
Extraktion strukturierter Daten aus Tankbelegen: So wird die Reisekostenabrechnung endlich effizient
12 Millionen Geschäftsreisende gab es 2018 nach Angaben der Geschäftsreisenanalyse 2019 des VDR (Verband Deutsches Reisemanagement e.V.)1 und damit einen ganzen Berg an Reisekostenabrechnungen, die es zu bearbeiten gilt – für Arbeitnehmer und in den Unternehmen. In Zeiten von KI und Digitalisierung setzen allerdings nur 13 % der befragten Unternehmen (10-500 Mitarbeitern) eine vollständige digitale Reisekostenabrechnung um1. Auch bei uns – einem Softwareunternehmen – ist die Reisekostenabrechnung noch nicht vollständig automatisiert. Daher haben wir uns in Form einer Thesis mit möglichen Verfahren der Informationsextraktion beschäftigt, um diesen Prozess digitalisieren zu können.
Fehlende Normierung behindert Automatisierungsprozess
Ein Teilproblem der vollständigen Automatisierung ist das Fehlen einer Normierung für Rechnungen über Kleinstbeträge – auch bekannt als Belege. Dies erschwerte ein automatisiertes Extrahieren der gesuchten Daten enorm. Zeit für die Digitalisierung des Prozesses durch Umsetzung eines Systems zur automatischen Extraktion von Daten aus Tankbelegen. Das System gliedert sich dabei in drei Teilprobleme, die es zu lösen gilt:
Vorverarbeitung des Eingabebildes
Der erste Schritt zur Digitalisierung eines Dokumentes ist das Umwandeln des bedruckten Papiers in eine Datei. Dazu kann entweder ein Scanner oder eine Fotokamera verwendet werden. Das Resultat aus beiden Vorgängen ist eine Bilddatei. Hier ein Beispiel, das mithilfe einer Handykamera aufgenommen wurde:

Um dieses Bild für eine Textextraktion zu optimieren, muss dieses in seine binäre Darstellung umgewandelt werden – dies erreichen wir durch eine sogenannte Binarisierung. Das Ziel einer Binarisierung ist, dass alle Pixel nur noch die Werte „eins“ (Vordergrund / Schrift) oder „null“ (Hintergrund) erhalten. Dadurch lässt sich der Text vom Hintergrund separieren. Voraussetzung hierfür ist ein Bild in Graustufen, denn bei der Binarisierung wird versucht eine Schwelle für Grauwerte zu berechnen, damit ein Pixel eindeutig als „eins“ oder „null“ identifiziert werden kann. Binarisierungsverfahren lassen sich in zwei Ansätze einteilen: Ein globaler Ansatz versucht eine Schwelle für das gesamte Bild zu finden. Ein lokaler Ansatz hingegen versucht eine Schwelle für kleine Ausschnitte des Bildes zu finden. Aber wann nun welches Verfahren nutzen? Globale Ansätze sind gut, falls das Bild in einer einheitlichen Helligkeit vorliegt. Dies ist aufgrund der per Kamera aufgenommenen Fotos allerdings nicht der Fall. Daher haben wir festgestellt, dass in das System ein lokaler Binarisierungsansatz implementiert werden muss. Nach dem Anwenden einer Binarisierung mithilfe der Methode von Sauvola – ein adaptives Binarisierungsverfahren, welches Dokumente anhand lokal adaptiver Schwellenwerte binarisiert – liegt das Bild in seiner binären Darstellung vor:

Ein weiteres wichtiges Verfahren der Vorverarbeitung ist die Korrektur des Neigungswinkels, falls das Bild schief eingescannt oder fotografiert wurde. Durch diese Korrektur kann ein Finden von Textzeilen stark vereinfacht werden. Zu diesem Zweck haben wir in das System eine Linienfindung implementiert. Diese sucht zusammenhängende Textzeilen und stellt diese als Linie dar. Anhand der Mittelung aller Winkel dieser Linien relativ zur x-Achse kann so der Neigungswinkel berechnet werden. Das Dokument muss anschließend noch im inversen Winkel rotiert werden. Durch eine Korrektur des Neigungswinkels verbessert sich die Qualität der Textextraktion erheblich. Seht selbst:
 |
 |
Quelle: https://www.kress.eu/de/news/309-deutliche-kraftstoffersparnis-erneut-nachgewiesen.html
Auslesen des Textes
Das Überführen von gescannten oder fotografierten Bildern in maschinenlesebaren Text nennt sich Optical Character Recognition (OCR). Durch diese Technologie ist es möglich, Bilder mit textuellem Inhalt durch Computersysteme erkennen zu lassen. Eine populäre Lösung hierfür ist die OpenSource OCR Engine Tesseract. Die Engine wurde ursprünglich von HP entwickelt und wird seit 2006 von Google gepflegt und erweitert2.
Um Tesseract zu verwenden, kann auf das Apache Tika Toolkit zurückgegriffen werden. Dieses Toolkit bietet unterschiedliche Parser zum Extrahieren von Daten an, unter anderem den TesseractOCRParser. Durch ihn ist eine problemlose Kopplung der Tesseract OCR Engine an eine Java Applikation möglich.
Extraktion der relevanten Informationen
Da der Text nun in maschinenlesbarer Form vorliegt, muss das System die eigentliche Informationsextraktion durchführen. Eine Bibliothek zum Finden strukturierter Informationen in unstrukturiertem Text ist Apache UIMA (Unstructered Information Management Architecture). Die Bibliothek bietet Schnittstellen zu den Programmiersprachen C++ und Java. Mit UIMA können Annotatoren entwickelt werden, die zum Beispiel auf Basis von regulären Ausdrücken Informationen aus unstrukturiertem Text extrahieren.
Alle Komponenten innerhalb von UIMA kommunizieren mithilfe der Common Analysis Structure (CAS). Die CAS ist ein Subsystem in UIMA, das den Datenaustausch zwischen UIMA Komponenten ermöglicht3. Innerhalb der CAS wird ein TypeSystem definiert, das alle Datentypen beinhaltet, die extrahiert werden sollen. In unserem Fall der Tankbelege wären das die Datentypen Sum, Date, Time, Quantity (Literzahl), Type (Kraftstoffart) und Address. Für diese Datentypen werden in dem vorher erwähnten Annotator die entsprechenden regulären Ausdrücke hinterlegt.
Im nächsten Schritt wird in das CAS der im vorhergehenden Schritt ermittelte Dokumententext eingegeben. Der Annotator durchsucht nun den im CAS hinterlegten Dokumententext und speichert die Start- und Endposition im Text, wo der jeweilige Datentyp zu finden ist. Das CAS kann anschließend nach diesen Datentypen, also den strukturierten Informationen, durchsucht werden. Eine Beispielhafte Informationsextraktion mit Apache UIMA aus dem Belegfoto (s. oben) ist im Folgenden dargestellt:
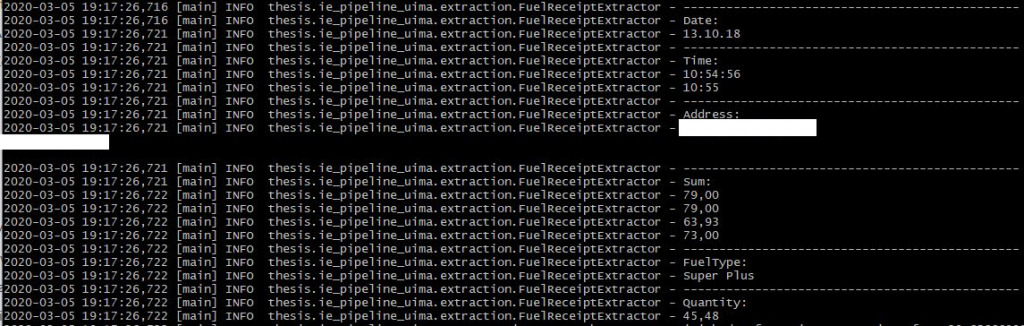
Es ist zu erkennen, dass alle Daten bis auf die Gesamtsumme korrekt extrahiert werden können. Dies hängt mit der Schwierigkeit zusammen einen regulären Ausdruck zu entwickeln, der nicht alle Eurobeträge extrahiert, sondern nur den gewünschten. Bei nicht-normierten Daten wie dem Gesamtbetrag schneidet ein KI-System besser ab, da dort der vorliegende textuelle Kontext (z.B. die Position im Gesamttext) in die Klassifizierung mit einbezogen werden kann.
Fazit
Das System zur Extraktion strukturierter Daten aus Tankbelegen ist damit fertiggestellt und erleichtert die Reisekostenabrechnung in Zukunft erheblich.
Die wichtigsten Schritte der Vorverarbeitung bei der Digitalisierung analoger Dokumente sind die Binarisierung und eine anschließende Korrektur des Neigungswinkels, da ansonsten eine Texterkennung unter Umständen deutlich schlechtere Ergebnisse liefert. Falls Dokumente vorliegen, die unterschiedliche Helligkeitsgrade aufweisen muss statt eines globalen Binarisierungsverfahren ein lokales verwendet werden.
Die Qualität der Informationsextraktion hängt stark von den entwickelten regulären Ausdrücken für den jeweiligen Datentyp ab. Es kann festgehalten werden, dass auch in Zeiten der Künstlichen Intelligenz eine regelbasierte Informationsextraktion durchaus noch eine Daseinsberechtigung besitzt, da viele Daten (wie z. B. Datum und Uhrzeit) normiert sind und dadurch eindeutige reguläre Ausdrücke zur Informationsextraktion angewendet werden können. Durch die Anbindung des Systems an die Cloudlösung „Business Filemanager“ können Tankbelege sogar von unterwegs aus direkt hochgeladen, ausgelesen und damit der Reisekostenabteilung zur Verfügung gestellt werden.
P.S: Wir haben eine Lösung gefunden, die wir zwar nicht selbst programmiert haben, aber rege nutzen: die App Lunchit®. Hierbei handelt es sich um denselben Ansatz nur für Essensbelege. Seit wir Lunchit® nutzen sparen wir erheblich Zeit in der Verwaltung. Wir müssen nun keine Essensmarken mehr ausgeben und mit den Restaurants verrechnen. Ein weiterer Pluspunkt: Arbeitnehmer sparen außerdem Zeit durch die Nutzung der App, da keine Belege oder Marken mehr abgeholt, mitgenommen und abgezählt werden müssen.
Und wie sieht es bei Dir aus – tippst Du noch Reisekostenabrechnungen manuell oder digitalisierst Du schon? Teile Deine Erfahrungen mit uns durch einen Kommentar.
