
Extracting structured data from fuel receipts: finally making travel expense accounting efficient
12 million business travelers in 2018 according to the 2019 business travel analysis by VDR (Verband Deutsches Reisemanagement e.V.)1 and therefore a whole mountain of travel expense reports to process - for employees and companies. However, in times of AI and digitalization, only 13% of the companies surveyed (10-500 employees) implement a complete digital travel expense report 1. Even at our company - a software company - travel expense accounting is not yet fully automated. For this reason, we have written a thesis on possible methods of information extraction in order to digitize this process.
Lack of standardization hinders automation process
A partial problem with full automation is the lack of standardization for invoices for very small amounts - also known as receipts. This made it extremely difficult to automatically extract the required data. It was time to digitize the process by implementing a system for automatically extracting data from fuel receipts. The system is divided into three sub-problems that need to be solved:
Pre-processing of the input image
The first step in digitizing a document is to convert the printed paper into a file. Either a scanner or a photo camera can be used for this. The result of both processes is an image file. Here is an example taken with a cell phone camera:

In order to optimize this image for text extraction, it must be converted into its binary representation - this is achieved by so-called binarization. The aim of binarization is to ensure that all pixels only have the values "one" (foreground / text) or "zero" (background). This allows the text to be separated from the background. The prerequisite for this is an image in greyscale, as binarization attempts to calculate a threshold for grey values so that a pixel can be clearly identified as "one" or "zero". Binarization methods can be divided into two approaches: A global approach attempts to find a threshold for the entire image. A local approach, on the other hand, attempts to find a threshold for small sections of the image. But when to use which method? Global approaches are good if the image has a uniform brightness. However, this is not the case due to the photos taken by the camera. We have therefore determined that a local binarization approach must be implemented in the system. After applying a binarization using Sauvola's method - an adaptive binarization method that binarizes documents using locally adaptive thresholds - the image is available in its binary representation:

Another important pre-processing procedure is the correction of the tilt angle if the image was scanned or photographed at an angle. This correction can make it much easier to find lines of text. For this purpose, we have implemented a line detection function in the system. This searches for contiguous lines of text and displays them as a line. The angle of inclination can then be calculated by averaging all the angles of these lines relative to the x-axis. The document must then be rotated at the inverse angle. Correcting the angle of inclination significantly improves the quality of the text extraction. See for yourself:
 |
 |
Source: https://www.kress.eu/de/news/309-deutliche-kraftstoffersparnis-erneut-nachgewiesen.html
Reading out the text
The conversion of scanned or photographed images into machine-readable text is called Optical Character Recognition (OCR). This technology makes it possible to have images with textual content recognized by computer systems. A popular solution for this is the open source OCR engine Tesseract. The engine was originally developed by HP and has been maintained and expanded by Google since 20062.
To use Tesseract, the Apache Tika Toolkit can be used. This toolkit offers various parsers for extracting data, including the TesseractOCRParser. It enables the Tesseract OCR engine to be easily coupled to a Java application.
Extraction of relevant information
As the text is now available in machine-readable form, the system must perform the actual information extraction. One library for finding structured information in unstructured text is Apache UIMA (Unstructured Information Management Architecture). The library offers interfaces to the programming languages C++ and Java. UIMA can be used to develop annotators that extract information from unstructured text on the basis of regular expressions, for example.
All components within UIMA communicate using the Common Analysis Structure (CAS). The CAS is a subsystem in UIMA that enables data exchange between UIMA components3. A TypeSystem is defined within the CAS, which contains all the data types that are to be extracted. In our case of the fuel receipts, this would be the data types Sum, Date, Time, Quantity (number of liters), Type (fuel type) and Address. The corresponding regular expressions are stored for these data types in the annotator mentioned above.
In the next step, the document text determined in the previous step is entered into the CAS. The annotator now searches the document text stored in the CAS and saves the start and end position in the text where the respective data type can be found. The CAS can then be searched for these data types, i.e. the structured information. An example of information extraction with Apache UIMA from the document photo (see above) is shown below:
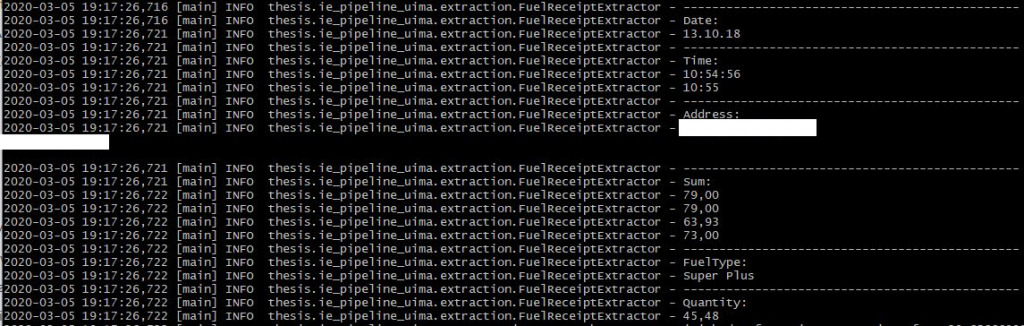
It can be seen that all data can be extracted correctly except for the total amount. This is due to the difficulty of developing a regular expression that does not extract all euro amounts, but only the desired one. An AI system performs better with non-normalized data such as the total amount, as the existing textual context (e.g. the position in the overall text) can be included in the classification.
Conclusion
The system for extracting structured data from fuel receipts has thus been completed and will make travel expense accounting much easier in future.
The most important pre-processing steps in the digitization of analogue documents are binarization and subsequent correction of the tilt angle, as otherwise text recognition may deliver significantly poorer results. If documents are available that have different degrees of brightness, a local binarization process must be used instead of a global one.
The quality of information extraction depends heavily on the regular expressions developed for the respective data type. It can be stated that even in times of artificial intelligence, rule-based information extraction still has a right to exist, as many data (such as date and time) are standardized and therefore unique regular expressions can be used for information extraction. By connecting the system to the cloud solution "Business Filemanager", fuel receipts can even be uploaded and read directly while on the move and thus made available to the travel expenses department.
P.S.: We have found a solution that we have not programmed ourselves, but which we use a lot: the Lunchit® app. It's the same approach but for lunch receipts. Since we started using Lunchit®, we have saved a lot of time in administration. We no longer have to issue meal vouchers and settle them with the restaurants. Another plus point: employees also save time by using the app, as there are no more receipts or tokens to collect, take away and count.
And what about you - are you still typing expense reports manually or are you already digitizing? Share your experiences with us by leaving a comment.
1st source: https: //www.vdr-service.de/fileadmin/services-leistungen/fachmedien/geschaeftsreiseanalyse/VDR-Geschaeftsreiseanalyse-2019.pdf
