
Goldrausch: Wie man mit dem CRISP-Datenmodell den Schatz im Datenklumpen findet
Jeder kennt mittlerweile den viel zitierten Satz „Daten sind das neue Gold“. Das trifft allerdings nur zu, wenn man das Gold in dem Datenklumpen findet und extrahieren kann – und sich nicht mit möglicherweise voreiligen Schlüssen zufrieden gibt. Je nach Datenumfang und -verfügbarkeit können innerhalb weniger Minuten in einem Visualisierungstool verblüffende oder auch erwartete Abhängigkeiten gezeigt werden. Inwieweit aggregierte und eindimensionale Betrachtungen allerdings die Realität widerspiegeln, erfordert eine eingehendere Betrachtung.
Um das Gold im Datenklumpen zu finden empfiehlt sich eine strukturierte und mindestens in Teilen ergebnisoffene Vorgehensweise. Sie ist im CRISP-DM (CRoss-Industry Standard Process for Data Mining), dem Standard-Prozess-Modell für Data Mining, beschrieben. Die Phasen sind auf Data Mining Fragestellungen bezogen, das Modell kann allerdings bei allen Datenanalyseprojekten mit verschiedenen Schwerpunkten und Anpassungen angewendet werden. Die Phase „Modellierung“ fällt gegebenenfalls geringer aus oder ganz weg und die Phase der „Evaluation“ gewinnt mit der Visualisierung an Bedeutung.
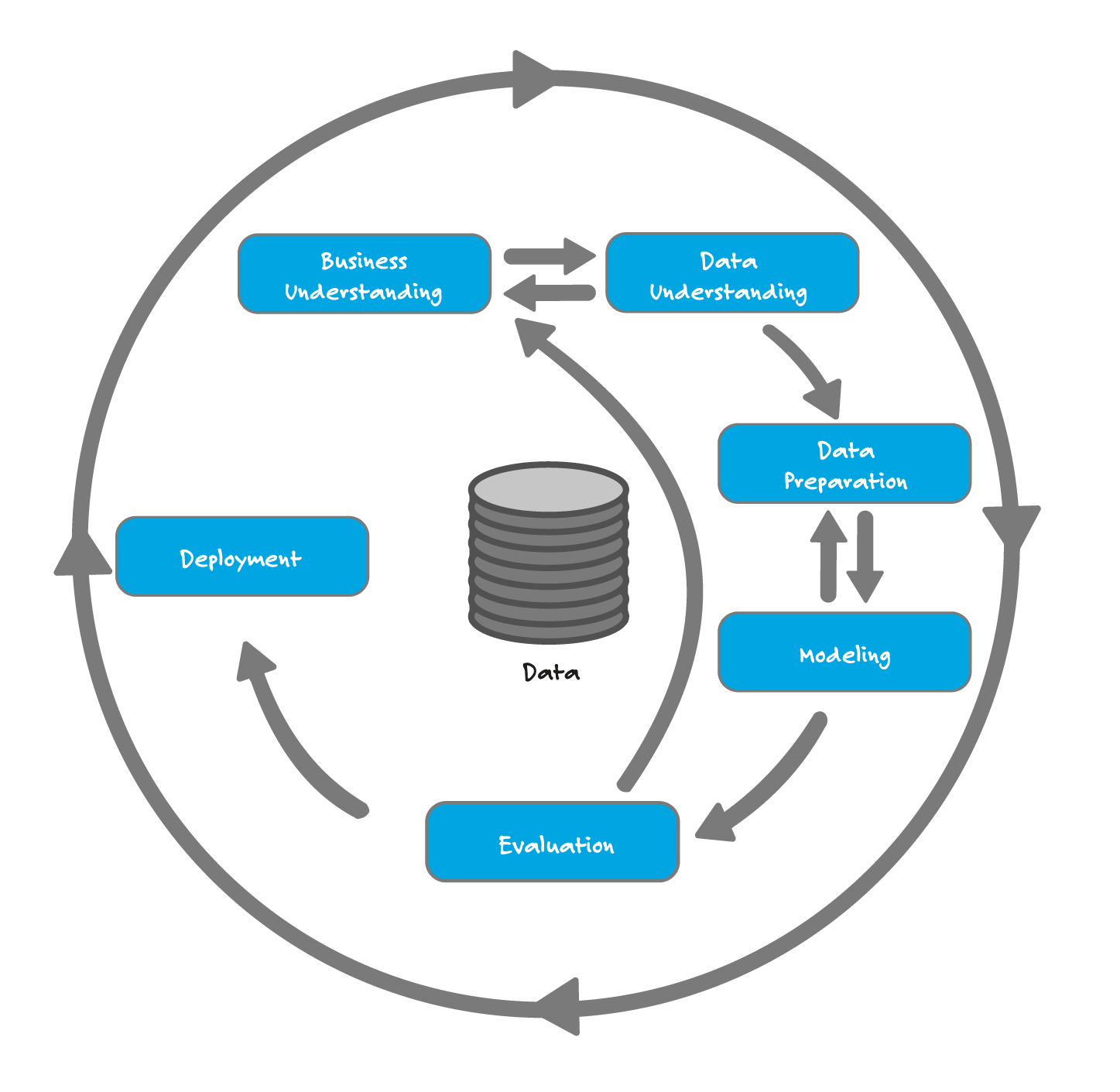
Daten analysieren heißt Prozesse und Daten verstehen
Zunächst startet jedes Datenanalyseprojekt mit dem Verständnis von Prozessen und Geschäftsvorgängen. Dabei erschließt sich dem Analysten die Herkunft von Daten und deren betriebswirtschaftliche Bedeutung. Möglicherweise liegen auch bereits sehr genaue Fragestellungen des Kunden vor.
In der CRISP-Phase des Datenverständnisses werden Daten erstmals genauer gesichtet. Hier ist es je nach Datenumfang sinnvoll, ein geeignetes Visualisierungstool einzusetzen, weil so Verteilungen, Zusammenhänge und auch Lücken schnell sichtbar werden.
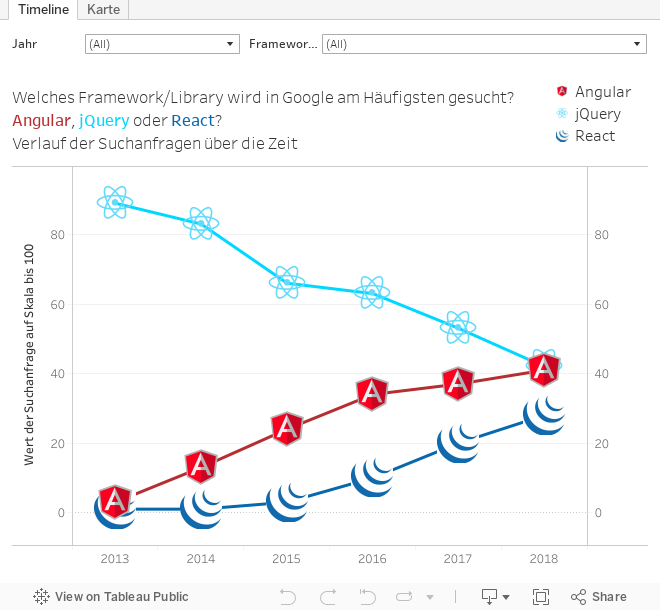
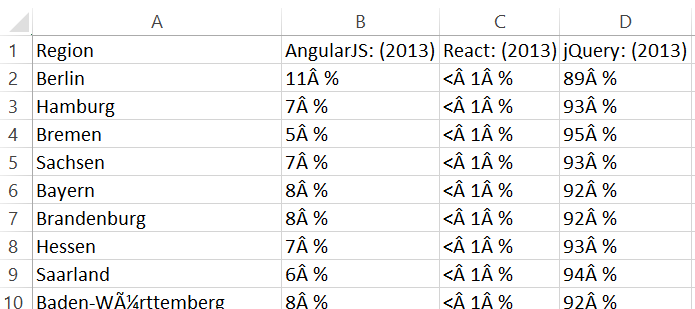
Das zeigt ein kleiner Beispieldatensatz aus Google Trends mit vergleichenden Suchverläufen zu Frameworks und Libraries in der Frontendentwicklung. Bei der ausschließlichen Betrachtung des Zeitverlaufs scheint sich ein klares Bild zu ergeben. Die Library jQuery ist führend, in 2018 gibt es einen Schnittpunkt mit dem Framework Angular.
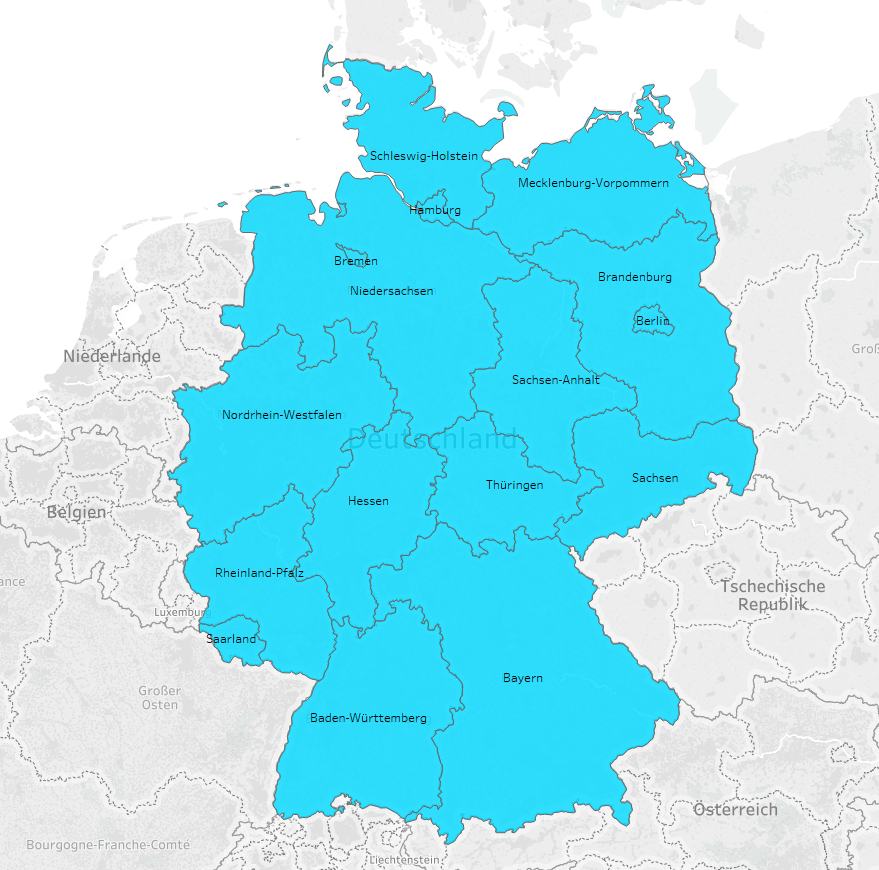
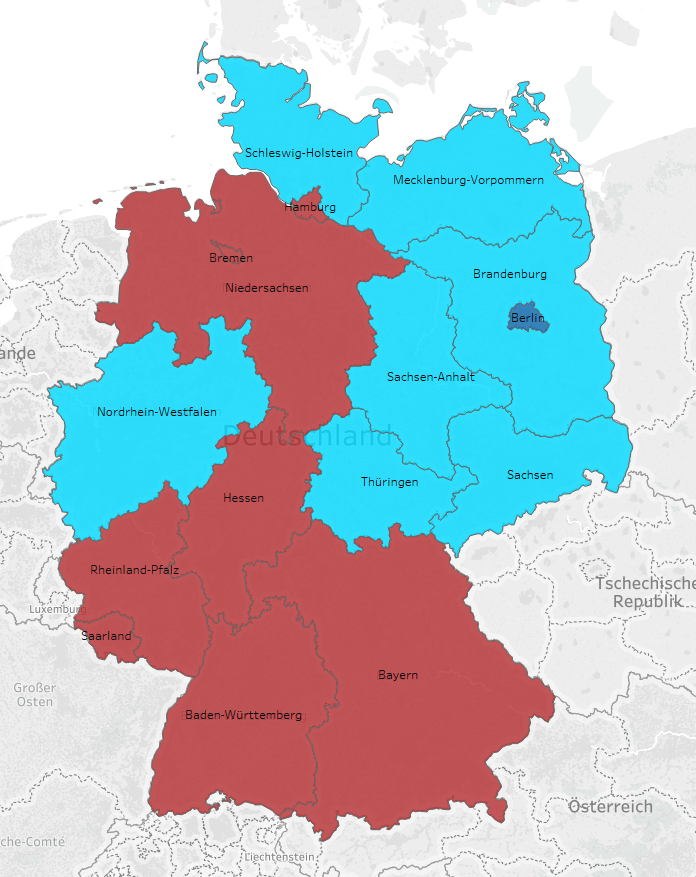
Ebenso bei der ausschließlichen Betrachtung von Regionen scheint die jQuery Library aus dem Beispieldatensatz von Google Trends ebenfalls führend zu sein.
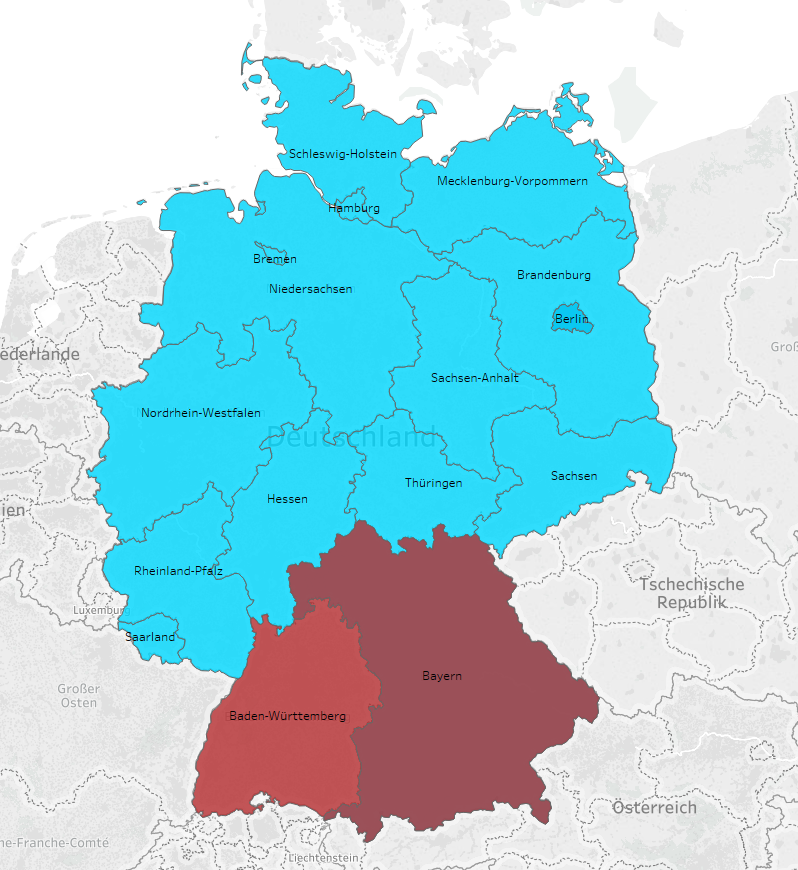
Bei der zeitlichen und bundeslandbezogenen Betrachtung zeigen sich jedoch regional Unterschiede (2017 bzw. 2018).
Die Phase des Datenverständnisses ist sehr wichtig für verlässliche Ergebnisse, da auf der Analyse später betriebswirtschaftliche Entscheidungen basieren sollen. Möglicherweise zeigt sich auch, dass die Datengrundlage für verlässliche Auswertungen und Entscheidungen nicht ausreicht, weil z.B. Spalten unzureichend befüllt sind oder kein eindeutiges Mapping zu anderen Daten sichergestellt werden kann. Dann kann man sich auf die Suche nach weiteren Datenquellen machen, mit denen die Lücken geschlossen werden können.
Die Datenvorbereitung – oft der aufwändigste Teil eines Datenprojekts
Die Erkenntnisse aus dem Datenverständnis werden in der nächsten CRISP-Phase der Datenvorbereitung genutzt. Bereits mit sehr klaren Fragestellungen und kleinem Datenumfang ist Datenverständnis und -vorbereitung oft der aufwändigste Teil eines Datenprojekts –ohne dass für den Anwender im Frontend schon Ergebnisse sichtbar sind. Herausfordernd in der Analyse sind unstrukturierte Daten, die mit strukturierten Daten in Verbindung gebracht werden sollen. Es müssen beispielsweise relevante Datenfelder gewählt und gegebenenfalls mit Feldern aus anderen Tabellen eindeutig in Beziehung gebracht werden. Oder es gilt, viele einzelne Tabellen in eine zusammen zu fassen, Tabellen zu transformieren und über Ausreißer und fehlende Werte zu entscheiden.
In unserem Beispiel wurden die Daten transformiert und zum Teil zusammengefasst, um sie für die Visualisierung besser nutzbar zu machen.
Datenvisualisierung: Ergebnisse werden für den Anwender sichtbar gemacht
In der Phase der Modellierung nutzt man verschiedene Data Mining Techniken und Methoden.
In der Phase der Evaluation werden Ergebnisse visualisiert und damit auch für einen späteren Anwender sichtbar gemacht, sodass ein Abgleich mit dem Prozessverständnis aus dem ersten Schritt stattfindet. Es wird geprüft, ob Antworten gegeben werden konnten bzw. was offen und in der nächsten Schleife zu analysieren ist. Weitergehende Fragen entstehen nicht selten mit der Beantwortung einer Ausgangsfrage. Es kann auch sein, dass in der Phase des Datenverständnisses auffiel, dass die Daten nur stark aggregiert vorliegen und keine Rückschlüsse auf die dahinterliegende Qualität möglich sind.
Im Beispiel der Google Trends Daten ist das der Fall. Zudem bezieht sich die Auswertung ohnehin nur auf Suchanfragen in Google, zum Vergleich müssten andere Suchmaschinendaten herangezogen werden. Möglicherweise ist auch die Verbreitung der Suchmaschinen so angelegt, dass die Ergebnisse aufgrund fehlender Grundlage verfälscht sind. Deshalb sollte mit Vorsicht interpretiert werden. Im betrieblichen Kontext ist zu beachten, dass vermeintliche Kausalitäten und schlüssige Vorhersagen nicht immer betriebswirtschaftlich sinnvoll sein müssen, auch dies wird im Abgleich mit dem Geschäftsprozess hinterfragt.
Nach dem Rückgriff auf die Geschäftsprozesse steht das Deployment an, d.h. die Anwendung der Modelle bzw. Auswertungen in der Unternehmenssteuerung. Gerade zu Beginn der Analyse von noch unbekannten Datenquellen wird nicht bei jeder Iteration ein eine präsentierbare Analyse vorhanden sein. Um sich nicht in Endlosschleifen zu verlaufen ist es trotzdem ratsam, möglichst bald eine erste Analyseversion zu übergeben, die dann in weiteren Schleifen verfeinert oder erweitert wird.
Was macht eigentlich ein Data Scientist? Wir haben nachgefragt. Hier mehr über das Berufsbild erfahren
