahl die man treffen kann…