
Buzzword Dschungel Künstliche Intelligenz (KI) – die wichtigsten Begriffe auf einen Blick
In unseren Gesprächen mit Kunden und Partnern werden häufig Begriffe wie Künstliche Intelligenz (KI), Data Science oder Machine Learning in einem Atemzug genannt. Dabei schwirren zahlreiche Schlagworte durch die Gegend, die häufig gar nicht so klar voneinander abgrenzbar sind oder als Synonyme verwendet werden. Hier möchten wir Licht ins Dunkel bringen und einen kurzen und klaren Überblick über die wichtigsten Begriffe geben, diese kurz erläutern und zueinander abgrenzen.
Künstliche Intelligenz, Machine Learning, Neuronale Netze
KI bezeichnet die Automatisierung von menschlichem Verhalten. Man unterscheidet hierbei zwischen der starken und schwachen KI.

Vergleich Starke-Schwache KI
Von einer starken KI mit eigenem Bewusstsein und Empathie ist die Wissenschaft noch meilenweit entfernt. Wenn heutzutage von Künstlicher Intelligenz gesprochen wird, dann bezieht sich dies auf Anwendungsfälle im Bereich der schwachen KI. Diese Systeme sind in der Lage einzelne, klar abgegrenzte Aufgaben, wie z.B. Bilderkennung, gut zu lösen. Sie erlangen dabei aber kein tiefergehendes Verständnis des dahinterliegenden Problems und erscheinen dadurch nur nach außen intelligent.

Teilmengen Künstliche Intelligenz
Die schwache KI basiert dabei auf Methoden der Mathematik und Informatik. Ein wichtiges Subset von Methoden in diesem Bereich wird unter dem Begriff Machine Learning zusammengefasst. Neuronale Netze wiederum sind innerhalb des „Werkzeugkastens“ Machine Learning eine Methode bzw. ein Tool das eingesetzt werden kann. Innerhalb dieser Methode stellt das Deep Learning eine ganz spezielle Ausprägung eines neuronalen Netzes dar.
Data Analytics, Data Science, Data Mining
Unter Data Analytics versteht man zunächst alles was mit einer zielgerichteten Analyse von Daten zu tun hat. Auf Basis des Ergebnisses dieser Analyse sollen neue Schlussfolgerungen und Handlungsempfehlungen ermöglicht werden. Unter dem Begriff Data Analytics haben sich über die Zeit weitere Disziplinen, wie beispielsweise Data Science entwickelt.
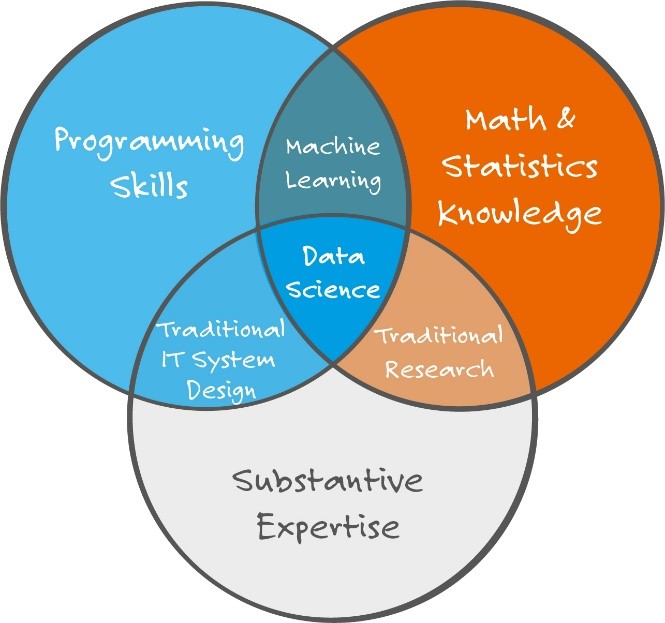
Data Science ist der Überbegriff für eine Reihe an Methoden und Algorithmen mit denen man aus Daten Wissen generieren kann. Hierzu kommen ausgereifte Verfahren aus dem Bereich Mathematik, Statistik und Informatik zum Einsatz. Um die Ergebnisse dieser Verfahren auch korrekt interpretieren zu können, ist es notwendig, dass ein Data Scientist auch ein entsprechendes fachliches Wissen (z.B. über die Funktionsweise einer Windkraftanlage) mitbringt bzw. im Verlauf eines Projekts aufbaut. Mit Data Science ist man in der Lage, sowohl strukturierte Daten (z.B. eine Tabelle mit fest definierten Attributen wie Alter, Name, etc.), unstrukturierte Daten (z.B. ein komplexer Text in natürlicher Sprache) und semistrukturierte Daten (ein Mix aus strukturierten und unstrukturierten Daten) zu analysieren.
Data Mining ist als ein Teilbereich innerhalb von Data Science zu verstehen. Ziel ist es, bisher unbekannter Querverbindungen, Trends oder Muster in großen Datenmengen zu finden. Dabei werden auch Methoden eingesetzt, die im Bereich Machine Learning Anwendung finden (z.B. Clustering). Da diese Methoden aber quasi „von Hand“ durch einen Menschen auf Daten angewendet werden, bringen Data Mining Techniken (im Gegensatz zu Machine Learning) keine selbstlernenden Mechanismen mit. Bildlich gesprochen lernt der Mensch und nicht die Maschine.
Rollen in einem Data Science Projekt
Innerhalb von Data Analytics Projekten benötigt man ganz unterschiedliche Skills und Experten. Die zugehörigen Rollen sind dabei sehr breit gefächert und oft nicht ganz klar voneinander abzugrenzen. Ein Data Scientist kann beispielsweise auch Aufgaben übernehmen, die man eher einem Data Engineer zuordnen würde und umgekehrt. So muss ein Data Scientist auch häufig Daten aufbereiten, da dies ein elementarer Bestandteil von vielen Datenanalyse-Projekten ist.

Data Science Projekt Rollen
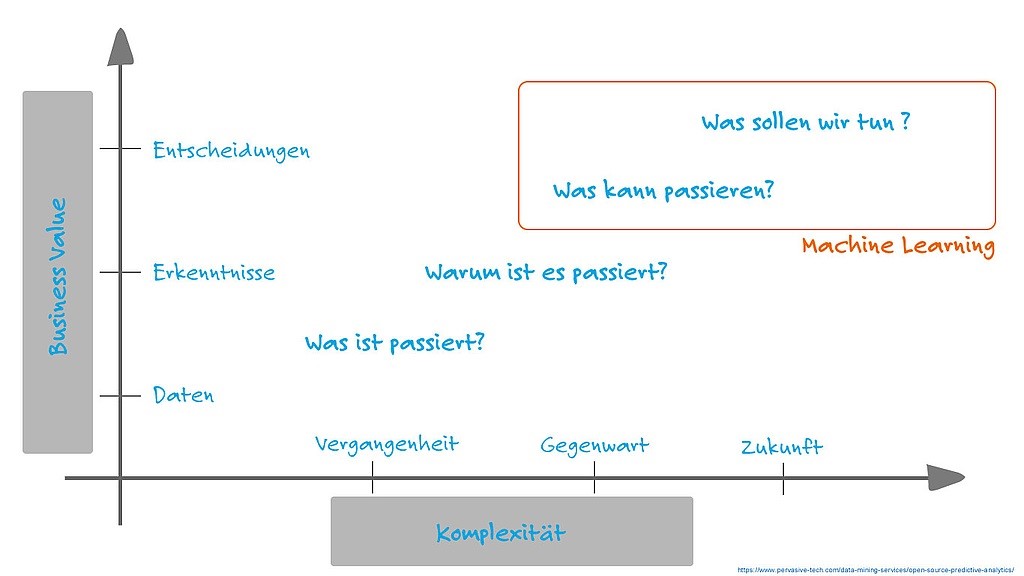
Im Data Analytics gibt es vier verschiedene Stufen, um große Datenmengen zu analysieren.

Analyseansätze im Data Analytics
Jede Stufe ist mit einer bestimmten Fragestellung verknüpft – die es gilt zu beantworten. Dabei steigt die Komplexität, um zu einer zielgerichteten Antwort auf die jeweilige Frage zu kommen. Gleichzeitig steigt aber auch der entsprechende Mehrwert der damit verbunden ist.
Business Intelligence, Advanced Analytics
Sowohl Business Intelligence als auch Advanced Analytics sind häufig verwendete Begriffe, die Verfahren und Prozesse zur Analyse von Daten des eigenen Unternehmens bezeichnen.
Business Intelligence ist der Vorreiter von Advanced Analytics, wo man durch Datenanalysen vergangene Ereignisse untersucht. Man kann Business Intelligence in den Analyseverfahren Descriptive und Diagnostic Analytics einordnen, da Fragen wie „Wie viele Produkte habe ich zu welchem Preis in welcher Region verkauft?“ beantwortet werden können.
Im Gegensatz zu Business Intelligence wird mit Advanced Analytics Methoden der Blick gezielt in die Zukunft gerichtet¹. Dadurch können Prognosen über zukünftige Ereignisse aufgestellt werden. Fragen wie „Wie viele Produkte sollen wir produzieren?“ oder „Wann soll eine Wartung durchgeführt werden?“ können beantwortet werden. So ist Advanced Analytics unter den Predictive und Prescriptive Analytics Verfahren einzuordnen.
ETL, Big Data, Data Lake, Data Discovery, Data Exploration
ETL bedeutet Extract, Transform und Load und ist die Grundlage für die Befüllung von Data Warehouse und eine Basistechnologie zur Datenintegration. Zuerst werden die Daten extrahiert aus ein oder mehreren Quellen, dann transformiert in ein gewünschtes Zielformat und zuletzt an einen Zielort abgelegt.
Volume, Variety und Velocity sind die drei Dimensionen von Big Data. Was bedeutet, dass dieses Phänomen sich aus rasant (Velocity) steigender (Volume) Daten unterschiedlicher Art (Variety) ergibt. Daraus ergeben sich sowohl Herausforderungen wie das Speichern, Verwalten, als auch Chancen wie Möglichkeiten diese Daten auszuwerten.
In einem Data Lakewerden strukturierte und unstrukturierte Daten aus verschiedenen Datenquellen zusammengeführt mit dem Ziel, die verschiedenen, isolierten Datensilos eines Unternehmens aufzubrechen und die Daten an einen zentralen Ort zusammenzuführen. Auf diesen, dort gespeicherten Rohdaten können dann weitergehende, komplexe Datenanalysen durchgeführt werden.
Der Discovery Prozess im Bereich Data Discovery deckt die Erforschung und die Vorbereitung der Daten ab. Der Prozess kann mit einem initialen Qualitätscheck starten. Um eine erste Einschätzung zum Potential der Daten zu erhalten, kann ein simples Machine Learning Model angewandt werden. Der Discovery Prozess dient dazu erste Hypothese, Ideen oder Datenpotential ausfindig zu machen.
Als Weiterführung von Data Discovery wird in Data Exploration nach „tieferen“ Entdeckungen gesucht, welche zu einem ersten Prototyp führen können. Ziel ist es die gewünschte Lösung festzulegen, damit sie nicht vom Ziel abweicht.
FAZIT: Buzzword Dschungel KI – viele Wege führen zum Mehrwert aus Daten
Im Laufe der Zeit ist eine Vielzahl an Begrifflichkeiten rundum KI entstanden, die sich häufig in Teilen überlappen und auch nicht immer ganz 100% klar voneinander abgegrenzt werden können. Bei genauerer Betrachtung stellt man fest, dass sich hinter jedem Buzzword eine eigene, häufig sehr spezialisierte Wissensdomäne versteckt, die mit einem entsprechenden technologischen und methodischen Know-How verbunden ist. Sie alle haben aber gemein, dass sie versuchen, neue Informationen und damit einen Mehrwert aus Daten zu generieren. Mit diesem Beitrag haben wir versucht, die Abgrenzungen und auch die Überschneidungen deutlich zu machen.
Co-Autorin Christina Reiter
¹https://www.alexanderthamm.com/de/
Wollen Sie mehr Durchblick im KI Dschungel? Hier entlang …
