
Machine Learning Operations (MLOps): Das Erfolgskonzept für produktive und skalierbare KI-Lösungen
Machine Learning Lösungen finden ihren Weg in immer neue Anwendungsbereiche – gerade auch in der Industrie. Hier werden mittlerweile schnell erste Ansätze getestet und Proof-of-Concept-Modelle entwickelt. Doch wie können diese Modelle nun produktiv auch genutzt werden?
Für den erfolgreichen, produktiven Betrieb von Machine Learning Modellen existiert ein eigener Ansatz: Machine Learning Operations, oder abgekürzt: MLOps. MLOps umfasst dabei drei Begriffe:
- Machine Learning
- Softwareentwicklung (Software Development)
- Betrieb (Operations)
MLOps lernt von DevOps, hat aber spezielle Anforderungen
Die Kombination aus Sofware Development und Operations ist schon lange wohlbekannt und hat als „DevOps“ die IT-Branche nachhaltig verändert. Die durch DevOps etablierten Konzepte bilden die Grundlage für MLOps, es werden dort bereits erprobte Methoden der Softwareentwicklung und des Softwarebetriebs genutzt. Zu den speziellen Anforderungen von MLOps gehören:
- Reproduzierbarkeit und Nachverfolgbarkeit: Versionierung gehört zum kleinen Einmaleins der Softwareentwicklung. Doch die gleiche Anforderung gilt auch für Machine Learning: Sowohl die erstellten Modelle, als auch die genutzten Daten müssen versioniert sein. Nur so können Ergebnisse reproduziert und nachverfolgt werden.
- Skalierung: Machine Learning Modelle müssen zunächst erstellt (trainiert) und später dann als Service angeboten werden. Beides erfordert das dynamische Bereitstellen von Hardwareressourcen. Aber besonders für das Training gilt es häufig, für einen begrenzten Zeitraum viele Ressourcen bereitzustellen. Das ist nur mit einer gut skalierbaren Lösung erreichbar.
- Monitoring: Natürlich muss zunächst ganz klassisch die Verfügbarkeit der Machine Learning Services überwacht werden („Läuft der Service überhaupt?“). Aber darüber hinaus erzeugt der Service laufend Modellvorhersagen – diese können mit der Zeit in ihrer Qualität abnehmen. Sofern es der Anwendungsfall erlaubt, sollte deswegen konstant die Vorhersagequalität überwacht werden.
- Wiederverwendbarkeit und Standardisierung: Von den Daten bis zu einer Vorhersage müssen einige Schritte durchlaufen werden. Grundsätzlich gehören dazu: Datensammlung, Datenaufbereitung, Training und Vorhersage. Durch Standardisierung und eine saubere Trennung der Einzelschritte ist es wahrscheinlicher, dass Einzelkomponenten auch projektübergreifend verwendet werden können.
MLOps Lifecycle: Vom Proof of Concept zu skalierfähigen KI Anwendungen
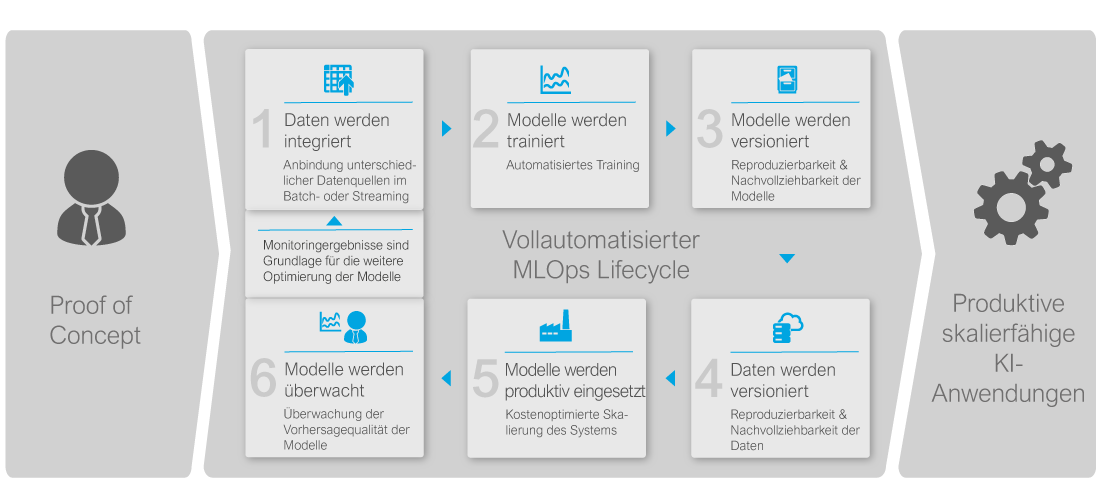
Wie können diese Anforderungen erfüllt werden? Mit Hilfe von Pipelines wird ein vollautomatisierter MLOps Lifecycle erfolgreich abgedeckt. Der komplette Lebenszyklus ist in Abbildung 1 dargestellt:
Die Daten werden zunächst gesammelt und aufbereitet. Hiermit kann nun ein Modell trainiert werden, wobei mitgespeichert wird, mit welchem exakten Datensatz das Modell trainiert wurde. Das Modell selbst wird als Container gepackt und in einer Containerregistry versioniert. Dieses Modell kann nun automatisiert ausgerollt werden und steht direkt zur Nutzung als Service bereit. Die Performance der Vorhersagen, aber auch die technische Verfügbarkeit des Service können durch entsprechende Monitoringlösungen überwacht werden. Wird die Vorhersagequalität des Modells zu schlecht, oder verändern sich die neu gesammelten Daten („Data Drift“), kann nun zum Beispiel ein automatisiertes, erneutes Trainieren des Modells angestoßen werden und der Lebenszyklus beginnt von Neuem.
Anbieter von MLOps Lösungen bieten gute Basis
Nicht immer ist eine vollumfängliche MLOps-Lösung wünschenswert oder sinnvoll. Machine Learning Operations ist ein abgestuftes Konzept. Je nach Anwendungsfall sollte ein bedarfsgerechtes Konzept entworfen werden, das evaluiert, welche MLOps-Elemente den größten Nutzen bieten.
Für die technische Umsetzung der gezeigten konzeptionellen Lösung existiert eine Vielzahl von Anbietern. Beispielhaft zeigen wir hier zwei technische Lösungen.
Sowohl Microsoft Azure, als auch Amazon AWS, bieten für den gesamten MLOps-Lebenszyklus cloudnative Lösungen an. Dazu nutzen die Cloudanbieter ihre altbekannten Grundservices und bauen ihre Machine Learning Lösungen um diese Services herum. Dadurch erhalten Anwendende ein benutzerfreundliches Paket, das viele der gezeigten Lebenszyklusphasen deutlich vereinfacht. Die folgende Tabelle listet eine beispielhafte Implementierung in der Cloud sowohl für Azure, als auch für AWS auf:
| Lifecyclephase | AWS | Azure |
| Versionierung | AWS Sagemaker, basierend auf Amazon S3-Objektspeichern | Azure Machine Learning, basierend auf Azure Blobstorage-Objektspeichern |
| Deployment | AWS Sagemaker, basierend auf AWS EKS (Kubernetes), oder AWS EC2 (virtuellen Maschinen) | Azure Machine Learning, basierend auf Azure AKS (Kubernetes), oder Azure VMs (Virtuelle Maschinen) |
| Pipelineerstellung | AWS Step Functions | Azure Machine Learning Pipelines |
Tabelle 1: Beispielhafte Ml-Ops-Implementierung in der Cloud. Quelle: eigene Zusammenstellung/Aug. 2021
Grundlage der Artefaktversionierung bildet der Objektspeicher der Anbieter. Für das Deployment des Services oder auch das Training werden üblicherweise die Angebote für Virtuelle Maschinen oder Container herangezogen. Eine grafische Darstellung einer einfachen AWS-Lösung ist in Abbildung 2 dargestellt:
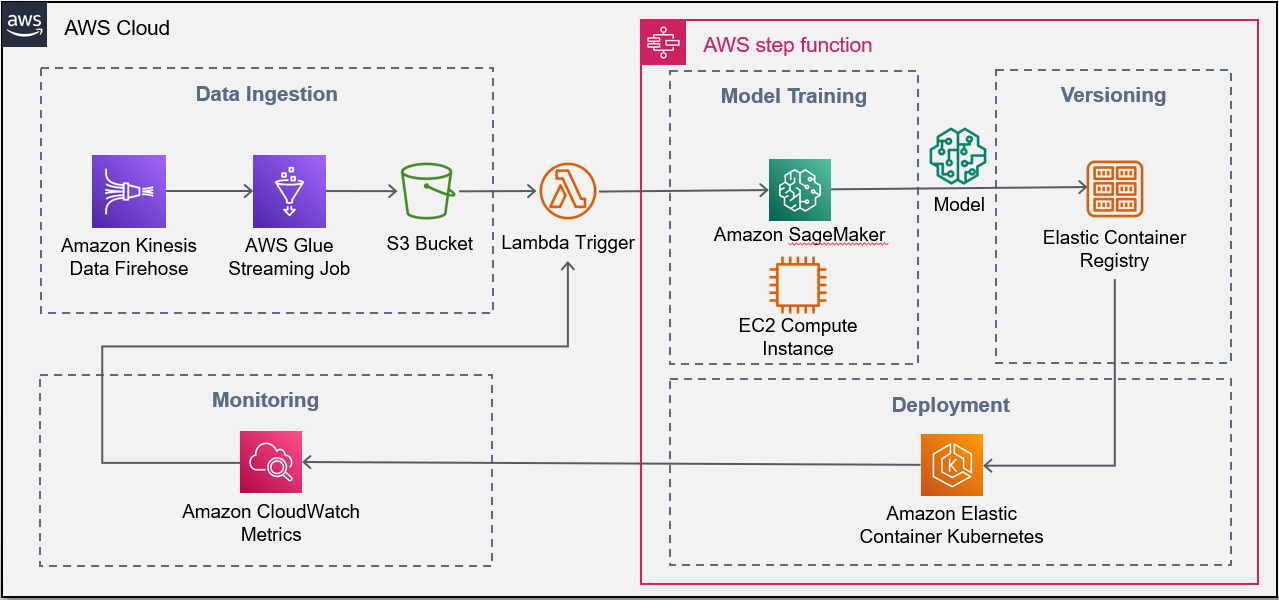
Es ist natürlich nicht unbedingt notwendig, MLOps in der Cloud zu betreiben. Auch On-Premise-Lösungen sind umsetzbar. Hierfür gibt es cloudunabhängige Technologien, wie zum Beispiel Kubeflow. Kubeflow baut auf das Kubernetes-Ökosystem auf, um Modelle mittels entsprechender Container trainieren und deployen zu können. Darüber hinaus bietet es eine Vielzahl von Komponenten, um die einzelnen Lebensphasen wie Training, Deployment, Skalierung usw. abzubilden.
Mit Machine Learning Operations sollen die besonderen Anforderungen an den produktiven Betrieb von Machine Learning Modellen erfüllt werden. Dazu gehören vor allem Reproduzierbarkeit und die Automatisierung aller Prozesse. Durch die Erstellung spezieller Machine Learning Pipelines über den gesamten Lebenzyklus eines Modells hinweg, kann genau das erreicht werden – egal ob in der Cloud, oder On-Premise. Mit einem professionellen und strukturierten Vorgehen können Ihre prototypisch implementierten KI Use Case bzw. PoC in eine produktive, nutzbare Softwarelösung überführt werden.
Zum doubleSlash MLOps Leistungsangebot
Whitepaper downloaden: Leitfaden für das angepasste Vorgehensmodell
