
Beiträge von Simon Kitzberger
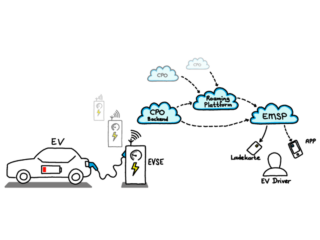
Wie funktioniert öffentliche Ladeinfrastruktur?
18.05.2022 –
Die Elektromobilität und die damit notwendige Ladeinfrastruktur, sind ein viel diskutiertes Thema. Was muss zuerst ausreichend verfügbar sein, damit die Akzeptanz von Elektrofahrzeugen zunimmt? Elektroautos oder die Lademöglichkeiten?
weiterlesen
doubleSlash Erfahrungsbericht zur Elektromobilität
08.11.2021 –
Wir beschäftigen uns nicht nur bei der Arbeit mit modernen und zukunftsweisenden Themen. Auch im Privaten lassen wir uns für Themen, wie zum Beispiel die Elektromobilität begeistern.
weiterlesen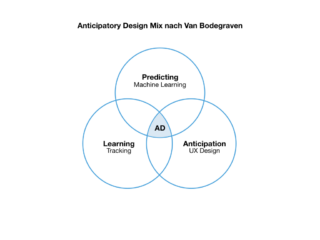
Predictive User Experience in Business Anwendungen
18.01.2021 –
Laut einer Studie1 beschäftigen sich bereits die Hälfte der deutschen Unternehmen mit dem Thema KI und deren Anwendung in Geschäftsprozessen und in Form neuer Produkte – Tendenz steigend.
weiterlesen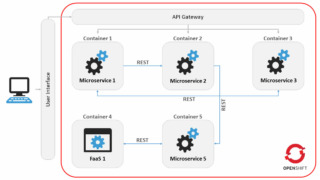
Application Performance Monitoring (APM) von Microservices und FaaS in OpenShift
08.01.2020 – Autonome Fahrfunktionen werden immer komplexer und auch die Zahl der Servicefunktionen im Fahrzeug wächst. Da ist es gerade in der...
weiterlesen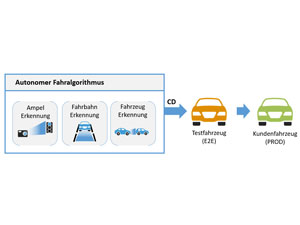
Codequalität für autonome Fahralgorithmen gewährleisten
09.12.2019 – Die Entwicklung autonomer Fahrzeuge ist ein Wettrennen, daher müssen schnellstmöglich stabile Algorithmen für das autonome Fahren entwickelt werden. Dafür müssen...
weiterlesen