
Wie starte ich ein Machine Learning Projekt
Die Digitalisierung und Vernetzung unserer Systeme schreitet mit wachsender Dynamik fort. Die Folge: Fast täglich entstehen neue Möglichkeiten und Trends. Ein weiterer Effekt ist das steigende Volumen an Daten, die von Systemen und Menschen erzeugt und gesammelt werden. Auf dieser Basis hat sich neben Big Data auch die Künstliche Intelligenz zu einem Trend entwickelt, der immer mehr an Bedeutung gewinnt.
Wer im Web zum Thema Künstliche Intelligenz oder zu Machine Learning recherchiert, findet viele Suchergebnisse, Tendenz steigend. Die unten dargestellte Entwicklung der Google-Suchergebnisse zu „Maschinelles Lernen“ im Trend zeigt dies deutlich.
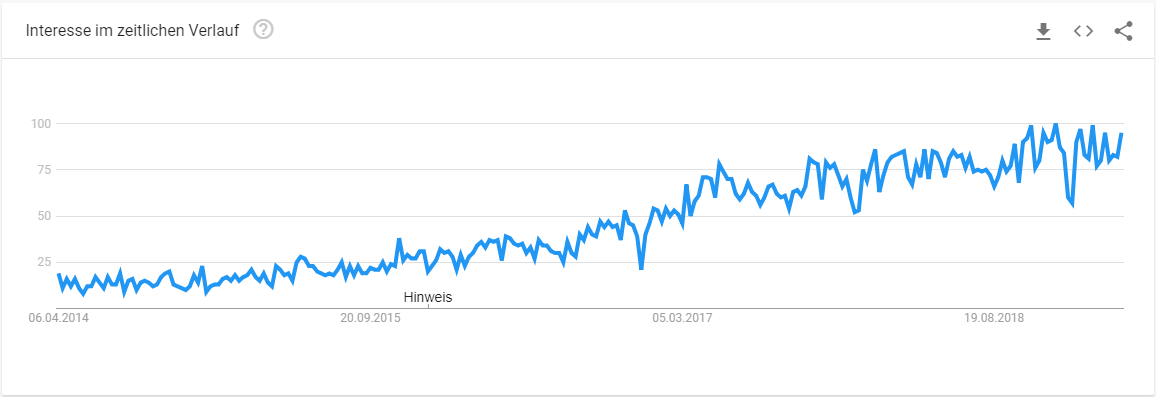
Google Trend – Maschinelles Lernen Machine Learning (ML) ist keine brandneue Technologie. Vielmehr wird auf diesem Gebiet schon seit einigen Jahren geforscht, Frameworks wie Tensorflow oder Keras sind mittlerweile aus dieser Forschung entstanden. In jüngster Zeit nimmt das Thema auch in der Praxis richtig Fahrt auf. Das liegt unter anderem an den folgenden Faktoren:
- Die rasante Steigerung der Rechenleistung in den letzten Jahren.
- Es liegen mittlerweile in vielen Bereichen ausreichend Daten vor, weil Unternehmen mehr Daten erfassen – aus Interaktionen mit Kunden und aus ihren Maschinen.
- KI (Künstliche Intelligenz) hat sich im Consumer-Bereich schon deutlich bewährt, die Kunden erwarten jetzt von Unternehmen in jeder Hinsicht dieselben komfortablen digitalen Optionen.
Wenn wir vom Consumer-Bereich sprechen, sind Anwendungen gemeint, mit denen nahezu jeder von uns bereits Kontakt hatte. Durch Sprachassistenten auf Mobiletelefonen etwa oder durch Soundboxen zuhause wie Alexa oder Siri. Diese Systeme werden von Machine Learning Algorithmen gesteuert, um uns im Alltag zu unterstützen.
Machine Learning – was ist das eigentlich?
Betrachtet man das Thema Machine Learning sehr abstrahiert, könnte man sagen: Es geht darum, dass intelligente Computer oder Server selbstständig Sachverhalte erkennen und adäquate Maßnahmen daraus ableiten oder ausführen. Der Computer soll in die Lage versetzt werden, wie wir Menschen eigenständig und intelligent Daten/Ereignisse miteinander zu verknüpfen und daraus Lösungen für neue, noch nicht gelöste Probleme zu generieren.
Aber wie soll das ein Computer machen?
Basis ist eine Software, die mit selbstlernenden Algorithmen ausgestattet ist und damit versucht, Muster in Daten zu erkennen. Diese Muster nutzt das Programm für weitere Entscheidungen. Die Grundlage müssen wir an dieser Stelle jedoch der Software übermitteln, sie geht sozusagen bei uns in die Schule. Mittels Daten bringen wir der Software bei, welche Muster es gibt und welche möglichen Maßnahmen davon ausgehend durchgeführt werden können. Darauf bauen die selbstlernenden Algorithmen auf und entwickeln neue Muster.
Diese recht abstrahierte Beschreibung verdeutlicht schon sehr gut, was die wesentliche Grundlage für Machine Learning ist: Daten, Daten und nochmals Daten. Dies ist mitunter auch einer der wesentlichen Unterschiede zu anderen Projekten im IT-Bereich. In ML-Projekten müssen wir zu Beginn einen sehr klaren Fokus auf Daten legen und versuchen, diese bestmöglich zu verarbeiten. Je besser wir darin sind, desto besser werden unsere Ergebnisse sein.
Sehr häufig wird der Aufwand unterschätzt, der in die Analyse der Daten und in die Auswahl der entsprechenden Algorithmen gesteckt werden muss. Aus diesem Grund gibt es mittlerweile auch Berufe, die sich ausschließlich mit diesem Thema befassen. So fühlt sich der Data Engineer im Umfeld von Daten zuhause und ist kompetent darin, Daten zu analysieren und entsprechend aufzubereiten. Der Data Scientist hingegen ist für die Auswahl der passenden Algorithmen zuständig: Er bringt Daten, Use Case und Frameworks zusammen und erstellt eine Architektur, die anschließend von Softwareentwicklern umgesetzt wird.
Das nachfolgende Schaubild fasst die beiden Berufsbilder nochmals zusammen:

Abbildung: doubleSlash Net-Business – Profile Data Scientist und Data Engineer
Wo gehört Machine Learning hin und was gibt es noch?
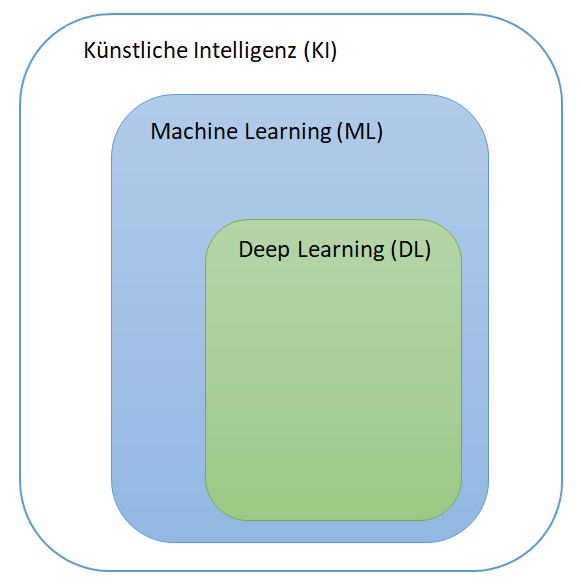
Künstliche Intelligenz (KI):
Das Forschungsgebiet der Künstlichen Intelligenz (KI) befasst sich allgemein mit dem Transfer menschlicher Fähigkeiten auf Maschinen. Hierbei sollen Maschinen unter anderem Aufgaben lösen, die bislang bestimmte kognitive Fähigkeiten des Menschen voraussetzen. Darunter zählt beispielsweise das Erkennen von Sprache, Text und Bildinhalten. Künstliche Intelligenz wird oft als Oberbegriff für Teildisziplinen wie Maschine Learning und Deep Learning genutzt.
Machine Learning (ML):
Hier ermöglicht die Bereitstellung von Daten, dass eine Maschine neue Sachverhalte und eine adäquate Reaktion anhand von Beispielfällen erlernt. Unterschieden wird hierbei zwischen Supervised Machine Learning und Unsupervised Machine Learning. Beim Supervised Machine Learning wird dem Algorithmus während der Lernphase die Bedeutung der bereitgestellten Daten, genauer: die Antwort auf die ihm gestellte konkrete Frage mitgeteilt. Nach der Lernphase kann der Algorithmus dann das Erlernte auf neue, unbekannte Daten übertragen. Unsupervised Machine Learning kommt ohne diese Hilfestellung aus. Der Algorithmus erkennt selbständig wichtige Muster in den Daten und erlernt allgemeine Vorschriften beziehungsweise Regeln unabhängig von einer konkreten Fragestellung.
Deep Learning (DL):
Deep Learning ermöglicht es Maschinen, über die ihnen bereitgestellten Daten hinaus Fähigkeiten zu erlernen. Dabei muss die Maschine beziehungsweise die Software beispielsweise Daten analysieren und bewerten, um daraus logische Schlüsse zu ziehen. Dadurch lassen sich effizientere Lösungswege ermitteln, aus Fehlern kann gelernt werden. Die Anzahl und Qualität der bereitgestellten Daten beeinflusst hierbei stark den Erfolg des Lernvorgangs.
Wie läuft ein Machine Learning Projekt bei doubleSlash ab?
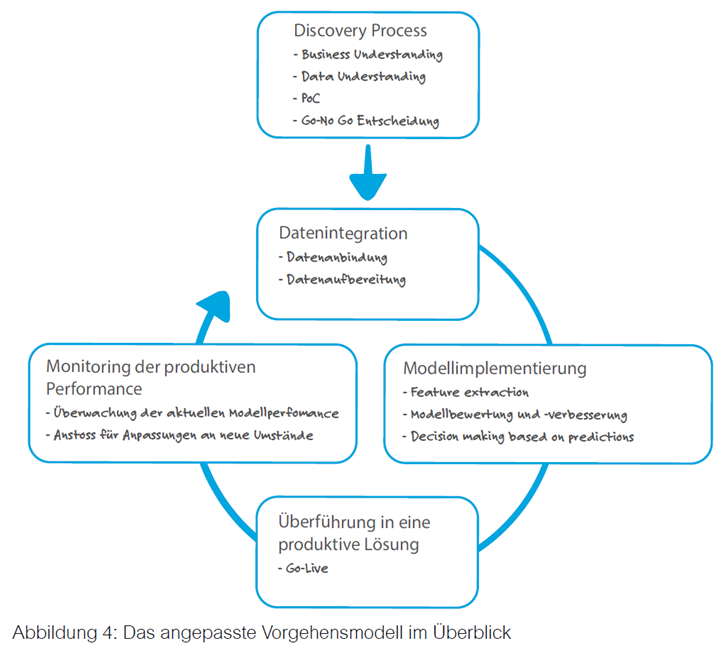
Machine Learning Projekte laufen bei doubleSlash in einem standardisierten Prozess ab, der eine kontinuierliche Verbesserung des entwickelten Machine Learning Modells anstrebt.
Im initialen Discovery Process liegt der Fokus darauf, ein tiefgehendes Verständnis für die vorliegende Problemstellung und die bereitgestellten Daten zu erlangen. Es ist auch bei Machine Learning essenziell, dass man sich über die Problemstellung ausreichend Gedanken macht und daraus Ziele ableitet. Neben der Problemstellung ist es wie erwähnt auch sehr wichtig, die zu verarbeitenden Daten zu verstehen. Dieses Verständnis hat einen wesentlichen Einfluss auf den Erfolg oder Misserfolg eines Machine Learning Projekts. Bei doubleSlash erfolgt beides durch einen Proof of Concept (PoC). Das Ziel des PoC ist es, über die Fortführung des Prozesses auf Basis dieses Verständnisses fundiert zu entscheiden.
Ist die Machbarkeit mittels eines PoC nachgewiesen, folgt im nächsten Schritt die Datenintegration. Das System wird an eine oder mehrere Datenquellen wie beispielsweise Datenbanken oder Maschinen angebunden. Ehe die gesammelten Daten verarbeitet werden können, müssen diese in der Regel eine Datenaufbereitung durchlaufen – zum Beispiel durch Normalisierung, Filterung, Partitionierung und Transformierung.
Um die Komplexität des entstehenden Machine Learning Modells zu verringern, werden die Eingabedaten im Rahmen der Modellimplementierung auf bestimmte Zielattribute beziehungsweise repräsentative Teilmengen reduziert. Das hiernach trainierte Modell wird anschließend validiert, indem Vorhersagen, die das Modell getroffen hat, mit bereits existierenden Daten verglichen werden. Abweichungen zwischen Vorhersage und Realität lassen sich durch das Anpassen unterschiedlicher Parameter und erneutes Training nach und nach minimieren.
Ist die Qualität des Modells zufriedenstellend, fungieren dessen Vorhersagen als Grundlage unternehmerischer Entscheidungen. Das Modell kann in eine produktiv einsetzbare Lösung überführt werden.
Zu beachten: Die bereitgestellten Daten zum Beispiel können sich stets verändern. Eine Überwachung der Performance im produktiven Betrieb ist deshalb unverzichtbar, um das Modell gegebenenfalls rechtzeitig an neue Gegebenheiten anzupassen. Hier schließt sich der Kreis und eine neue Iteration beginnt.
Die nachfolgende Grafik visualisiert dieses angepasste Vorgehensmodell.
Fazit
Machine Learning bietet viel Potenzial, um in Unternehmen bestehende Prozesse zu optimieren und neue Prozesse zu entwickeln. Dieses Potenzial ist keinesfalls auf ein Unternehmenssegment begrenzt, vielmehr lässt es sich in allen Bereichen eines Unternehmens integrieren. Dadurch ergibt sich eine Vielzahl an Anwendungsfällen für Machine Learning. Bei der Planung von Machine Learning Projekten sollte allerdings wie oben beschrieben ein starker Fokus auf die Daten gelegt werden, denn diese haben einen entscheidenden Einfluss auf den Erfolg oder Misserfolg eines ML-Projekts. Zu den Daten kommen die Kenntnisse und Kompetenzen des Projektteams. Beide zusammen sind die für den Verlauf und damit auch den Erfolg des Projekts zentralen Faktoren.
Wollen Sie mehr erfahren oder das angepasste Vorgehensmodell für Ihr Machine Learning Projekt nutzen?
