
Cloud Bursting – Wie man mit Kubernetes die Hybrid Cloud zum Platzen bringt
In den vergangenen sechs Monaten haben wir uns im Rahmen einer Masterarbeit mit dem Thema Hybrid Cloud auseinandergesetzt. Ziel war es, eine Hybrid Cloud mit Kubernetes und Cloud Bursting für eine Beispielanwendung umzusetzen.
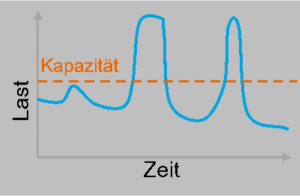
Doch was genau bedeutet denn nun Cloud Bursting? Der Begriff stammt aus dem Englischen „to burst“ – zu Deutsch „platzen“. Es geht darum, Anwendungen im privaten Teil einer Hybrid Cloud bei steigender Last durch Public-Cloud-Ressourcen zu erweitern. Die Private Cloud platzt also auf und wird – wenn man so will – von der Public Cloud aufgefangen.
| Die Hybrid Cloud ist eine Lösung, die eine Private Cloud mit einem oder mehreren Public Cloud Services kombiniert und mittels proprietärer Software eine Kommunikation zwischen unterschiedlichen Services ermöglicht. Hybrid Cloud Services sind leistungsfähig, weil sie Unternehmen eine bessere Kontrolle ihrer privaten Daten ermöglichen. Eine Organisation kann vertrauliche Daten in einer Private Cloud oder in einem lokalen Rechenzentrum speichern und gleichzeitig von den robusten Rechenressourcen einer verwalteten Public Cloud profitieren. https://www.citrix.com/de-de/glossary/what-is-hybrid-cloud.html |
Für welche Anwendungen ist das interessant? Es ist hauptsächlich dann spannend, wenn die Last stark schwankt. Eine gewisse Grundlast wird durch die private Cloud abgedeckt und die Spitzen skalieren automatisch in die Public Cloud. So fallen dort auch nur Kosten an, wenn die Ressourcen benötigt werden.
Use Case Machine Learning
Machine Learning (kurz ML) kann ziemlich viel Ressourcen und Zeit in Anspruch nehmen. Neuronale Netze zur Bilderkennung, welche für das ImageNet Projekt trainiert wurden, benötigen mittlerweile nur noch wenige Minuten Trainingszeit. Dafür müssen jedoch mehrere Knoten mit jeweils mehreren GPUs zur Beschleunigung eingesetzt werden1 . Gleichzeitig unterscheidet sich die Auslastung beispielsweise von der eines Web-Servers. Während dieser potenziell unendlich lange läuft, ist das Training eines neuronalen Netzes irgendwann abgeschlossen. Beim maschinellen Lernen können deshalb erhebliche Schwankungen entstehen.
In der Beispielanwendung sollen Trainingsdaten auf eine hybride Cloud-Plattform hochgeladen werden. Das Training erfolgt mit der Python-Bibliothek Keras, welche über eine einfache API verfügt und verschiedene Beispiele bereitstellt. Es können jedoch auch andere Frameworks oder Bibliotheken genutzt werden. Zu Beginn des Trainings werden die Trainingsdaten von der Plattform heruntergeladen. Daraufhin wird das eigentliche Learning ausgeführt. Zum Schluss wird das fertige Modell auf die Plattform hochgeladen. Ob das Training nun im privaten oder im öffentlichen Teil stattfindet, muss automatisch von der Hybrid Cloud entschieden werden.
Technische Hürden: Kommunikation einzelner Services
Innerhalb eines Kubernetes Clusters können einzelne Services miteinander kommunizieren. Jeder Service bekommt dazu seinen eigenen clusterinternen DNS-Eintrag. In der Regel besteht ein Cluster aus mehreren Knoten. Auf welchem ein Container ausgeführt wird, wird von Kubernetes entschieden. In einer Hybrid Cloud existieren mindestens zwei Cluster. Idealerweise verhalten sich diese wie ein großer Cluster. Daraus entstehen folgende Herausforderungen:
- Cross-Cluster-Kommunikation: Services können über Clustergrenzen hinweg untereinander kommunizieren, als wären sie alle im selben Cluster.
- Multicluster-Scheduling: Kubernetes Pods werden automatisch in einem freien Cluster platziert.
Technische Umsetzung durch Cross-Cluster Kommunikation und Multicluster-Scheduling
Zum Glück gibt es für beide Probleme Lösungen aus der Kubernetes-Community. Für die Cross-Cluster-Kommunikation kann das Service Mesh Istio als Mulitcluster-Installation eingesetzt werden. Dies hat den schönen Nebeneffekt, dass automatisch sämtlicher Netzwerkverkehr über mutual TLS (mTLS) verschlüsselt wird. Andere Lösungen wie Cilium oder Linkerd verfügen über ähnliche Funktionen.
Das Multicluster-Scheduling kann über den gleichnamigen Multicluster Scheduler von Admiralty erreicht werden. Dessen Einsatz ist außerdem im Blogbeitrage Running Argo Workflows Across Multiple Kubernetes Clusters auf deren Website erläutert.
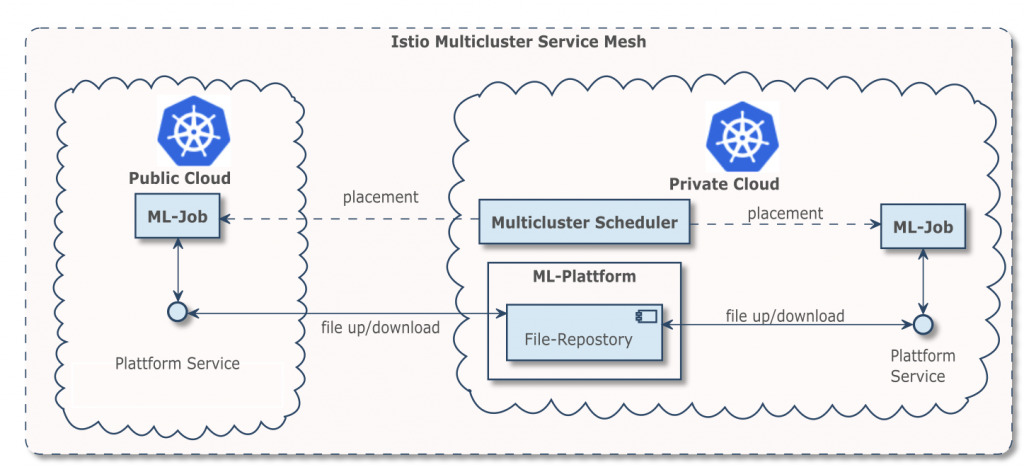
Was bedeutet dies nun für unseren Use Case? Durch den Einsatz von Istio können die Trainingsdaten aus jedem Cluster der Hybrid Cloud heruntergeladen werden, ohne dass dafür extra Freischaltungen nötig sind. Über den Ausführungsort des Machine Learnings entscheidet der Multicluster Scheduler.
Damit das Bursting auch funktioniert, muss in der Public Cloud das Autoscaling für den Kubernetes Cluster aktiviert werden. So werden bei steigender Last automatisch neu Konten zum Cluster hinzugefügt.
Test der Beispielumgebung
Natürlich haben wir die Beispielanwendung einem Test unterzogen. Dabei wurden in kurzer Zeit eine große Menge an ML-Jobs erstellt und ausgewertet in welchem Cluster sie ausgeführt wurden. Die Erwartung war, dass zunächst der private Cluster genutzt wird und im Anschluss der öffentliche. Im Test hat dies größtenteils auch funktioniert, allerdings wurden einzelne Jobs schon in die Public Cloud „geburstet“, als in der Private Cloud noch ausreichend Kapazität verfügbar war. Hier offenbart sich eine aktuelle Schwäche des Schedulers. Seine Entscheidungen lassen sich nur schwer nachvollziehen oder beeinflussen. Die Möglichkeit Cluster zu gewichten könnte Abhilfe schaffen. Dann könnte dem privaten Cluster eine höhere Priorität zugewiesen werden. Da sich das Projekt aber noch in der Beta-Phase befindet, ist eine Umsetzung in Zukunft in Betracht zu ziehen.
Fazit: Wie lässt sich Cloud Bursting implementieren
Cloud Bursting lässt sich basierend auf Kubernetes, Istio und dem Multicluster Scheduler implementieren. Es kann helfen, die Cloud bei Lastschwankungen besser zu nutzen. Der Funktionsumfang des Schedulers lässt aktuell noch ein Feature zur Priorisierung von Clustern vermissen. Es sind einige weitere Projekte zur Mulitcluster-Verwaltung in der Entstehung. Dazu zählen z. B. Kubernetes Federation, Submariner oder Google Anthos. Es bleibt also weiterhin spannend.
Simon Mennig hat diesen Blogbeitrag im Rahmen seiner Thesis „Herausforderungen bei einer Hybrid Cloud“ verfasst.
