
Usability von Datenprodukten – Tipps und Best Practices aus dem Projektalltag
Das Sammeln von Daten aus verschiedensten Quellen ist in modernen Unternehmen mittlerweile etabliert. Data Lakes haben hierfür das technische Fundament geliefert und Hoffnungen auf neue Nutzungsmöglichkeiten für Daten geweckt – vor allem durch Datenprodukte.
Im Alltag ist durch mangelhafte Strukturierung, Aufbereitung und Qualität der Daten sowie unklaren Verantwortlichkeiten aber aus so manchem Data Lake ein Datensumpf geworden. In diesem Artikel haben wir einige Good Practices zusammengetragen, um genau das zu vermeiden.
Was ist ein Datenprodukt?
Ein Datenprodukt ist mehr als ein Datensatz. Es ist eine Organisation von Verantwortlichkeiten, Prozessen, Wissen und Technologien rund um einen Datensatz. Dies ermöglicht die produkthafte Evolution eines Datensatzes über die Zeit. Es macht den Datensatz nachhaltig wertvoll.
Für jedes Datenprodukt gibt es einen Daten-Product Owner (PO), der dafür verantwortlich ist, dass sein Produkt „funktioniert“. Um das zu gewährleisten, hat er mehrere Aufgaben: Er steht sowohl mit den Nutzern des Datenprodukts in Verbindung, als auch mit den „Herstellern“ (Entwicklungsteam, Data Engineers, Data Scientists) und den „Zulieferern“ (Quellsysteme bzw. Fachbereiche). Diesen Daten-PO treiben unter anderem folgende Fragestellungen um:
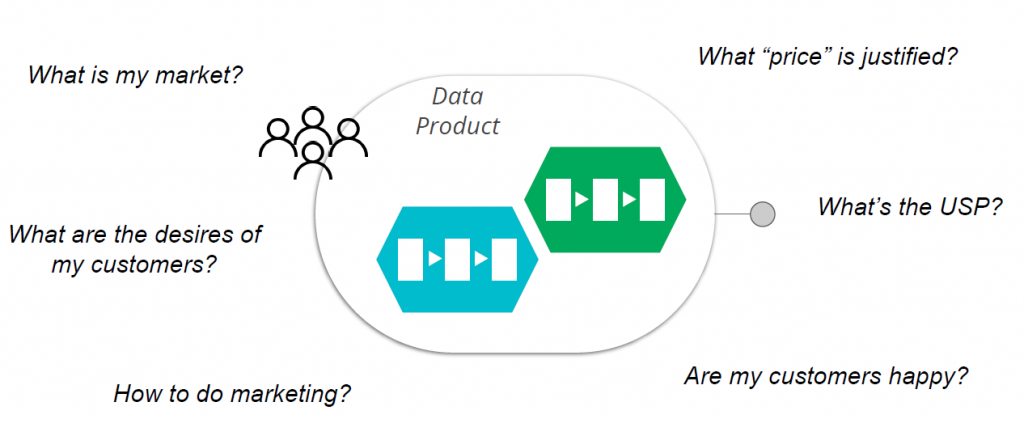
Der Daten-PO pflegt sein Datenprodukt wie ein reales Produkt: Er vertreibt und erläutert es, sammelt Verbesserungsvorschläge von seinen Kunden ein, entwickelt neue Produktideen, prüft, ob sein Produkt noch „Gewinn“ abwirft – also genutzt wird – und begleitet dieses über seinen Produkt-Lebenszyklus. Hinter jedem Datenprodukt kann ein eigenes Team stehen, das für die Entwicklung und den Betrieb des Produktes verantwortlich ist.
Die Anzahl der Datenprodukte auf einer Plattform lässt sich auf diese Weise leichter skalieren, als z.B. bei einem zentralen Data Lake, bei dem das Betreiber-Team im Prinzip für alle, aus den Data Lake entstehenden Daten Produkte verantwortlich ist.
Es kann einfache Datenprodukte geben, also solche, die sehr nah an den Quelldaten sind. Es gibt aber auch komplexe Datenprodukte. Sie sind aus Quelldaten mehrerer Quellen oder sogar aus anderen Datenprodukten zusammengesetzt.
Was macht ein gutes Datenprodukt aus?
Ein gutes Datenprodukt zeichnet sich dadurch aus, dass
- es schnell und einfach zu verstehen ist.
- es leicht zu verwenden bzw. schwer, falsch zu verwenden ist.
- der Datenbestand eine hohe Datenintegrität hat, d.h. die Daten sind korrekt, vollständig und konsistent.
Die grundlegenden Eigenschaften eines guten Datenprodukts beschreibt der Autor für Softwarearchitektur Martin Fowler weiterhin mit:
- Auffindbarkeit (~Eintrag im zentralen Datenkatalog),
- Adressierbarkeit (~Eindeutige, einzigartige ID),
- vertrauenswürdigen und wahrheitsgemäßen Inhalten (~ Korrekt und Konsistent),
- (möglichst) selbstbeschreibender Struktur,
- Inter-operabilität (mit anderen Datenprodukten der Organisation, z.B. durch Referenzierbarkeit mittels IDs; Die Daten liegen bestenfalls in einem gemeinsamen Standard vor und sind standardisiert zugreifbar).
Was sind Good Practices für eine gute Usability von Datenprodukten?
Bei der Bearbeitung verschiedener datenbezogener Problemstellungen im Rahmen von Projekten aus den Domänen Connected Car, E-Mobility, Energy sowie Enterprise-Resource-Planning (ERP) haben wir folgende Good Practices identifiziert:
- Definition einer Nutzergruppe und deren Nutzungszweck für ein Datenprodukt. Dies ermöglicht das Ableiten von…
- Fachlichen Anforderungen:
- relevante Informationen
- Detailgrad
- Partitionierung
- Historisierung
- Aktualität/Update-Intervall.
- Technischen Anforderungen:
- Speicherlösung
- Datenformat
- Zugriffstechnologie
- Fachlichen Anforderungen:
- Ein vollständiger und aktueller Eintrag im Datenkatalog ist zwingend erforderlich. Dieser dient als „Handbuch“ bzw. „Betriebsanleitung“ für die Verwendung des Datenprodukts. Der Eintrag
- beinhaltet FAQs zum Datenprodukt.
- definiert klar die Bedeutung von NULL, „“, 0, -1 und Konstanten.
- definiert klar, in welcher „Einheit“ das Datenprodukt vorliegt (z.B. Euro vs. Cent, KM/H vs Meter/Sekunde).
- zeigt, aus welchen Quellen sich das Datenprodukt zusammensetzt und wie es aufbereitet wird (Data Lineage).
- gibt Auskunft darüber, auf welcher Aggregationsebene die Daten vorliegen (z.B. pro Jahr, pro Monat etc.)
- beschreibt, wie sich die Daten verändern (regelmäßiges Update, Eventbasiertes Update etc.)
- beinhaltet einen Verweis auf den Daten-PO und den Data-Steward für Rückfragen.
- kann eine Informationsklassifizierung nach ISO-27001 beinhalten (öffentlich, intern, vertraulich, streng vertraulich)
- enthält eine Dokumentation eines Mengengerüsts (Anzahl Datensätze und Größe pro Datensatz) sowie einen Ausblick auf die Veränderung der Mengen.
- beinhaltet ggf. auch ein „Verwendungsbeispiel“, bzw. Nutzungsbeispiele.
- Klare, eindeutige Datenstrukturen helfen beim „Verstehen“ der Daten. Sie erlauben, schnell eine Übersicht über den Gesamtdatenbestand zu erlangen und erleichtern, bei einer Suche bestimmte Datensätze aufzuspüren. Die Strukturierung kann durch folgende Aspekte verbessert werden:
- Verwenden von aussagekräftigen Entitäts- und Attributnamen, am besten in Englisch.
- Verwenden von flachen Datenstrukturen, ggf. denormalisieren („Fach-Nutzer denken nicht in normalisierten Schemata“).
- Datenpartitionierung (z.B. nach Zeit, alphabetischer Sortierung, o.Ä.) nutzen, um die Menge der abzufragenden Daten bereits auf einer hohen Ebene einschränken zu können.
- Datensortierung: Die Daten haben bereits eine vorgegebene, eindeutige Sortierung.
- Delta-Update-Fähigkeit: Jeder Datensatz hat Informationen über den Zeitpunkt seiner Erstellung sowie der letzten Modifikation.
- Klare Versionierung, Kompatibilität und Migrationspfade des Schemas (ggf. in Übergangszeiten/bei Breaking Changes Parallelbetrieb von mehreren Versionen).
- Die Anreicherung eines Datenprodukts um Metadaten (Anzahl Datensätze über Zeit, Anzahl Zugriffe auf die Daten, etc.) erlaubt z.B. das Tracking der Verwendung, aber auch das Wachstum des Datenbestands. Damit kann die Wirksamkeit von Veränderungsmaßnahmen am Datenprodukt gemessen werden.
- Technische Kriterien, welche die Nutzung der Daten erleichtern, sind:
- Dokumentation der Zugriffskanäle auf das Datenprodukt (REST API, ODBC Datenbank-Verbindung, etc.) mit Verwendungsbeispielen.
- Bereitstellen von Testdatensätzen: Es sollten reduzierte, aber möglichst vollständige Testdatensätze bereitgestellt werden. Diese sollten nach Möglichkeit sowohl alle „Grenzfälle der Daten“ (Spikes, Max, Min, Null, etc.) als auch gängige Muster beinhalten.
- Falls notwendig/sinnvoll: SLAs für die Verfügbarkeit des Datenprodukts, bzw. der Infrastruktur, auf der das Daten Produkt betrieben wird.
Für die Wahrung einer guten Data User Experience kann ein zentrales Gremium eingesetzt werden, welches über alle Datenprodukte hinweg Standards definiert und deren Umsetzung ermöglicht.
Beispiel Datenprodukt „Rated Customer Topics“
Um diese oben gesammelten Good Practices besser zu veranschaulichen, haben wir ein fiktives Beispiel für ein Datenprodukt entwickelt, das einige dieser Kriterien enthält und ausführt. Alle Technologien und Vorgehensmodelle sind exemplarisch für dieses konkrete Beispiel gewählt und ist somit nicht beliebig auf andere Usecases übertragbar.
Es handelt sich dabei um das Datenprodukt „Rated Customer Complaint Topics“ der fiktiven Umbrella Corporation.
Nutzergruppe und Nutzungszweck
Im ersten Schritt werden die fachlichen Anforderungen beschrieben:
Nutzer des Datenprodukts „Rated Customer Complaint Topics“ sind Produktmanager der Umbrella Corp.
- Sie nutzen das Datenprodukt – also in diesem Fall Beschwerdeliste – um Verbesserungspotentiale an dem jeweils von ihnen betreuten Produkt zu identifizieren.
- Diese sollen als Fokusthemen für Forschung- und Entwicklung dienen. Entsprechende Aktivitäten sollen die erkannten Verbesserungspotentiale erschließen und somit die Probleme der Kunden beheben.
- Die Informationsverdichtung des Datenprodukts „Rated Customer Complaint Topics“ soll sehr hoch sein, da im Bereich Forschung und Entwicklung nur begrenzte Kapazitäten zur Verfügung stehen. Darum kann nur eine ein- bis zweistellige Anzahl von Themen parallel bearbeitet werden.
- Zur Glättung von Ausreißern soll das Datenprodukt „Rated Customer Complaint Topics“ jeweils mit einem Intervall von einem Monat aktualisiert werden.
- Das Datenprodukt „Rated Customer Complaint Topics“ soll für zehn Jahre historisiert werden, um Trends der „Behebung von Problemen der Kunden“ sowie wiederkehrende Trends und Entwicklungsverläufe zu erkennen und darauf reagieren zu können.
Im nächsten Schritt werden die technischen Anforderungen formuliert:
Produktmanager sind vor allem auf fachlicher Ebene unterwegs.
- Daher ist eine geplante Nutzung des Datenprodukts die leicht zugängliche Aufbereitung in Form eines Web-Dashboards.
- Dieses Dashboard soll jeweils die Top 10 Customer Complaint Topics pro Monat beinhalten.
- Darüber hinaus soll es die Möglichkeit bieten, mittels eines Drill-Downs pro Topic detaillierte Kundenbeschwerden einzusehen.
- Durch einen Vor- und Zurück-Mechanismus soll es möglich sein, zwischen aufeinander folgenden und vergangenen Monaten zu wechseln.
Eintrag im Datenkatalog
Wie oben im Beitrag bereits beschrieben, dient ein vollständiger und aktueller Eintrag im Datenkatalog als „Handbuch“, bzw. „Betriebsanleitung“ für die Verwendung des Datenprodukts.
- Das Datenprodukt „Rated Customer Complaint Topics“ beinhaltet je Produkt gewichtete Themenbereiche (=> Hier würde in einem realen Datenkatalog ein Link zur Beschreibung der einzelnen Themenbereiche stehen), zu denen Kundenbeschwerden im Zeitraum eines jeweiligen Monats eingegangen sind. Außerdem ist über die Themenbereiche ein Drilldown zu konkreten Kundenbeschwerden möglich. Die Gewichtung der Themenbereiche erfolgt anhand der Anzahl der für diesen Bereich erfassten Kundenbeschwerden.
- Das Datenprodukt aggregiert sich aus einzelnen konkreten Kundenbeschwerden, welche mittels der Unternehmenswebsite und über den Telefonsupport (via CRM-System) eingesteuert werden. Dabei werden invalide Einträge herausgefiltert. Eine detaillierte Herleitung ist im Abschnitt Data Staging zu finden.
- Das Datenprodukt wird monatlich erstellt und beinhaltet eine monatliche Historie der letzten 10 Jahre. Eine Aktualisierung wird jeweils zum 1. Tag des Folgemonats vorgenommen.
- Das Datenprodukt beinhaltet keine personenbezogenen Daten, aber Informationen zu Produktdetails und ist deshalb als „INTERN“ klassifiziert.
- Der Datenbestand des Datenprodukts beträgt zum 31.12.2020 6.000 Datensätze mit einer Größe von ca. 4KB pro Datensatz. In Zukunft wird ein lineares Wachstum des Datenbestands um ca. 1200 Datensätze pro Jahr erwartet. Durch die Beschränkung der Historisierung auf 10 Jahre ist mit einem maximalen Datenbestand von ca. 12.000 Datensätzen zu rechnen.
- Fachlicher Ansprechpartner für das Datenprodukt (Daten-PO) ist Max Mustermann (=> Hier würde in einem realen Datenkatalog ein Link zu den Kontaktdaten stehen). Technischer Ansprechpartner für das Datenprodukt (Data Steward) ist Klaus Müller (=> Hier würde in einem realen Datenkatalog ein Link zu den Kontaktdaten stehen).
Sie haben Fragen zum Datenprodukt? Stellen Sie diese gerne direkt mittels Kontaktformular (=> im realen Datenkatalog wäre hier ein Link zum Kontaktformular) an Max Mustermann. Eine Liste der bereits gestellten und beantworteten Fragen finden sie im Forum des Datenprodukts (=> im realen Datenkatalog wäre hier ein Link zum Datenprodukt).
Technische Kriterien
Im Folgenden werden noch Beispiele für wichtige, technische Kriterien des Datenprodukts genannt:
Der Zugriff auf das Datenprodukt kann mittels ODBC erfolgen. Ein Zugriffsbeispiel ist in den FAQs dokumentiert (=> im realen Datenkatalog wäre hier der Link zu den FAQs). Der Zugang kann elektronisch über das Antragsportal beim Daten-PO beantragt werden (=> im realen Datenkatalog wäre hier der Link zum Antragsportal). Für den Zugriff gelten die allgemeinen SLAs der BigData Infrastruktur der Umbrella Corp (=> im realen Datenkatalog wäre hier der Link zu den SLAs hinterlegt).
Das Datenprodukt beinhaltet konkret folgende Entitäten und Attribute:
Entität „Rated Customer Complaint Topics“
| Attribut | Beschreibung | Identifier | Typ | Einheit | Format |
| topicName | Name des Themenbereichs (=> Link zur Beschreibung der einzelnen Themenbereiche). | Ja | Text | Themenbereich | — |
| consideredPeriod | Zeitraum der Betrachtung; Zeitraum in dem die Kundenbeschwerden, aus welchen sich das Attribut „numberOfComplaintsInTopic“ berechnet eingegangen sind. | Ja | Text | Monat | yyyy-MM |
| productReference | Referenz auf das Produkt, auf welches sich der Themenbereich bezieht (=> Link zum Produktverzeichnis) | Ja | ID | — | — |
| numberOfComplaintsInTopic | Anzahl an Kundenbeschwerden im Zeitraum „consideredPeriod“. | Nein | Ganzzahl | Anzahl | x.xxx.xxx |
| detailedCustomerComplaints | Drilldown-Link zu den detaillierten Kundenbeschwerden, die in die den Themenbereich und den Betrachtungszeitraum eingeflossen sind. Der Link referenziert eine Liste von Detailed Customer Complaint IDs. | Nein | Liste<ID> | — | — |
| creationTimestamp | Zeitpunkt der Erstellung dieses Datensatzes in der Trusted Zone in der Zeitzone UTC. | Nein | Zeitstempel | Datum, Uhrzeit | ISO_8601
DataTime |
| lastUpdateTimestamp | Zeitpunkt der Letzten Aktualisierung dieses Datensatzes in der Trusted Zone in der Zeitzone UTC. | Nein | Zeitstempel | Datum, Uhrzeit | ISO_8601
DataTime |
| schemaVersion | Version des Schemas für „Rated Customer Complaint Topics“. | Nein | Ganzzahl | — | — |
Die Instanzen der Entität sind nach „consideredPeriod“ partitioniert. Die Partitionen sind nach Zeitraum neueste absteigend sortiert.
Innerhalb der Partition haben die Instanzen der Entität standardmäßig eine Sortierung nach „numberOfComplaintsInTopic“ absteigend, „topicName“ alphabetisch“.
Entität „Detailed Customer Complaint“
| Attribut | Beschreibung | Identifier | Typ | Einheit | Format |
| detailedCustomerComplaintId | Laufende Nummer zur eindeutigen Identifizierung der Kundenbeschwerde. Die Nummer wird beim Import in die Trusted Zone vergeben. | Ja | UUID | — | Zeitstempelbasierte_UUIDs |
| productReference | Referenz auf das Produkt, auf welches sich der Themenbereich bezieht (=> Link zum Produktverzeichnis) | Ja | ID | — | — |
| complaintReceivedTimestamp | Zeitstempel des Eingangs der Kundenbeschwerde im Quellsystem in der Zeitzone UTC. | Nein | Zeitstempel | Datum, Uhrzeit | ISO_8601 DateTime |
| complaintText | Text der Kundenbeschwerde in der vom Kunden verwendeten Sprache, bereinigt um Steuerzeichen. | Nein | Text | — | Text in UTF8 encoding. |
| complaintCountryCode | Ländercode das Landes, in dem die Kundenbeschwerde erfasst wurde. | Nein | Text | Ländercode | ISO_3166-1_alpha-2 |
| creationTimestamp | Zeitpunkt der Erstellung dieses Datensatzes in der Trusted Zone in der Zeitzone UTC. | Nein | Zeitstempel | Datum, Uhrzei | ISO_8601 DateTime |
| lastUpdateTimestamp | Zeitpunkt der Letzten Aktualisierung dieses Datensatzes in der Trusted Zone in der Zeitzone UTC. | Nein | Zeitstempel | Datum, Uhrzeit | ISO_8601 DateTime |
| schemaVersion | Version des Schemas für „Detailed Customer Complaint“. | Nein | Ganzzahl | — | — |
Data Staging
Das Data Staging zeigt auf, wie die Data Pipeline für das Datenprodukt „Rated Customer Complaint Topics“ im Detail strukturiert ist. Es ermöglicht also dem Nutzer des Datenprodukts, nachzuvollziehen, aus welchen Datenquellen sich das Datenprodukt zusammensetzt und wie es im Detail erstellt wird.
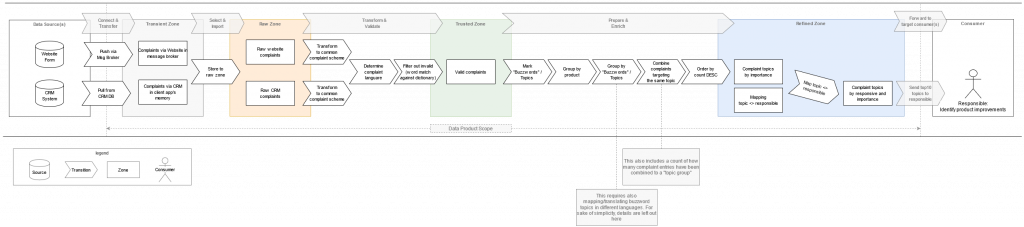
Anhand des Beispiels „Rated Customer Complaint Topics“ wurde aufgezeigt, wie ein exemplarisches Datenprodukt so gestaltet werden kann, dass ein potentieller Nutzer nach Möglichkeit Freude an seiner Nutzung hat. Nur wenn das gegeben ist, wird das Datenprodukt und die ihm zugrundeliegenden Daten auch verwendet. Diese Nutzung rechtfertigt nicht nur die Speicherung der Daten und die damit verbundenen Kosten, sondern trägt auch dazu bei, dass sie durch den Gewinn neuer Erkenntnisse einen „Wert“ generieren. Durch die Einhaltung der in diesem Artikel beschriebenen Good Practices kann der Gebrauch solcher Datenprodukte vereinfacht werden. Denn: Einfachere Nutzung führt meist zu vermehrter und intensiverer Anwendung. Das wiederum führt dazu, dass ein potentiell größerer Wert geschaffen werden kann. Somit sollte die gute Usability von Datenprodukten all denen am Herzen liegen, die den Nutzen ihrer Daten maximieren möchten.
