
Ressourceneffizientes Coden: Energiesparende Ansätze im Fokus
Eine zentrale Rolle in diesem Prozess spielen Softwaremessungen, die Wahl der richtigen Datenstrukturen und Algorithmen. In diesem Zusammenhang werfen wir einen genaueren Blick auf drei Ansätze, die nicht nur Energieeinsparungen versprechen, sondern auch die Leistung und Entwicklungseffizienz verbessern.
Können diese Techniken dazu beitragen, ressourceneffizientes Coden zu fördern?
SPELL: Energielecks im Code aufspüren
SPELL ist eine spektrumbasierte Technik, die zur Lokalisierung von Energielecks im Quellcode von Softwaresystemen dient. Diese Methode, die unabhängig von der Programmiersprache und dem Kontext ist, verwendet einen statistischen Ansatz, um verschiedene Anteile der Energieverantwortung den verschiedenen Quellcodekomponenten eines Softwaresystems zuzuordnen. So wird die Aufmerksamkeit des Entwicklers auf die kritischsten Stellen gelenkt. Vorläufige empirische Studien mit Java-Programmierern zeigten, dass Entwickler mit SPELL nicht nur in der Lage waren, den Energieverbrauch eines Programms zu optimieren, sondern dies auch schneller und effizienter tun konnten als diejenigen, die SPELL nicht verwendeten. Diese Ergebnisse legen nahe, dass SPELL eine vielversprechende Methode zur Identifizierung und Optimierung des Energieverbrauchs in Softwareprojekten darstellt.
CT+: Ressourceneffizientes Coden mit Java-Kollektionen
CT+ ist ein Toolset für die energiebewusste Entwicklung von Java-Anwendungen. Dieses Set kombiniert die Erstellung von anwendungsunabhängigen Energieprofilen von Java-Kollektionen mit statischer Analyse, um Empfehlungen für energieeffiziente Implementierungen dieser Kollektionen zu generieren. Durch den Einsatz energieineffizienter Kollektionen konnten bis zu 17,34% Energieeinsparungen erzielt werden. Diese Ergebnisse unterstreichen die Bedeutung einer bewussten Auswahl von Ressourcen für die Energieeffizienz von Softwareanwendungen.
Optimierung der Java-Collection-Frameworks
Diese Studie liefert einen detaillierten Einblick in den Energieverbrauch verschiedener Implementierungen des Java-Collection-Frameworks (JCF). Durch die Identifizierung der energieeffizientesten Methoden jeder Implementierung und die Optimierung von Java-Programmen basierend auf diesen Erkenntnissen konnten Einsparungen von bis zu 6,2% erzielt werden. Diese Ergebnisse zeigen, dass selbst kleine Änderungen in der Wahl der verwendeten Datenstrukturen zu signifikanten Verbesserungen in der Energieeffizienz führen können.
Ausblick
Die vorgestellten Techniken bieten vielversprechende Ansätze zur Steigerung der Ressourceneffizienz beim Coden. Unser Unternehmen plant, diese Tools in zukünftigen Projekten zu testen, um folgende Fragen zu klären:
Lohnt sich der Aufwand? Welche Auswirkungen hat dies auf das Coden? Bringt es einen Mehrwert?
Die Ergebnisse dieser Tests werden entscheidend sein, um zu verstehen, für wen die Energieeffizienz beim Coden von Nutzen sein kann und wie sie in der Praxis am besten umgesetzt werden könnte.
Erfahrt Mehr dazu, welchen Stellenwert Nachhaltigkeit für uns als Unternehmen hat: Unsere Visionen und Werte
Quellen
- Pereira, R., et al. (2017). Helping Programmers Improve the Energy Efficiency of Source Code. In 2017 IEEE/ACM 39th IEEE International Conference on Software Engineering Companion. HASLab/INESC TEC, Universidade do Minho, Portugal; NOVA LINCS, DI, FCT, Universidade NOVA de Lisboa, Portugal. Release/LISP, CISUC, Universidade de Coimbra.
- Oliveira, W., et al. (unbekanntes Datum). Recommending Energy-Efficient Java Collections. Federal University of Pernambuco; Federal University of Para.
- Pereira, R., et al. (2016). The Influence of the Java Collection Framework on Overall Energy Consumption. HASLab/INESC TEC, Portugal; Universidade do Minho, Portugal; NOVA LINCS, DI, FCT, Universidade NOVA de Lisboa, Portugal. RELEASE, Universidade da Beira Interior, Portugal.
It’s #FrontendFriday – Atomic Design in der Angular Entwicklung
Begriffserklärung
Das Atomic Design wurde von Brad Frost entwickelt und ermöglicht uns, komplexe Designs und Benutzeroberfläche zu vereinfachen und zu strukturieren. Die Benutzeroberfläche wird dabei in wiederverwendbare Komponenten zerlegt und in verschiedenen Abstraktionsebenen organisiert. [2]
Die fünf Ebenen sind:
- Atoms: Grundlegendste Elemente, die nicht weiter in Einzelteile zerlegt werden können, wie Buttons, Inputs oder Textelemente wie Links.
- Molecules: Gruppen von Atomen, die zusammen eine funktionale Einheit bilden.
- Organisms: Komplexe Komponenten bestehend aus Molekülen, Atomen oder anderen Organismen.
- Templates: Rahmen für Content-Platzierung, definieren die Struktur einer Seite.
- Pages: Spezifische Instanzen von Templates mit realem Content, zeigen das endgültige Design.

Ist Atomic Design für Angular Anwendungen geeignet?
Kurz und knapp: Ja. Angular ist ein komponentenbasiertes Framework und unterstützt die Wiederverwendbarkeit von Komponenten. Das Atomic Design kann dabei helfen, UI-Komponenten in Angular weiter zu strukturieren und zu ordnen.
Atome und Moleküle in Angular könnten als wiederverwendbare Komponenten und Direktiven implementiert werden. Hierunter fallen beispielsweise Suchfelder, Buttons, Textareas oder Dropdowns.
Organismen könnten komplexere Komponenten oder Komponentengruppen darstellen, die mehrere Moleküle kombinieren. Beispiele hierfür wären Cookie Banner, Dialoge oder Navigationsleisten.
Templates und Pages würden sich als Komponentenlayouts und routbare Ansichten manifestieren, die spezifische Inhalte anzeigen. [2] [3]
Kann Atomic Design die offizielle Angular-Architektur ersetzen?
Die offizielle Angular Architektur empfiehlt eine Unterteilung in verschiedene Kategorien wie Core, Shared, und Feature. Dabei macht es keinen Unterschied ob Module verwendet werden oder bereits „Standalone Components“ (verfügbar ab Angular 14).
Core: Enthält sämtliche Kernelemente einer Anwendung, welche nur einmalig existieren.
Shared: Enthält wiederverwendbare Komponenten, Pipes und Direktiven, die in verschiedenen Teilen der Anwendung genutzt werden können.
Features: Beinhalten alle Komponenten, Services und andere Elemente, die für ein spezifisches Feature notwendig sind.
Atomic Design kann diese Struktur ergänzen, indem es diese weiter unterteilt und organisiert. Das Shared Module kann beispielsweise weiter in Atome und Moleküle unterteilt werden und weiterhin sämtliche Elemente wie Buttons, Inputfelder etc. bereitstellen.
Eine eindeutige Zuordnung ist jedoch nicht immer möglich. Organismen wie beispielsweise ein Footer sollte dem Core zugeordnet werden. Wohingegen Dialoge, welche von verschiedenen Features verwendet werden klar in die Kategorie Shared gehören.
Dennoch bietet Atomic Design eine wertvolle Ergänzung. [4]
∇ app
∇ core
∇ guards
auth.guard.ts // Überprüft die Authentifizierung des Benutzers
∇ interceptor
token.interceptor.ts // Fügt das JWT zum Header der Anfragen hinzu
error.interceptor.ts // Zentralisierte Fehlerbehandlung für HTTP-Anfragen
∇ services
auth.service.ts // Handhabt Authentifizierung und Benutzerdaten
api.service.ts // Zentralisiert die Verwaltung von API-Anfragen
∇ components
∇ navbar // Navbar, ein Organismus
navbar.component.html
navbar.component.scss
navbar.component.ts
∇ footer // Footer, ein weiterer Organismus
footer.component.html
footer.component.scss
footer.component.ts
∇ page-not-found
page-not-found.component.html
page-not-found.component.scss
page-not-found.component.ts
∇ constants
app-config.ts // Allgemeine Konfigurationswerte
api-endpoints.ts // Zentralisierte API-Endpoints
∇ enums
role.enum.ts // Enum für Benutzerrollen
status.enum.ts // Enum für Statuscodes
∇ models
user.model.ts // Benutzermodell
product.model.ts // Produktmodell
∇ features
∇ product-listing // Feature Modul für Produktlisten
∇ components
∇ product-item // Organismus: Einzelnes Produkt
product-item.component.html
product-item.component.scss
product-item.component.ts
∇ product-grid // Template: Anordnung der Produkt-Items
product-grid.component.html
product-grid.component.scss
product-grid.component.ts
∇ pages
∇ product-list-page // Seite: Nutzt das Product Grid Template
product-list-page.component.html
product-list-page.component.scss
product-list-page.component.ts
∇ product-detail-page // Seite: Detailansicht eines Produkts
product-detail-page.component.html
product-detail-page.component.scss
product-detail-page.component.ts
∇ models
product.model.ts // Spezifisches Modell für Produkte
∇ services
product.service.ts // Service für produktbezogene Daten
feature-a-routing.module.ts // Routing für dieses Feature
feature-a.component.ts // Root-Komponente des Features, falls benötigt
∇ shared
∇ components
∇ button // Atom: Allgemeiner Button
button.component.html
button.component.scss
button.component.ts
∇ input-field // Atom: Texteingabefeld
input-field.component.html
input-field.component.scss
input-field.component.ts
∇ form-field // Molekül: Kombiniert Label und Input-Field
form-field.component.html
form-field.component.scss
form-field.component.ts
∇ directives
tooltip.directive.ts // Direktive für Tooltips
∇ pipes
translate.pipe.ts // Pipe für Währungsformatierung
shared.module.ts // Definiert das Shared Modul
styles.scss
▽ styles
variables.scss
▽ assets
▽ i18n
en.json
de.json
▽ images
logo.svg
banner.svg
Wie steht Atomic Design in Verbindung mit dem Component-based Development?
Atomic Design und Component-based Development sind eng miteinander verbunden. Beide Konzepte legen den Fokus auf die Entwicklung von wiederverwendbaren Komponenten. In Angular, einem Framework, das auf der Komponentenarchitektur basiert, ermöglicht Atomic Design eine systematische Herangehensweise an die Entwicklung der Komponenten. Durch die Zerlegung von Benutzeroberflächen in Atome, Moleküle, Organismen und so weiter, können Entwickler eine klare Struktur und Hierarchie für ihre Komponenten schaffen. Dies fördert die Wiederverwendbarkeit und Wartbarkeit der Komponenten, was wiederum die Effizienz der Entwicklung und Wartung von Angular-Anwendungen verbessert. [3]
Schlussfolgerung
Atomic Design bietet eine nützliche Methode zur Organisation und Strukturierung von Komponenten in Angular-Anwendungen. Es ersetzt nicht die existierende Angular-Architektur, sondern kann diese sinnvoll ergänzen, um Effizienz, Konsistenz und Wiederverwendbarkeit innerhalb einer Anwendung zu verbessern. [2]
Quellen:
[1] doubleSlash Living Styleguide [2] Atomic Design [3] aubergine – How to Use Angular and Atomic Design to Create Web Applications: A Guide for New Developers [4] Medium – Atomic design in Angular project
Uber’s Erfolgsgeheimnis: Node.js für leistungsstarke Echtzeit-Apps
Sie ermöglicht es uns, Apps zu entwickeln, die nicht nur den Anforderungen gerecht wird, sondern auch herausragend performt. Node.js hat sich in diesem Bereich als herausragende Technologie etabliert. Dabei wird Node.js von führenden Tech-Unternehmen für die Entwicklung von Echtzeit-Apps bevorzugt eingesetzt.

In der Welt der Echtzeitanwendungen unterscheiden wir zwischen weicher und harter Echtzeit. Weiche Echtzeit bedeutet, dass Aufgaben innerhalb vorgegebener Zeitrahmen abgeschlossen sein sollten, wobei gelegentliche Verzögerungen toleriert werden, sofern sie keine kritischen Auswirkungen haben. Im Gegensatz dazu verlangt harte Echtzeit die Ausführung von Aufgaben innerhalb strikter Zeitlimits, weil jegliche Verzögerungen zu schwerwiegenden Folgen führen können, einschließlich Systemabstürzen, Datenverlust oder sogar dem Verlust von Menschenleben. Daher ist es vor dem Start eines Softwareprojekts entscheidend, die Anforderungen genau zu definieren und zwischen harter und weicher Echtzeit zu unterscheiden, um die reibungslose Funktion des Systems zu gewährleisten.
Was ist Node.js und wann sollte man Node.js einsetzen?
Node.js ist eine serverseitige Laufzeitumgebung, die auf Googles JavaScript-Engine V8 basiert. Sie zeichnet sich durch eine nicht blockierende, ereignisgesteuerte Architektur aus, die hervorragend für weiche Echtzeitanwendungen geeignet ist. Diese Architektur ermöglicht die Verarbeitung einer enormen Anzahl asynchroner Anfragen in kürzester Zeit. Darüber hinaus bieten Node.js-Anwendungen hohe Skalierbarkeit und Leistung, was sie zu einer idealen Wahl für Echtzeit-Apps macht.
Anwendungsfall in der Praxis: Das Beispiel Uber
Uber ist ein Technologieunternehmen, das eine Plattform für Mobilitätsdienste anbietet, über die Nutzer Fahrten, Essenslieferungen und Frachttransportdienste per App buchen können. Uber gehört zu den Pionieren, die Node.js in großem Maßstab in der Produktion einsetzen. Dank seiner verteilten Architektur, die aus vielen Modulen besteht, welche über APIs kommunizieren, um Millionen gleichzeitiger Anfragen zu verarbeiten, hat sich Node.js als die ideale Lösung für Uber erwiesen.
Die Entscheidung für Node.js traf Uber aufgrund des Bedarfs an einer Echtzeit- und schnellen, API-getriebenen Architektur. Uber nutzt zahlreiche Mikroservices, um seine Infrastruktur zu betreiben, was eine Backend-Lösung erfordert, die alles zusammenhalten kann. Zudem hat das Unternehmen das Ziel, fortgeschrittene Analysen der riesigen, durch die Plattform generierten, Datenmengen durchzuführen.
Für Uber sind die Vorteile von Node.js erheblich. Es gelang dem Unternehmen, eine zuverlässige und verteilte Umgebung für seine Web- und Mobilanwendungen auf Basis von Node.js zu entwickeln. Insbesondere die Komponente, die für die Ausführung von Fahrten verantwortlich ist, profitiert von der asynchronen und single-threaded Event-Loop von Node.js, was sie äußerst zuverlässig macht. Uber kann eine große Anzahl von Benutzeranfragen verarbeiten, und das API-Ökosystem des Unternehmens, das über 600 zustandslose Endpunkte (2) umfasst, die alle in Node.js geschrieben sind, erhöht die Konnektivität und reduziert den Verwaltungsaufwand. Mit diesen Fähigkeiten unterstützt Uber täglich 17 Millionen Fahrten (3) und demonstriert eine nahtlose Integration sowohl in Backend- als auch in Frontend-Schnittstellen.
Unsere Einschätzung: Genau dann sollte Node.js eingesetzt werden
Node.js genießt große Beliebtheit im Echtzeitbereich, insbesondere bei Anwendungen, die weiche Echtzeitanforderungen haben. Dank seiner ereignisgesteuerten Architektur ermöglicht es eine effiziente Verarbeitung. Obwohl es möglicherweise nicht für Anwendungen mit strengen Zeitvorgaben im Millisekundenbereich – also harte Echtzeitanforderungen – ideal ist, liefert es hohe Leistung und Flexibilität für eine breite Palette von Use-Cases, die weiche Echtzeit erfordern. Bei doubleSlash ist Node.js ein zentraler Bestandteil unseres Serviceangebots. Durch die Nutzung dieser fortschrittlichen Technologie entwickeln wir innovative Lösungen, die die Vorteile von Node.js voll ausschöpfen, um unseren Kunden zu helfen, ihr digitales Potenzial maximal zu entfalten.
Welche anderen großen Tech-Unternehmen Node.js verwenden und weitere interessante Beiträge zu dem Thema gibt es hier: https://blog.doubleslash.de/category/software-technology/node-js
Quellen:
(2): https://www.uber.com/en-IN/blog/uber-tech-stack-part-two/
Unterschiedliche Git Benutzer – einfach eingerichtet mit includeIf
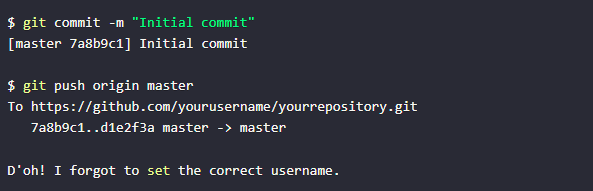
Bei meinem letzten Korrekturversuch hatte ich jedoch einen Überraschungsmoment: „Oh, doch der richtigen Name und die korrekte E-Mail Adresse. Wie kann das sein? Magie oder Hexerei?“
Tatsächlich ist Lösung recht einfach. So einfach, dass ich dessen Einrichtung schon wieder vergessen hatte.
Was ist passiert?
Regelmäßig klone ich Repositories, mal von GitLab, mal von GitHub, mal für die Arbeit, mal privat – jedoch meist mit unterschiedlichen Accounts, Benutzernamen und E-Mail Adressen.
Früher habe ich für jedes Repository eine projektspezifische git-config vorgenommen. Aber jedes Mal neu daran denken, diese einzurichten – nunja, das klappt nur mäßig. Deshalb bin ich auf Skripte umgestiegen, die zum Beispiel in meiner globalen git-config die Parameter user.name & user.email überschreiben. Klappt schon besser, weil ich so flexibel den Account wechseln kann, egal in welchem Tool ich gerade arbeite. Aber daran denken muss ich trotzdem.
Um den Wechsel per Skript nicht zu vergessen, habe ich es mir zur Gewohnheit gemacht, für jeden Account einen eigenen Unterordner zu verwenden:
C:\code\ ├─ doubleSlash-github ├─ Repo-1 ├─ Repo-2 ├─ doubleSlash-gitlab ├─ Repo-1 ├─ Repo-2 ├─ private-github ├─ Repo-1
Aber wie erkennt Git beim letzten Commit den richtigen Benutzernamen, obwohl ich nach dem Klonen des Repos weder eine repository-spezifische git-config noch meine Skripte ausgeführt hatte? Es war kein Glück und auch keine Hexerei ;-)
git-config und das includeIf-Feature
Die Magie liegt in meiner benutzerspezifischen git-config und dem includeIf-Feature verborgen:
# ~/.gitconfig
# doubleSlash GitHub Account
[includeIf "gitdir:code/doubleSlash-github/"]
[user]
name = "Michael Goldschmidt (ds)"
email = my-github-noreply-email@users.noreply.github.com
# doubleSlash GitLab Account
[includeIf "gitdir:code/doubleSlash-gitlab/"]
[user]
name = "Michael Goldschmidt"
email = my@work.email
# Personal GitHub Account
[includeIf "gitdir:code/private-github/"]
[user]
name = "Michael Goldschmidt"
email = my@private.email
[core]
sshCommand = "ssh -i ~/.ssh/private-id_rsa"
Die includeIf-Blöcke sorgen dafür, dass abhängig vom Ordnerpfad meines Repositories Git die entsprechenden Konfigurationseinträge verwendet. In meinem Fall sind dies die Werte für user.name & user.email sowie gegebenenfalls das core.sshCommand.
Um die Übersicht zu bewahren, gehe ich noch einen Schritt weiter und binde für jeden Account eine separate git-config ein:
# ~/.gitconfig # doubleSlash GitHub Account [includeIf "gitdir:code/doubleSlash-github/"] path = ~/.gitconfig-ds-github # doubleSlash GitLab Account [includeIf "gitdir:code/doubleSlash-gitlab/"] path = ~/.gitconfig-ds-gitlab
# ~/.gitconfig-ds-github [user] name = "Michael Goldschmidt (ds)" email = my-github-noreply-email@users.noreply.github.com
Fazit
Ist die git-config mit dem includeIf-Feature einmal eingerichtet, funktioniert sie so zuverlässig, dass ich seither nicht mehr darüber nachdenken muss und das Feature beinahe vergessen hätte. Es funktioniert einfach.
(Und bevor ich es wieder vergesse -> Zeit es mit euch zu teilen!)
Quellen:
- [1] D’oh siehe https://en.wikipedia.org/wiki/D’oh!
- https://git-scm.com/docs/git-config
- und viele weitere englische Quellen via Suchmaschine mit dem selben und vielen weiteren git-config Tipps ;-)
Get Connected: Vernetzung von MedTech-Geräten
Die Verfügbarkeit, Aktualität und Erweiterbarkeit deutlich zu verbessern. Gleichzeitig wollen wir sicherstellen, dass Nutzerinnen und Nutzer beim Betrieb dieser Geräte bestmöglich unterstützt werden. Die echte Herausforderung dabei: Eine Konnektivität zu gewährleisten, bei der die technische Anbindung der Geräte sowohl sicher als auch zuverlässig funktioniert. In diesem Blogpost erkunden wir die verschiedenen Anbindungsoptionen für MedTech-Geräte und zeigen auf, wie wir diese anspruchsvollen modernen Anforderungen erfüllen können.
Anbindungsoptionen für MedTech-Geräte
Je nach Hardware-Konfiguration und Gerätetyp variieren die Möglichkeiten, wie MedTech-Geräte ins Netzwerk integriert werden können. Generell unterscheiden wir zwischen drei Kategorien:
- Kompakte und mittelgroße Geräte, auf denen ein proprietäres Betriebssystem läuft
- Geräte, die mit einem weit verbreiteten Betriebssystem wie Microsoft Windows © arbeiten
- Geräte, die dank einer integrierten Schnittstelle eine Verbindung via App ermöglichen.
1. Anbindung kompakter und mittelgroßer MedTech-Geräte mit proprietärem Betriebssystem
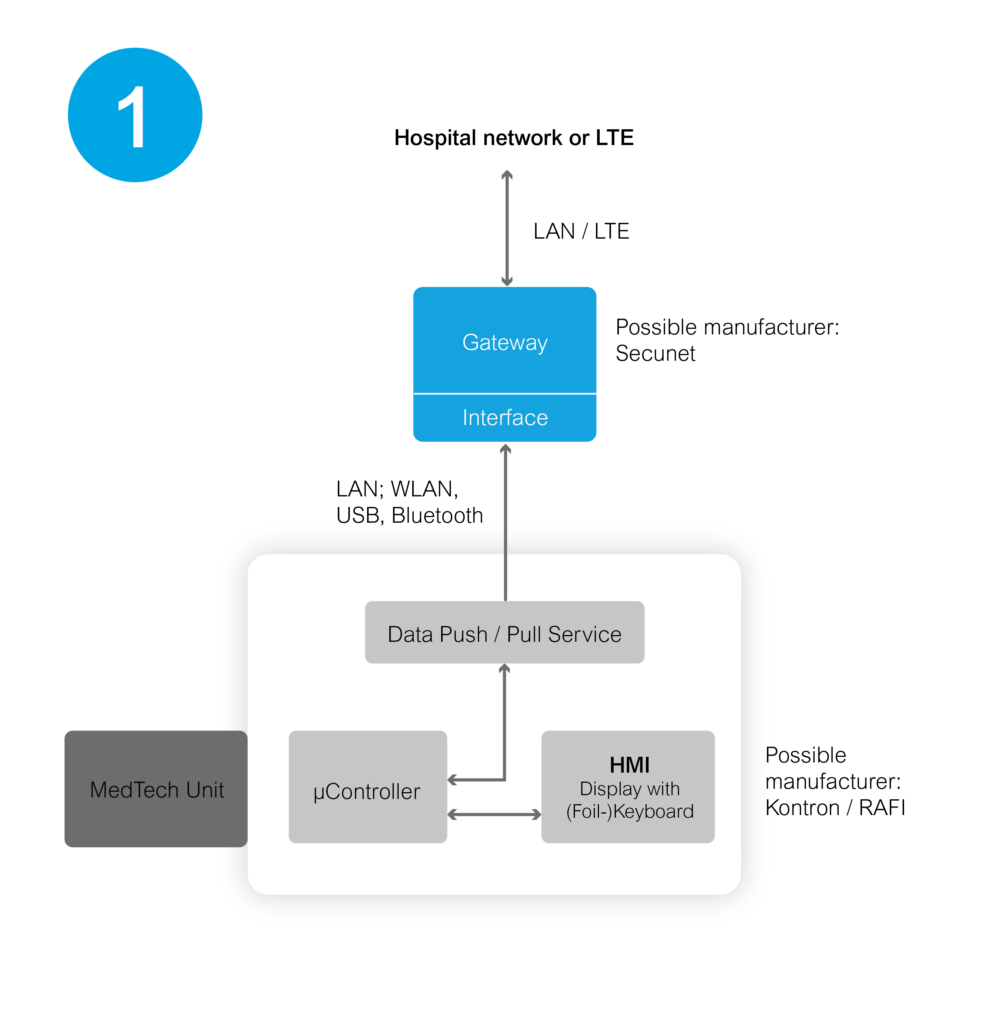
Die Konnektivität von Geräten mit eigenentwickelten Betriebssystemen ist wesentlich durch deren Hardware-Software-Architektur bestimmt. Diese Architektur unterstützt meist einen Push- oder Pull-Mechanismus für den Austausch von Daten und Befehlen. Geräte mit speziellen Betriebssystemen verfügen oft über maßgeschneiderte Software, die eine zielgerichtete Steuerung und den Austausch von Daten ermöglicht. Die Nutzung von Windows oder anderen standardisierten Betriebssystemen scheidet häufig aus Gründen der Hardwareperformance aus.
In diesem Zusammenhang bietet der Einsatz von speziellen Security-Lösungen eine strategische Möglichkeit, Sicherheitsstandards zu erhöhen und empfindliche Informationen sicher vor Bedrohungen zu schützen. (Bsp. Security Gateway von unserem Partner SecuNet).
2. Integration von MedTech-Geräten mit Standard-Betriebssystemen

Im Gegensatz zu Geräten mit maßgeschneiderten Betriebssystemen erfolgt die Anbindung von Geräten mit gängigen Betriebssystemen wie Microsoft Windows, Linux usw. anders. Die Verbindung wird hier durch die Installation eines speziellen Software-Agenten hergestellt, der speziell für das jeweilige bekannte Betriebssystem konzipiert ist. Dieser Agent ermöglicht die Kommunikation über vorhandene Netzwerkzugänge via LAN oder WLAN. Der Schlüssel für eine erfolgreiche Vernetzung liegt in der maßgeschneiderten Bereitstellung und Feinabstimmung dieses Agenten, der je nach Anforderung entwickelt und angepasst wird. Solche Anpassungen sind essenziell, damit Datenfluss und Befehlsübertragungen zwischen den Geräten und dem Netzwerk reibungslos funktionieren.
3. Vernetzung über mobile Anwendungen
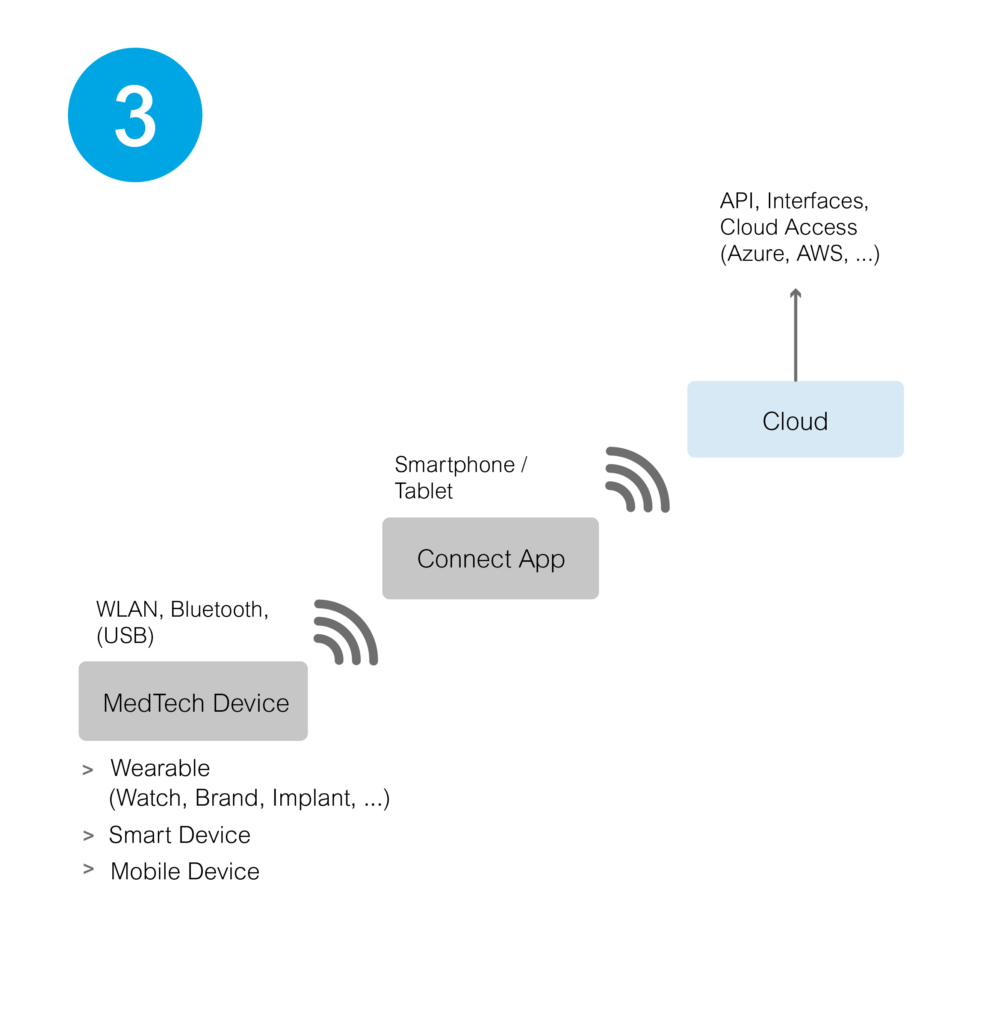
Bei der dritten Vernetzungsvariante kommunizieren MedTech-Geräte über Apps auf Smartphones oder Tablets – verbunden durch Bluetooth, WLAN oder temporäre USB-Verbindungen. Hierbei zeichnen sich zwei Hauptansätze ab:
- Im ersten Ansatz übermitteln die Geräte Daten direkt an die App, die dann die Informationen in die Cloud weiterleitet. Für Nutzende bedeutet das, dass sie Zugriff auf die Cloud benötigen, um gewünschte Daten abzurufen oder spezielle Services zu nutzen und einzubinden. Ein Beispiel hierfür ist die Integration von Daten in die Apple Health App von Wearables (Bsp. Withings).
- Eine zweite Option ist die Entwicklung einer speziellen App, die direkt eine Verbindung zum Gerät herstellt und Daten in eine festgelegte Cloud-Infrastruktur überträgt. MedTech-Gerätehersteller nutzen dies, um über temporäre Datenverbindungen Informationen für die Weiterverarbeitung in Netzwerke zu übertragen. In einigen Anwendungsfällen setzen wir hier den „Business File Manager“ von doubleSlash ein, um diese Übertragung der Daten zu übernehmen. Der klare Vorteil dieser Option liegt in der Flexibilität, die App an die spezifischen Bedürfnisse der Geräte, des Netzwerks oder bestimmter Anforderungen anzupassen.
Der Weg zur nahtlosen Vernetzung in der MedTech-Branche
Zusammenfassend erfordert die Anbindung eines MedTech-Geräts immer eine gründliche Analyse und sorgfältige Konzeptentwicklung. Insbesondere bestehende Produktlinien können dabei eine Herausforderung darstellen. Trotzdem ist es in nahezu allen Fällen möglich, eine wirtschaftlich sinnvolle und nutzbringende, sichere Lösung zu finden. Bei der Entwicklung neuer Produkte ist es entscheidend, von Beginn an die Konnektivität mitzudenken.
Wenn du eine bestehende Geräteserie vernetzen möchtest oder eine Neuentwicklung mit Datenanbindung planst, zögere nicht, uns zu kontaktieren. Wir unterstützen Dich dabei, Deine Geräte erfolgreich „online“ zu bringen.
MedTech jetzt erfolgreich digitalisieren

{kind=link}