
Real-Life Example: Fixing a Bad Performing Large Postgres Table
There is a table with more than 1 TB size. The task is to shrink this table. But the table data cannot be queried at all. No matter how simple a query is, it is still running after one day. The question is: what is wrong with the table?
1) The case …
In one of our projects there was a planned Postgres database migration to Azure. The database was unnecessarily large with 1.5 TB and the requirement was to shrink it before the migration. There was one table in particular that was huge and which was taking most of the space (nearly 1,4 TB).
Facts about the table:
The table contains the average availability of each service per month.
report_date|service_id|average_availability| -----------+----------+--------------------+ 2022-06-01| 10001| 0.071| 2022-06-01| 10002| 0.568| 2022-06-01| 10003| 0.939| 2022-06-01| 10004| 0.813| 2022-06-01| 10005| 0.208| ... 2022-07-01| 10001| 0.261| 2022-07-01| 10002| 0.919| 2022-07-01| 10003| 0.876| 2022-07-01| 10004| 0.282| 2022-07-01| 10005| 0.866| ... 2022-08-01| 10001| 0.949| 2022-08-01| 10002| 0.180| 2022-08-01| 10003| 0.245| 2022-08-01| 10004| 0.513| 2022-08-01| 10005| 0.665| ...
Only the reports of the last 3 months are kept. The table should therefore remain constant in size. However, it has been growing steadily for months.
In addition, it is no longer possible to receive a result when querying the table:
SELECT * FROM monthly_service_availability_average LIMIT 100; --> still running after 1 day SELECT COUNT(*) FROM monthly_service_availability_average; --> still running after 1 day
The table DDL:
CREATE TABLE monthly_service_availability_average
(
report_date DATE NOT NULL,
service_id INTEGER NOT NULL,
average_availability NUMERIC(4, 3) NOT NULL
);
CREATE INDEX idx_report_date_service_id
ON monthly_service_availability_average (report_date ASC NULLS LAST, service_id ASC NULLS LAST);
2) The vacuum thing …
… or asking: Why is my table so big, despite regular deletions?
First, let’s have a look at the table’s statistics:
SELECT relname, n_dead_tup, n_live_tup
FROM pg_catalog.pg_stat_user_tables
WHERE relname IN ('monthly_service_availability_average');
relname | n_dead_tup | n_live_tup | --------------------------------------+----------------+---------------+ monthly_service_availability_average | 12.182.609.290 | 1.032.253.612 |
This means that there are 12 billion deleted data (dead tuples) and 1 billion still valid data (live tuples) in the table.
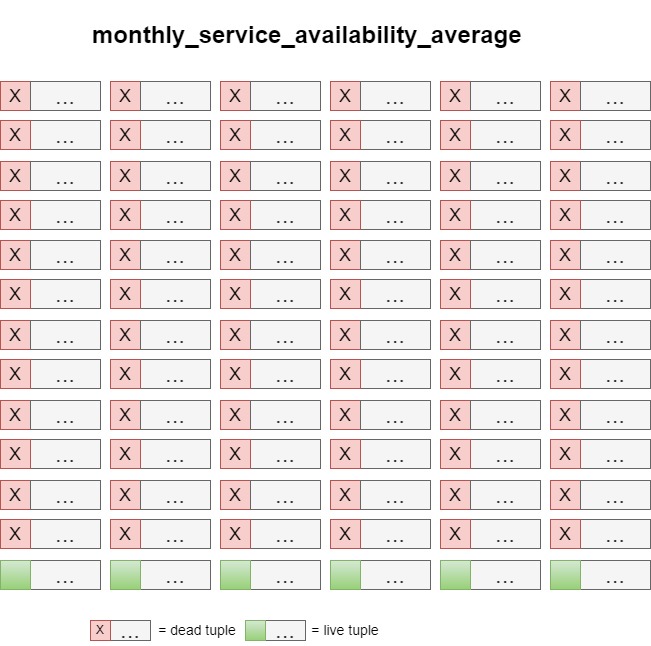
Why is the deleted data still there?
It is similar to the recycle bin on your PC. The data is still there, but marked as deleted. This is in case someone else still wants to access the data. For example, there is an open transaction that is currently running a query. For data consistency reasons it is important to return the data which existed at the start of the query. This is called Multi Version Concurrency Control (MVCC), which Postgres achieves by keeping the old versions marked as dead. [1]
The vacuum job is responsible for finally cleaning up the data. It checks which data is no longer needed and deletes it permanently. In other words, it makes room for new entries. The last automatic vacuum ran on 20.08.2022, 9 months ago. So it has not been cleaned up for a long time.
SELECT relname, NOW() now_, last_autovacuum
FROM pg_catalog.pg_stat_user_tables
WHERE relname IN ('monthly_service_availability_average') ;
relname |now_ | last_autovacuum | ------------------------------------+-----------------------------+-------------------------------+ monthly_service_availability_average|2023-05-11 13:35:54.718 +0200| 2022-08-20 07:59:21.342039+00 |
3) The thing with count(*)
… or asking: Why do my queries run forever?
SELECT * FROM monthly_service_availability_average LIMIT 100; --> still running after 1 day
The explanation is quite simple: You need to search the whole table. Including all records marked as deleted. The specific search via an index is not possible here. Due to the large number of deleted records (> 12 billion), the active data will not be reached for a very long time.
What about the count(*) query?
EXPLAIN SELECT COUNT(*) FROM monthly_service_availability_average;
QUERY PLAN | --------------------------------------------------------+ Aggregate (cost=232772.69..232772.70 rows=1 width=8) | -> Seq Scan on monthly_service_availability_average |
Currently it is also searching through the whole table (sequential scan). Shouldn’t an index only scan be faster here to count the data? The index also contains all entries, needed for counting. And the index has less columns, and is therefore smaller. This will speed up the counting as less data blocks have to be read. [2]
Why is there no index only scan?
The problem is the implementation in Postgres: There is no index only scan in Postgres. The reason for this is that the index also contains all deleted entries (as someone might still need them). Furthermore, these are not marked as deleted. Instead, the index has to run to the table for each entry to check if it still exists. This makes counting via the index even more time-consuming than counting directly on the table. [3]

Even if the execution plan indicates an index-only scan, as it can be achieved by filtering to the current month, it is no real index only scan. In the background, Postgres is still checking the table entries to see if they still exist.
EXPLAIN SELECT COUNT(*) FROM monthly_service_availability_average WHERE report_date = '2023-03-01';
QUERY PLAN |
-----------------------------------------------------------------------------------------------+
Aggregate |
-> Index Only Scan using idx_report_date_service_id on monthly_service_availability_average |
Index Cond: (report_date = '2023-03-01'::date) |
4) About using the index for ORDER BY …
… or asking: How do I get my data?
Only the last 10% of the table entries are filled. The first 90% is deleted data. Theoretically, the table should be searched in reverse order, meaning the live tuples will be passed first.
This is actually possible. An index can also be used to specifically return the first x entries in the sorting order of the index. [4]
The index search can also be reversed. To do this, you have to specify the reverse order of the index in the GROUP BY.
For the index
CREATE INDEX idx_report_date_service_id ON monthly_service_availability_average (report_date ASC NULLS LAST, service_id ASC NULLS LAST);
searching via index in normal order, the group by must be the same as in the definition of the index
EXPLAIN SELECT * FROM monthly_service_availability_average ORDER BY report_date ASC NULLS LAST, service_id ASC NULLS LAST LIMIT 100;
QUERY PLAN | -------------------------------------------------------------------------------------------+ Limit | -> Index Scan using idx_report_date_service_id on monthly_service_availability_average |
For doing a reverse search, the order by parts need to be reversed. Instead of searching ASCENDING, now the search needs to be DESCENDING. And the order of the NULL values need to be reversed as well, to NULLS FIRST.
EXPLAIN SELECT * FROM monthly_service_availability_average ORDER BY report_date DESC NULLS FIRST, service_id DESC NULLS FIRST LIMIT 100;
QUERY PLAN | ---------------------------------------------------------------------------------------------------+ Limit | -> Index Scan Backward using idx_report_date_service_id on monthly_service_availability_average |

With this approach it is finally possible to query the table for the last 100 entries:
report_date|service_id|average_availability| -----------+----------+--------------------+ 2023-04-01| 11000| 0.627| 2023-04-01| 10999| 0.868| 2023-04-01| 10998| 0.614| 2023-04-01| 10997| 0.878| 2023-04-01| 10996| 0.251| 2023-04-01| 10995| 0.967| 2023-04-01| 10994| 0.635| 2023-04-01| 10993| 0.205| 2023-04-01| 10992| 0.445| 2023-04-01| 10991| 0.804| 2023-04-01| 10990| 0.515| 2023-04-01| 10989| 0.623| 2023-04-01| 10988| 0.440| 2023-04-01| 10987| 0.890| 2023-04-01| 10986| 0.854| ...
5) How to solve it finally …
… or asking: How can I shrink my table?
Option 1: VACUUM FULL
The deleted data must be permanently deleted to free up space for new entries (using VACUUM). However, this does not change the size of the table, as the space is only made available for new entries within the same table. To make the table smaller, it must be shrunk (similar to defragmenting a PC). This can be done using VACUUM FULL. [5]
In this case, VACUUM FULL aborted after 24 hours because the amount of data to be processed was too large.
Option 2: Manual copying of data to a new table
Alternatively, the active data can be copied into a new table „monthly_service_availability_average_new“ using „insert into … select …“. Then the old table will be dropped and the new table renamed to „monthly_service_availability_average“.
The following is important:
- You still need to query the data via the reverse index search.
- Do not copy all the data at once. 1 billion data is too much to hold in memory and query will become slower after a certain time and might even fail. Migrate data in smaller chunks (e.g. 100.000).
The query can look like this:
SELECT *
FROM monthly_service_availability_average
-- define chunk point to start at
WHERE (report_date, service_id ) <= ('2023-03-01',10992)
-- sort data in reverse in index order
ORDER BY report_date DESC NULLS FIRST, service_id DESC NULLS FIRST
LIMIT 100000;
[1] https://devcenter.heroku.com/articles/postgresql-concurrency
[2] https://use-the-index-luke.com/sql/clustering/index-only-scan-covering-index
[3] https://www.cybertec-postgresql.com/en/postgresql-count-made-fast
[4] https://use-the-index-luke.com/sql/sorting-grouping/indexed-order-by
[5] https://www.postgresql.org/docs/current/sql-vacuum.html
Image Credits: all graphics have been self made
| Interested in more information about VACUUM? Here are all the posts: |
