
Gas und Geruchsanalyse mit Künstlicher Intelligenz
Gase sind allgegenwärtig und tragen wertvolle Informationen über die Umwelt in sich. In diesem Blogpost wird beschrieben, wie man Gas-Messdaten erfassen und mittels Methoden aus dem Bereich der Künstlichen Intelligenz auswerten kann.
Warum sollte man Gase analysieren?
Gase umgeben uns ständig und tragen eine Vielzahl an Informationen in sich. Unsere Nase ist nichts anderes als ein Zusammenschluss vieler verschiedener Gassensoren mit denen wir unsere Umwelt erfassen und analysieren. Riechen wir beispielsweise eine sauer gewordene Milch, wissen wir dass sie verdorben ist.
Die Idee Gase zu analysieren kann man nun weiter spinnen. Alles was Gase ausstößt kann analysiert werden. Diese Idee hat besonderes Potenzial für die Bereiche Medizin und Umweltüberwachung. Ein Teil der aktuellen Forschung beschäftigt sich damit, herauszufinden, ob Krankheiten durch die Analyse der Atemluft diagnostiziert werden können 1, 2.
Wie misst man Gase?
Klassischerweise werden zum Erfassen und Messen von Gasen sogenannte Metall-Oxid-Halbleiter (MOS)-Sensoren verwendet. Der Widerstand des eingesetzten Halbleiters ist dabei abhängig von dem Vorkommen an Gasen in der Luft. Durch die Änderung dessen Widerstands kann auf das Vorkommen von Gasen in der Umgebung geschlossen werden. Die Schwierigkeit bei der Identifikation von Gasen liegt darin, dass die Sensoren nicht nur auf ein Gas/ Molekül reagieren, sondern auf mehrere. Daher kann nicht mit Sicherheit auf ein einzelnes Gas geschlossen werden. Eine Möglichkeit das zu Verbessern, ist die Verwendung mehrerer Sensoren. Die Änderung einzelner Sensorwerte können wie eine Art Fingerabdruck interpretiert werden, welche einem speziellen Gas oder einer Quelle zugeordnet werden können. Ein weiterer Vorteil der Verwendung von mehreren Sensoren ist, dass viele verschiedene Gase erfasst werden können und sich somit auch mehr Einsatzmöglichkeiten ergeben.
Wie analysiert man Gase?
Für die Analyse von Messdaten gibt es viele Verfahren. Weit verbreitet sind statistische Verfahren wie die Principal-Component-Analysis (PCA) und die Linear-Discriminant-Analysis (LDA). Eine weitere Möglichkeit zur Analyse ist die Nutzung Künstlicher Intelligenz. Gerade mit dem Boom der Künstlichen Intelligenz stellt sich die Frage, ob deren Verwendung nicht eine noch bessere Analyse als die statistischen Analysen, ermöglicht.
Principal-Component-Analysis (PCA):
Die Principal Component Analysis (PCA) ist eine statistische Methode mit welcher ein Koordinatensystem aus Sicht der Daten erstellt wird und auch die Dimension von Daten reduziert werden kann. Das bestimmte Koordinatensystem richtet sich Anhand der Varianz der Dimensionen (Bsp: x-y-z-Achsen) aus. Die Achsen des neuen Koordinatensystems werden als Hauptkomponenten bezeichnet und bilden sich aus Linearkombinationen der Variablen. Die Wichtigkeit der Hauptkomponenten, zum Beschreiben der Varianz des Datensatzes, ist absteigend geringer. So ist die erste Hauptkomponente die wichtigste, danach kommt die zweite usw. Die Abbildung der (Mess-)Daten in das neue Koordinatensystem berücksichtigt Korrelationen zwischen Variablen, was die Verarbeitung erleichtert. Zudem können die (Mess-)Daten in ihrer Dimension reduziert werden, indem unwichtigere Hauptkomponenten entfernt werden.
Die PCA ist ein mächtiges Tool, welches häufig in der Datenanalyse verwendet wird. Eine Veranschaulichung der Analyse ist in dem folgenden Bild zu sehen. Darin wird auf die Rohdaten (links) eine PCA angewendet. Die bestimmten Hauptkomponenten orientieren sich an der Varianz des ursprünglichen Datensatzes. Eine Darstellung der transformierten Rohdaten in den Hauptkomponenten ist auf der rechten Seite zu sehen.
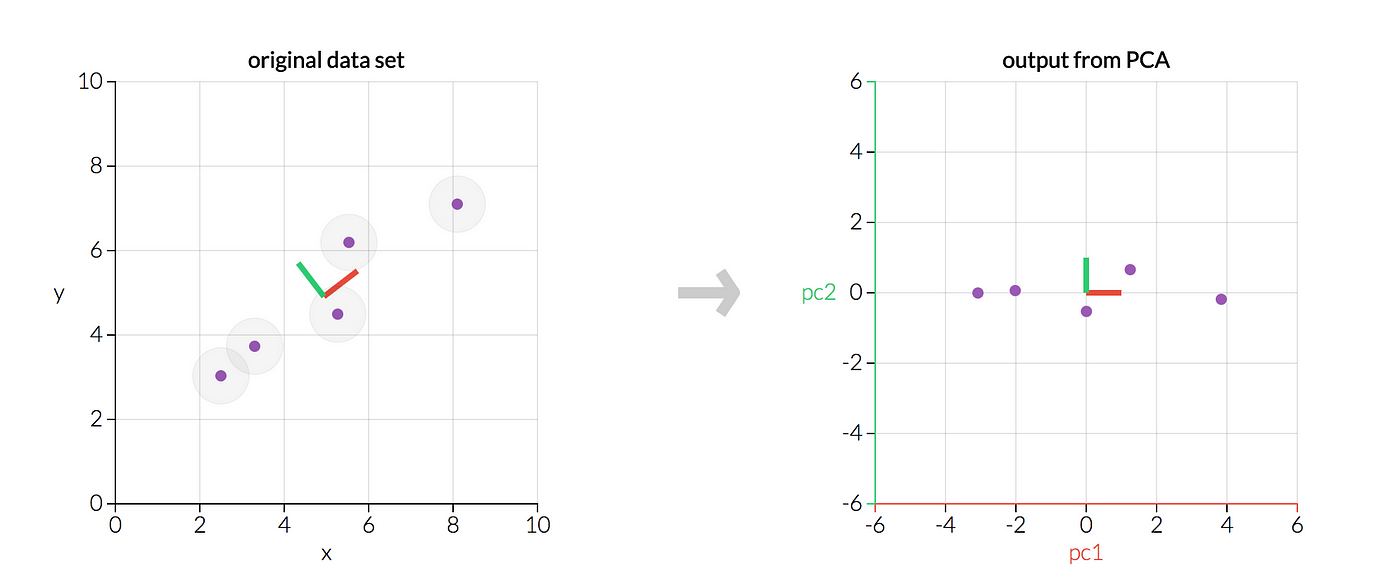
Die wichtigsten Features der PCA sind:
- Erstellt ein Koordinatensystem aus Sicht der Daten
- Ermöglicht eine Reduktion der Daten, wobei der Grad an Informationsverlust selbst bestimmt werden kann
- Ähnliche Daten clustern sich in dem neuen Raum
Um Daten nun klassifizieren zu können, kann der k-Nächste-Nachbarn-Klassifikator verwendet werden. Dabei werden von einem unbekannten Datenpunkt die k-Nächsten-Nachbarn und deren Klassen betrachtet. Die am häufigsten vorkommende Klasse wird dann ausgewählt. Dargestellt ist das noch einmal in dem folgenden Bild.
Wer sich genauer mit der PCA auseinandersetzen möchte, sollte sich das Video von StatQuest mit Josh Starmer oder Computerphile dazu anschauen.
Linear-Discriminant-Analysis (LDA):
Die Idee der LDA liegt darin lineare Kombinationen in den (Mess-)Daten zu finden, sodass sich Daten verschiedener Klassen maximal voneinander separieren, wobei die Streuung innerhalb einer Klasse minimal sein soll. Die Klassen werden dabei durch Geraden voneinander getrennt. Dies ist auch in dem Bild dargestellt.
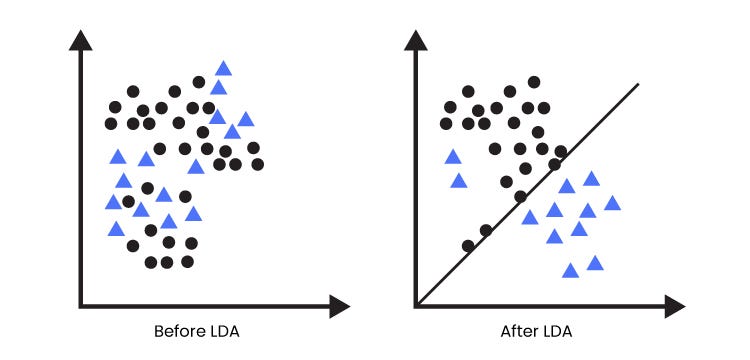
Für die Bestimmung der Transformationen müssen die Klassen von Datenpunkten bekannt sein. Anhand dieser Daten kann dann erlernt werden, anhand welcher Features sich zwei Klassen unterscheiden lassen. Da bei diesem Verfahren „gelernt“ wird, gilt diese Analyse schon zu den Machine Learning – Algorithmen. Durch das Trennen der Klassen anhand der Geraden können unbekannte Daten ohne einen weiteren Klassifikator klassifiziert werden. Es muss nur untersucht werden, auf welcher Seite der Geraden sich der Datenpunkt befindet und welche Klasse damit definiert wurde.
Für weitere Informationen dazu kann ich das Video von StatQuest mit Josh Starmer empfehlen.
Neuronale Netze:
Neuronale Netze sind Lernmodelle, welche dem menschlichen Gehirn nachempfunden sind. Sie bestehen aus künstlichen Neuronen, welchen in Schichten miteinander verbunden sind und die Daten verarbeitet. Um zu Lernen, wie die Daten verarbeitet werden müssen, trainieren diese auf Testdaten um Muster und Eigenschaften verschiedener Klassen zu erkennen. Die Eigenschaften können hierbei einzelne Werte oder Kombinationen aus mehreren Variablen sein. Das untere Netzwerk zeigt ein neuronales Netz mit 3 Schichten. Die erste Schicht wird Input-Layer genannt und die letzte Output-Layer. Dazwischen können sich mehrere Hidden-Layer befinden, welche für das Verarbeiten der Daten zuständig sind.

Wer sich damit näher auseinandersetzen möchte sollte sich diese Serie von 3Blue1Brown anschauen.
Testgegenstand:
Um zu schauen, was bei einer Gas-Analyse zu beachten ist und was alles möglich ist, wurden zwei Fragestellungen erstellt:
- Wie gut lassen sich von Menschen unterscheidbare Gerüche erfassen und unterscheiden?
- Lässt sich der Zustand einer Banane über deren emittierte Gase bestimmen?
Für die Untersuchungen wurde das im folgende Bild zu sehende Sensor-Board (Smell-Board) verwendet, welches 15 verschiedene Gase erkennen kann. Die weißen Chips an der Oberfläche sind die Sensoren.

Versuchsdurchführung:
Machbarkeitsanalyse:
Um zu Testen was bei dem Erfassen und Analysieren von Gasen beachtet werden muss, wurde zuerst eine Test-Untersuchung gemacht, um Festzustellen was bei der Erhebung der Daten beachtet werden muss. Dabei ergaben sich folgende Erkenntnisse und Einflussfaktoren:
- Die absoluten Messwerte können für flüchtige Gase nicht verwendet werden. Die Gase in einem normalen Raum ändern sich kontinuierlich. So kann es sein, dass zwei Mal dasselbe Objekt gemessen wird, die Umgebung sich allerdings so verändert hat, dass die Messwertewerte der beiden Messung aber nicht miteinander verglichen werden können. Daher müssen relative Werte verwendet werden. Dafür muss ein Referenzwert bestimmt werden, welcher die Umgebung abbildet. Innerhalb eines kurzen Zeitraums, können nachfolgende Messungen damit verglichen und zur Analyse verwendet werden.
- Wasser hat einen starken Einfluss auf die Messdaten. Selbst wenn kein Wasser zu sehen ist, konnte nachgewiesen werden, dass die Messwerte davon beeinflusst werden.
- Die zur Messung verwendeten Materialien (Behältnisse) dürfen keine Gase adsorbieren oder emittieren. Als neutrale Materialien wurden Glas und Keramik festgestellt.
Untersuchung 1 – Unterscheidung verschiedener Gerüche:
Um zu Untersuchen wie gut Gase voneinander unterscheidbar sind wurden einige intensive und sich stark unterscheidende Gerüche ausgewählt. Die Wahl dieser Stoffe geht auf das Geruchsmodell von John Amoore zurück 3. Dabei wurden folgende Proben verwendet:
- Eukalyptusöl
- Essigessenz (ersetzt Ameisensäure aus dem Modell)
- Schwefelkleber
- Dichlorethan-1,2
- Campher
Für die Messung der Gerüche wurden die Stoffe in eine Tasse gegeben, das Sensor-Modul für eine Minute darüber gehalten und dabei die Messwerte ermittelt. Somit ergaben sich folgende durchschnittlichen Messkurven:

Untersuchung 2 – Sensitivität in der Unterscheidbarkeit:
Für die Untersuchung wie gut geringe Unterschiede an Gasen messbar und analysierbar sind, wurde die Gase von Bananen über mehrere Tage gemessen. Damit soll es später möglich sein, den Zustand einer Banane alleine anhand der emittierten Gasen zu bestimmen. Für das Erstellen des Datensatzes wurden 4 Bananen verwendet, und deren Zustand über 11 Tage hinweg protokolliert. Bei einer Messung wurde das Sensor-Modul für 30 Sekunden über eine Banane gestellt und so die emittierten Gase gemessen.

Ergebnisse:
Für die Analyse der Messdaten wurden immer 5 aufeinanderfolgende Einzelmessungen verwendet. Für die Analyse wurden die oben beschriebenen Methodiken wie PCA, LDA und neuronalen Netzwerken, und deren Leistungsfähigkeit, getestet. Zusätzlich wurden bei den neuronalen Netzen mehrere Einstellungen getestet.
Untersuchung 1 – Unterscheidung verschiedener Gerüche:
| Methodik | Genauigkeit in % | |
| Statistische Analysen | PCA | 95,4 |
| LDA | 94,9 | |
| Neuronale Netzwerke | Rohdaten | min 97,8 – overfitten (Das Netzwerk hat sich zu sehr an die Trainingsdaten angepasst und generalisiert schlecht) allerdings schnell |
| Skalierung/ Normalisierung + PCA | 98,8 | |
| Skalierung/ Normalisierung + LDA | 98,9 |
Wie man sieht, lassen sich verschiedene Gerüche sehr gut voneinander unterscheiden. Die Verwendung von neuronalen Netzen brachte bei diesem Versuch eine nur geringfügig Verbesserung im Vergleich zu den statistischen Analysen.
Untersuchung 2 – Sensitivität in der Unterscheidbarkeit (Banane):
| Methodik | Genauigkeit in % | |
| Statistische Analysen | PCA | 77,7 |
| LDA | 63,2 | |
| Neuronale Netzwerke | Rohdaten | min. 75 – overfitten allerdings schnell |
| Skalierung/ Normalisierung + PCA | 88,1 | |
| Skalierung/ Normalisierung + LDA | 64,1 |
Bei der Analyse von komplexeren Messwerten ist die Verwendung von neuronalen Netzwerken den einfachen statistischen Analysen überlegen. Als beste Kombination stellte sich die Verwendung einer Skalierung der Daten, folgend die Anwendung einer PCA und danach eine Verarbeitung durch ein neuronales Netz, heraus.
Fazit:
Datenerfassung:
Es zeigte sich, dass sowohl verschiedene Gerüche voneinander unterschieden werden können, als auch, dass diese weitergehend analysiert werden können. Die Erstellung eines statistisch korrekten Datensatzes ist allerdings sehr schwer, da sehr viele Faktoren wie Temperatur, Luftfeuchtigkeit, etc. berücksichtigt werden müssen. Viele Faktoren sind wahrscheinlich auch nicht bekannt. Zudem ist die Aufnahme der Daten sehr zeitintensiv, da vor allem das Lösen der Gas-Moleküle von den Sensoren viel Zeit benötigt.
Datenverarbeitung:
Die Auswertung verschiedener Gerüche ist mit statistischen Verfahren fast genauso effektiv wie die mit neuronalen Netzen. Sollen komplexere Daten analysiert werden, ist die Verwendung von neuronalen Netzen allerdings sinnvoll. Bevor die Daten von einem neuronalen Netz verarbeitet werden, sollten diese skaliert und normalisiert werden. Zudem ist die Anwendung einer PCA darauf sinnvoll, da die Datenbasis somit kleiner wird und die neuronalen Netze schneller lernen können. Bei der Verwendung von neuronalen Netzwerken, sollten die Netzwerke relativ einfach gehalten werden, indem wenig Hidden-Layer mit wenig Neuronen verwendet werden.
Toolchain:
Die Datenauswertung wurde in Python gemacht, da diese gerade im KI-Umfeld sehr beliebt ist. Dabei wurden die gängigsten Bibliotheken verwendet. Diese sind:
- Statistische Auswertung der Daten: scikit-learn
- Neuronale Netze: TensorFlow / Keras
- Darstellung der Daten: Matplotlib, Plotly
[1] Smart Phone for Disease Detection from Exhaled Breath
[2] Screening of Gastric Cancer via Breath volatile organic compounds by Hybrid Sensing Approach
[3] Biologische Psychologie Seite 448
[4] StatQuest – PCA
[5] Scikit – PCA
[6] Springer – Principal Component Analysis
[7] Towards Data Science – LDA,
[8] StatQuest – LDA
