
Docker Swarm: Container-Orchestration leicht gemacht
In den letzten Jahren und Monaten hat sich in der IT-Welt ein neuer Trend etabliert – die „Containerisierung“ von Anwendungen. Ziel des Ganzen ist, verschiedene Anwendungen auf einem System zu trennen und in sogenannte Container zu verpacken – und somit diese Container vom System selbst zu trennen. Wenn alle Anwendungen, Module und Apps in Containern verpackt sind, lassen sie sich schnell und einfach auf andere Systeme verladen. Die getrennte Kapselung vom Rest des Systems garantiert eine lauffähige und portable System- Umgebung.
Ein Auslöser für diese Bewegung ist zweifelsohne das Container-Tool Docker, das mit seiner geschickten und einfachen Anwendung schnell große Verbreitung erlangt hat. Nachdem bereits andere Technologien wie Google’s Kubernetes, Apache’s Mesosphere Marathon oder CoreOS‘ Fleet fürs Container-Management entwickelt wurden, hat der Platzhirsch unter den Containerbauern mit einer Eigenentwicklung nachgezogen – Docker Swarm:
Was ist Docker Swarm?
Hauptsächlich verwaltet Swarm die Kommunikation der Mitglieder des Clusters und erlaubt die Verteilung von Containern mit verschiedenen Services an verschiedene Hosts. Swarm wird von Docker selbst als fertig verpackter Microservice innerhalb eines Containers angeboten, d.h. um einen Swarm Cluster zu erstellen benötigt man (zusätzlich zur restlichen Docker Infrastruktur) nur den offiziellen Dockercontainer, der mit ‚docker pull swarm‘ angelegt wird. Das heißt im Klartext, Docker bietet Swarm direkt als Microservice-Container an. Dieser kann via Docker CLI mit diversen verschiedenen Parametern und Funktionen aufgerufen werden um einen Cluster aufzubauen und zu konfigurieren.

Was macht Docker Swarm?
Swarm erlaubt das Verknüpfen verschiener Hosts zu einem Cluster. Dadurch kann eine beliebige Anzahl Container auf einer beliebigen Anzahl virtueller oder physischer Hosts verteilt werden, während die komplette Steuerung des Clusters zentral von einer als „master“ definierten Maschine abläuft. Dieser master kann auch redundant initialisiert werden um die fail-safety zu erhöhen und ein nahezu reibungsloses Weiterlaufen des Clusters zu ermöglichen, sollte einer der master nodes versagen.
Wie stelle ich mir so einen Cluster vor? Gibt es gute Beispiele?
Was man alles in einen Swarm packen kann ist im Prinzip der Fantasie des Erschaffenden überlassen. Ein klassischer Use-Case jedoch ist eine Http-Annahme mit Loadbalancing, bei der Frontend, Verarbeitung und Persistenz (siehe Mean-Stack und Variationen) in getrennten Containern auf verschiedenen Maschinen realisiert werden.
Genau das wurde in folgendes Beispielcluster eingebaut: Loadbalancing mit Nginx-Frontend, Angular NodeJS als Verarbeitungskomponente und Redis als Persistenz. Fast wie MEAN nur … RNN.
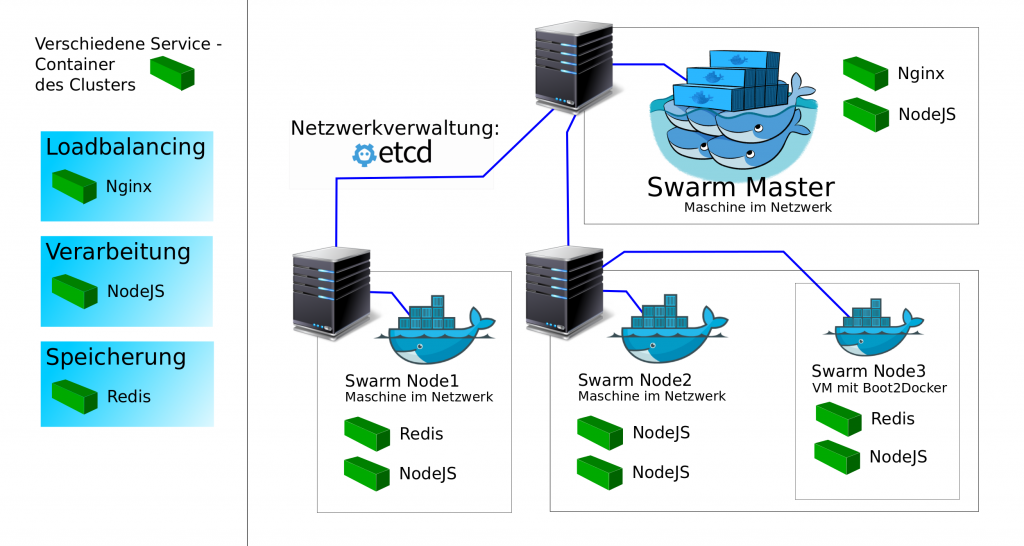
Was hat Docker-Compose mit allem zu tun?
Mit Docker-Compose können komplexe Strukturen aus mehreren Containern und Netzwerken komfortabel in einem zentralen Dokument verwaltet werden. Diese sogenannte „docker-compose.yml“ enthält unter anderem Informationen zu:
- Images oder Dockerfiles, auf denen zu bauende Container basieren
- Abhängigkeiten der Container
- Umgebungsvariablen wie Constraints, um beispielsweise die Auswahl eines Hosts für einen bestimmten Container einzuschränken
- Port-mapping
- Verschiedene Overlays (Hostübergreifende Netzwerke)
Ergo: Docker-Compose ist das Tool, mit dem ein Swarm am effizientesten „bevölkert“ werden kann.
Der entscheidende Vorteil von Compose in Kombination mit Swarm ist das automatische Deployment von vernetzten Containerstrukturen und die einfache Skalierung. Nach dem Aufbau via ‚docker-compose up‘ im Swarm Master werden alle Container auf die verschiedenen Hosts verteilt und können mit ‚docker-compose scale‘ ohne großen Aufwand skaliert werden. Swarm verteilt diese Container wiederum nach dem „der am wenigsten beladene bekommt den nächsten Container“ – Prinzip und das Deployment der neuen Container läuft dynamisch und automatisiert. Besonders praktisch: Die Netzwerke werden automatisch an die neue Situation angepasst, verschwundene Container werden nicht mehr angesprochen und neue Container werden ins Netzwerk eingebunden – sofern ein Key-Value Container eingerichtet wurde.
Key-Value Container? Wozu braucht Swarm Drittsoftware?
Mit sogenannten Overlay-Netzwerken hat Docker ein Tool geschaffen, um ein grundlegendes Problem zu umgehen: Ein Multi-Host Cluster lässt keine herkömmliche Adressbasierte Netzwerkkommunikation zu.
Docker weist jedem Container eine IP zu, die für die lokale Kommunikation benutzt werden kann. Verlässt man den lokalen scope, sind die Container an die IP des Hosts gebunden und deswegen zum Verbindungsaufbau auf port-mapping angewiesen. Das macht es Anwendungen schwierig, eine „externe IP-Adresse“ zu bestimmen – da diese Adresse die lokale Adresse des Containers ist – die im Netzwerk nicht routbar ist.
Um es zu verdeutlichen: Auf einem Host läuft eine virtuelle Maschine, in dieser läuft ein Container – und darin läuft ein Service. Diesem Service zu ermöglichen, reibungslos mit anderen Services aus einem Container in einer VM auf einer anderen Maschine zu kommunizieren gehört definitiv zu den kniffligsten Aufgaben, die Container Clustering zu bieten hat.
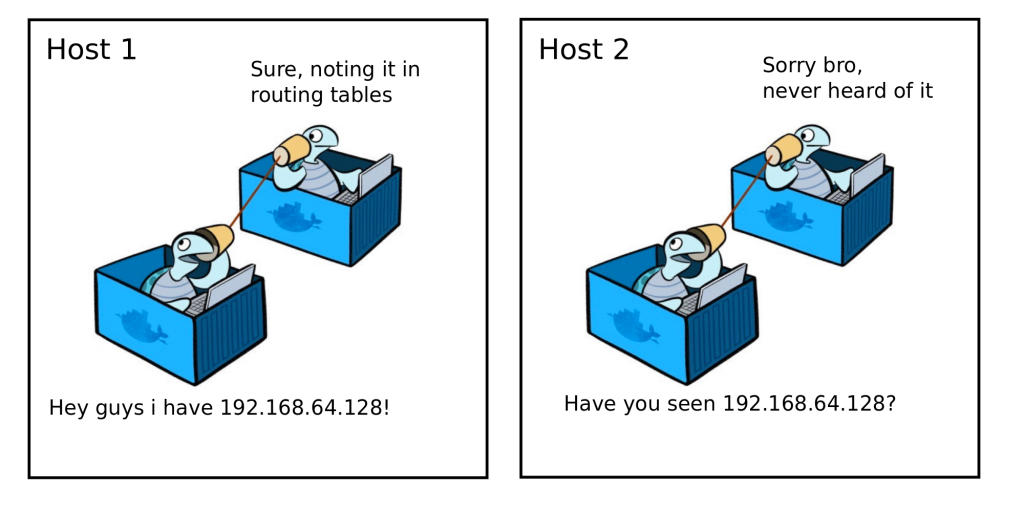
Abhilfe verschafft ein Key-Value Store als Backend, das Netzwerkstatus, network – discovery – Informationen, Endpunkte und IPs speichert. Das korrekt zu implementieren erfordert sowohl Know-How im Umgang mit Docker als auch mit Third-Party-Software wie etcd, Consul oder Apache Zookeeper. Vor allem da der Cluster ein dynamisches Konstrukt ist, dass sich verändert – und dessen Netzwerk sich in Echtzeit anpassen muss.
Momentan gibt es leider noch keine einfache Lösung für dieses Problem. Die Netzwerkeinrichtung ist nach wie vor eine der Schwierigkeiten bei Docker Swarm.
Fazit: Einen Swarm zu deployen ist nicht schwer, ihn zu bauen dagegen sehr
So einfach sich Docker bedienen lässt, einen effektiven Swarm Cluster aufzubauen ist kein Spaziergang durch eine grafische Oberfläche. Es gibt Lösungen wie z.Bsp. Rancher, die solche grafischen Oberflächen anbieten – diese nehmen aber keine Komplexität aus der Materie, sondern vereinfachen die Bedienung und insbesondere die Live-Überwachung. Momentan gibt es also noch kein Tool, das den Clusteraufbau „aus einem Guss“ erlaubt, ohne eine gewisse Expertise mitzubringen.
Ist aber der Swarm-Cluster einmal fertig aufgesetzt, bietet dieser ein breites Spektrum an Vorteilen und Möglichkeiten.
Was Docker Swarm zu bieten hat:
- Der komplette Aufbau des Swarms ist vollkommen unabhängig von der Hardware und den Systemen, auf denen es eingesetzt wird
- Swarm wird selbst als Microservice – Container angeboten: schnell, einfach und unbeschwert eingesetzt
- Autonomität des ganzen Clusters ist nach korrekter Konfiguration hervorragend
- Verteilung & Scaling der Services ist mit Compose elegant gelöst
- Das Docker – Netzwerk passt sich den Gegebenheiten im Cluster einwandfrei an
- Fertige Cluster sind sehr schnell und ohne großen techninschen Aufwand deployed
- Das komplette Docker – Projekt ist Open Source
- Docker entwickelt sich – die ganze Infrastruktur wird permanent um Funktionen erweitert und um Bugs erleichtert
Problematische Gesichtspunkte:
- Die Containertechnologie steckt noch in den Startlöchern; sehr jung und dementsprechend nicht ausgereift
- Einen Cluster neu zu erstellen erzeugt einen gewissen zusätzlichen Aufwand (im Vergleich zu herkömmlichem deployment)
- Networking im Cluster erfordert einen tieferen Einstieg in die Materie und die Hilfe weiterer Software
- Docker befindet sich in einem schnellen Entwicklunsstadium – Vorgehensweisen, die momentan valide sind, sind es in einigen Monaten eventuell nicht mehr
- Penetration Security ist (momentan) schwach
Unterm Schlussstrich
Security bei Docker ist ein heikles Thema. Es gibt unzählige Blogs und Berichte von Unternehmen, die sich mit den Securtiy – Flaws von Docker auseinandergesetzt haben. Von Privilege-Escalation aus dem Container auf den Host, über Isolationsprobleme, die Kernel-Exploits aus Containern ermöglichen, bis zu einfachen Ansätzen für einen klassischen effektiven Denial-of-Service – die Liste ist lang. Diese Lücken zu nutzen sind keineswegs Raketenwissenschaften, wie dieser Beitrag eines „Features“ von Docker zeigt. Hacker werden in Docker eventuell sogar einen Angriffsvektor sehen.
Das Team hinter Docker arbeitet an Patches für diese Lücken und macht sich Know-How der Community zunutze, doch wie so oft bei einer neuen Entwicklung sind Sicherheit und Dokumentation etwas, das der Innovation hinterherhinkt. Wer Sicherheit will, wird sich wohl in nächster Zeit über momentane Schwachstellen informieren müssen – und selbst Hand anlegen. Glücklicherweise gibt es auch hierzu gute Hilfestellung.
Doch die Experten sind sich einig: Containertechnologien und -software gewinnen immer mehr Raum. Der technische Höhepunkt ist noch lange nicht erreicht, und das Potential ist nur teilweise erfasst. Die Containerfront hat bereits zu viele ernsthafte Investoren und Entwicklungen hervorgebracht um noch sagen zu können, dass sich keine Lösung für Probleme finden wird, die im Moment noch existieren.
