
Was kann ML.NET und wie kann es verwendet werden?
ML.NET ist ein open source und cross-platform Machine Learning Framework für .NET. Es bietet die Möglichkeit, Machine Learning Modelle zu trainieren oder diese auszuliefern. Zulässige Programmiersprachen sind aktuell C# und F#.
Verwendeter Datensatz
Exemplarisch wird für das Beispiel ein Datensatz der Stadt New York City verwendet. Dieser beinhaltet Daten zu Taxifahrten. Ziel des Versuch soll es sein, die Kosten für Taxifahrten vorherzusagen. Der Datensatz enthält Felder wie zum Beispiel die Anzahl der Passagiere, die Anbieternummer und natürlich den Endpreis der Fahrt.
Getting Started
Zu Beginn muss das Framework installiert werden. Es kann klassisch als NuGet-Package geladen werden.
ModelBuilder-VisualStudio Extension
ML.NET bietet eine Benutzeroberfläche für das Trainieren von Modellen. Diese Extension findet sich hier.
Über Add/Machine Learning lässt sich diese öffnen.
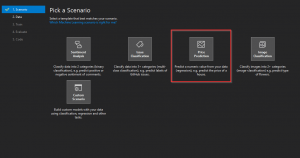
Problemauswahl
Zu Beginn muss die Art des Problems ausgewählt werden. Folgende Klassen sind für die Auswahl verfügbar:
- Binary classification
- Multiclass classification
- Regression
- Image classification
Falls sich zu Beginn nicht abschätzen lässt, welche Klasse von Algorithmus vermutlich am besten funktionieren wird, können unter Custom Scenario verschiedene Algorithmen durchprobiert werden. Hier findest sich eventuell die passende Auswahl.
Wir wählen für den Taxidatensatz das Regressionsproblem (Price Prediction) aus.
Datenauswahl
Für die Auswahl der Trainingsdaten kann aus zwei Quellen gewählt werden:
- .csv oder .tsv
- SQL Server Tabelle
Wir wählen für das Taxi-Beispiel den Typ File, und wählen die .csv-Datei aus.
Anschließend wählen wir für Column to Predict (Label) die Spalte aus, die den Preis der Fahrt angibt (fare_amount).
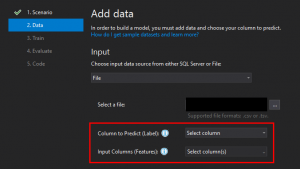
Als Input Columns (Features) wähle ich folgende Spalten:
| VendorID | passenger_count | trip_distance | PULocationID | DOLocationID |
|---|
Training
Für den Vorgang wird die vorgeschlagene Trainingszeit von 60 Minuten genutzt.
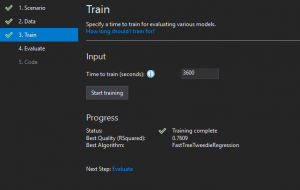
Am Ende erhalten wir den Algorithmus, der am besten für unser Problem funktioniert hat.
Bewertung
Hier können stichprobenartige Tests durchgeführt werden.
Für eine Validierung wurde folgende Route ausgedacht:
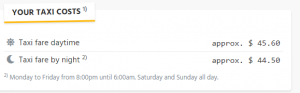
Lässt man diese über einen Online-Taxi-Rechner kalkulieren, erhält man folgendes Ergebnis:
Nun die Vorhersage unseres Modells:

Das scheint Out-of-the-Box bereit, ein akzeptables Ergebnis zu sein.
Dieses ließe sich vermutlich noch weiter verbessern, indem man den Wochentag und die Uhrzeit der Fahrt noch in die Features miteinbezieht, da diese auch Einfluss auf den Preis der Fahrt nehmen.
Export
Nun kann man das Modell in dein Projekt exportieren.
Das Modell wird in Form von auto generiertem Code exportiert und ist als neues Projekt in der Projekt-Solution verfügbar. Anpassungen sind also auch nach dem Export möglich. Es muss allerdings neu trainiert werden.

Mehr Informationen über das Verwenden des Modells im Projekt finden sich hier.
Plain Code
Wenn das Modell komplett manuell über Code erstellt werden soll, gibt es mehr Freiheiten als beim Nutzen der Extension. Eine detaillierte Anleitung, wie das Framework benutzt werden kann, findet sich hier.
Verfügbare Transformationsmethoden
Es sind gängige Methoden wie Normalisierung, Skalierung oder Text-Tokenization verfügbar. Infos zu vielen anderen Datentransformationsmethoden finden sich hier.
Und wie funktioniert das Thema nun im Code?
Datensatz laden
Zu beginn müssen wir unseren Trainingsdatensatz laden.
var mlContext = new MLContext();
IDataView dataSource = mlContext.Data.LoadFromTextFile<CabData>(
"path/to/cab_data.csv",
separatorChar: ',',
hasHeader: true);
class CabData { private float _vendorId;
private float _passengerCount;
private float _tripDistance;
private float _pickupLocationID;
private float _dropoffLocationID;
private float _fare;
// which column to choose from csv?
[LoadColumn(0)]
// column name after loading csv
[ColumnName("VendorID")]
public float VendorId { get => _vendorId; set => _vendorId = value; }
[LoadColumn(3)]
[ColumnName("PassengerCount")]
public float PassengerCount { get => _passengerCount; set => _passengerCount = value; }
[LoadColumn(4)]
[ColumnName("TripDistance")]
public float TripDistance { get => _tripDistance; set => _tripDistance = value; }
[LoadColumn(7)]
[ColumnName("PickupLocationID")]
public float PickupLocationID { get => _pickupLocationID; set => _pickupLocationID = value; }
[LoadColumn(8)]
[ColumnName("DropoffLocationID")]
public float DropoffLocationID { get => _dropoffLocationID; set => _dropoffLocationID = value; } [LoadColumn(10)]
[ColumnName("Label")]
public float Fare { get => _fare; set => _fare = value;
}
Training
ML.NET arbeitet mit sogenannten Pipelines. Hierbei werden bestimmte Aktionen, seien es Schritte beim Training oder bei der Datentransformation vor dem Training, in einer bestimmten Reihenfolge ausgeführt.
Im ersten Schritt wollen wir die Daten transformieren. Wir wenden eine Normalisierung auf die Passagieranzahl an und kodieren die kategorischen Werte VendorID, PickupLocationID, DropoffLocationID mit dem One Hot Encoding.
Zuletzt legen wir noch die Features (=Spalten) fest, die für die Vorhersage verwendet werden sollen.
IEstimator<ITransformer> dataTransoformPipeline = // apply LogMeanVariance normalization to Column PassengerCount mlContext.Transforms.NormalizeLogMeanVariance(inputColumnName: "PassengerCount", outputColumnName: "PassengerCountNormalized") // apply one hot encoding to Columns VendorID, PickupLocationID and DropoffLocationID .Append(mlContext.Transforms.Categorical.OneHotEncoding(inputColumnName: "VendorID", outputColumnName: "VendorIDEncoded")) .Append(mlContext.Transforms.Categorical.OneHotEncoding(inputColumnName: "PickupLocationID", outputColumnName: "PickupLocationIDEncoded")) .Append(mlContext.Transforms.Categorical.OneHotEncoding(inputColumnName: "DropoffLocationID", outputColumnName: "DropoffLocationIDEncoded")) // select features used for prediction .Append(mlContext.Transforms.Concatenate( "Features", "VendorIDEncoded", "PassengerCountNormalized", "TripDistance", "PickupLocationIDEncoded", "DropoffLocationIDEncoded"));IEstimator<ITransformer> trainingPipeline = dataTransoformPipeline.Append(mlContext.Regression.Trainers.Sdca(labelColumnName: "Label"));var filteredTrainingData = mlContext.Data.FilterRowsByColumn(dataSource, columnName: "TripDistance", lowerBound: 0.01f);// split dataset for training & validationTrainTestData splitData = mlContext.Data.TrainTestSplit(filteredTrainingData, 0.1);// start trainingITransformer model = trainingPipeline.Fit(splitData.TrainSet);Bewertung
Nach dem Abschluss des Trainings empfiehlt es sich, die Genauigkeit des Modells zu testen. Anschließend kann dieses exportiert und gespeichert werden.
Wir testen das Modell auf unseren Testdatensatz.
IDataView predictions = model.Transform(splitData.TestSet);
// check model accuracy
var metrics = mlContext.Regression.Evaluate(predictions);
Mit dieser Konfiguration wurde eine Genauigkeit von 87% erreicht. Diese liegt über der Genauigkeit, die vom ML.NET-ModelBuilder erzielt wurde. Man hat hier mehr Freiheiten und kann somit an mehr Parametern drehen, die bei der Nutzung der Extension schlichtweg nicht einstellbar sind.
Hier noch ein Graph, der die Genauigkeit beschreibt:
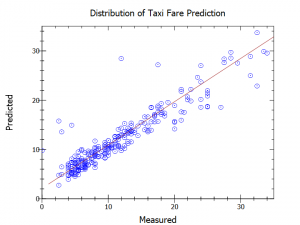
Nun noch zum Vergleich zum oben genannten Preis des Taxi-Rechners.
Prediction forCabData
{
VendorId = 1,
PassengerCount = 1,
TripDistance = 14.9,
PickupLocationID = 153,
DropoffLocationID = 12
}
---------------------------------
Predicted Taxi fare: 46.66$
Somit liegt die Vorhersage des selbst erstellten Modells näher an den geschätzten 45.60$ des Taxi Rechners.
Über eine entsprechende Methode kann das Modell exportiert werden.
// save the model
mlContext.Model.Save(model, dataSource.Schema, "taxi_fare_model.zip");
MLContext loadedMlContext = new MLContext();
DataViewSchema predictionPipelineSchema;
ITransformer trainedModel = loadedMlContext.Model.Load("taxi_fare_model.zip", out predictionPipelineSchema);Über diese Methode können auch Modelle von anderen Frameworks, wie z.B. Tensorflow geladen werden.
ML.NET bietet bereits sehr viele Algorithmen und deckt sehr viele UseCases ab.
Schade ist, dass die neuronalen Netze (bisher) außen vorgelassen wurden. Es gibt noch keine Möglichkeit, neuronale Netze zu erstellen.
Laut Microsoft soll solch ein Feature auch nicht in näherer Zukunft erscheinen.
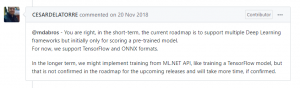
Man muss derzeit also separat ein neuronales Netz-Modell trainieren. Dieses kann dann in ML.NET geladen werden.
Co-Autor: Felix Steck
