
KI kann alles? Die aktuellen Grenzen von KI und Deep Learning
Künstliche Intelligenz war schon immer ein wesentlicher Bestandteil futuristischer Visionen. Diesen Zukunftsbildern sind wir in den letzten Jahren durch die rasante Entwicklung im Bereich der künstlichen Intelligenz deutlich nähergekommen. Wer hätte schon um die Jahrtausendwende mit selbstfahrenden Autos gerechnet? Gleichzeitig werden die (scheinbar unendlichen) Möglichkeiten von KI, z.B. in den Medien, häufig zu optimistisch oder auch z.T. übertrieben dargestellt. Das sogenannte Deep Learning, eine spezielle mathematische Methode basierend auf neuronalen Netzen, ist ganz maßgeblich für den aktuellen Hype um KI mit verantwortlich. Gleichzeitig hat auch diese Methode seine Grenzen, auf die Gary Marcus in seinem Paper „Deep Learning: A Critical Appraisal“ strukturiert eingeht. Inspiriert von dieser Arbeit soll im Folgenden auf diese Grenzen näher eingegangen werden.
Die Größe der realen Welt und wie begrenzt KI sie sieht
Die Realität ist unglaublich komplex und unglaublich vielfältig. Wir Menschen bewegen uns tagtäglich in dieser Komplexität, die häufig daher rührt, dass wir nicht in fest definierten, abgeschlossenen Systemen leben. Viele Teilaufgaben kann künstliche Intelligenz schon heute besser lösen als wir, aber gleichzeitig sind Menschen immer noch recht gut darin, Information im jeweiligen Kontext zu verarbeiten. Sehen wir nachts eine rot leuchtende Verkehrsampel im Garten eines Freundes, erkennen wir sie als Partybeleuchtung und warten nicht darauf, dass auf grün umschaltet.
Wie sieht künstliche Intelligenz aber die Welt? KI-Algorithmen lernen die Welt durch Datensätze kennen. Betrachten wir zum Beispiel das autonome Fahren. Eine Teilaufgabe besteht für KI hier darin, Schilder korrekt zu erkennen. Hierzu können wir einem KI-Algorithmus Beispielbilder vorlegen. Gleichzeitig würden wir die Schilder auf den Beispielbildern markieren und die korrekte Kategorie benennen („Stoppschild“). Der KI-Algorithmus vergleicht nun ein Bild mit der erwarteten Ausgabe („Stoppschild“) – dies macht er mit allen Beispielbildern und versucht, einen mathematischen Zusammenhang zwischen dem Bild und der Verkehrsschildkategorie zu finden.
Die Welt besteht für einen KI-Algorithmus also hauptsächlich aus den Daten, die ihm vorgelegt werden. Damit unterscheidet sich der KI-Algorithmus natürlich nicht grundlegend von uns Menschen, aber es gibt doch einige Herausforderungen und Grenzen, die ihn doch unterscheidet.
Schierer Datenhunger
Ein kleines Kind, das zum ersten Mal in seinem Leben einen Elefanten sieht, versteht sehr schnell was ein Elefant ist und erkennt danach ein solches Tier auch in anderen Zusammenhängen sehr zuverlässig, z.B. in einem Kinderbuch oder im Fernsehen. Bei Deep-Learning-Algorithmen ist dies nicht der Fall. Dies liegt daran, dass sie solche Zusammenhänge nicht explizit lernen können, sondern diese implizit auf Basis einer großen Anzahl von Beispielen tun. Daher sind sie extrem datenhungrig. Liegen diese großen Datenmengen nicht vor, dann tun sich diese Algorithmen sehr schwer, die Qualität der Modelle bzw. der Vorhersageergebnisse sinkt.
Auch müssen die verarbeiteten Beispieldaten möglichst alle Facetten eines Problems beinhalten. Ein Deep-Learning-Verfahren, dass immer nur mit weißen Schwänen trainiert wurde, ist – im Gegensatz zum Menschen – nicht in der Lage, einen plötzlich auftretenden schwarzen Schwan zu erkennen, wenn dieser vorher nicht in den Trainingsdatensätzen hinterlegt war.

Auch heute können wir die Welt um uns (noch?) nicht abschließend erklären. Doch eine der Stärken der Wissenschaft ist es, auf dem vorhandenen Wissen aufzubauen und in einem iterativen Prozess immer bessere Modelle unserer Welt zu entwerfen. Das Englische Sprichwort „Standing on the shoulders of giants“ beschreibt dies anschaulich: Jede Generation baut auf den Vordenkern vergangener Epochen auf.
Das bedeutet aber auch, dass wir in all unserem Handeln immer auf dieses Vorwissen zugreifen können. Ein Apfel in unserer Hand, den wir loslassen, fällt auf den Boden und steigt nicht an die Decke. Fassen wir eine kalte Wand an, so wird die Wand wärmer und unsere Hand kälter – Energie geht also auf den kälteren Körper über. Das Gegenteil passiert nicht spontan. All das sind Beispiele für allgemeines Vorwissen, das wir stets als Transferwissen verfügbar haben, unabhängig davon, welche speziellen Probleme wir gerade lösen.
Doch Deep Learning-Algorithmen können dieses Transfer- oder Allgemeinwissen nicht nutzen. Sie können nicht auf einem allgemeinen Vorwissen aufbauen, sondern müssen jedes Problem, das sie lösen sollen, von Grund auf neu lernen. Deep-Learning-Algorithmen sind also immer sehr problemspezifisch.
Ein Beispiel in diesem Zusammenhang ist die Bilderkennung. Es gibt schon sehr gute Deep-Learning-Modelle zur Objekterkennung. Diese erkennen sehr zuverlässig, ob auf einem Bild ein Teller Nudeln oder ein Hund dargestellt wird. Eine leichte Abwandlung dieser Problemstellung – z.B. der Algorithmus soll auf Satellitenfotos automatisch Fahrbahnmarkierungen (Zebrastreifen, Pfeile, etc.) erkennen – führt dazu, dass diese Modelle für diese Problemstellung völlig unbrauchbar werden und ein ganzer Forschungszweig gegründet wird, der sich nur mit der Lösung dieses Themas beschäftigt.
Korrelation bedeutet nicht kausaler Zusammenhang
Die Nutzung von Vorwissen ist auch notwendig, um logisch sinnvolle Zusammenhänge von zufälligen Zusammenhängen zu unterscheiden. Ein Beispiel: Die Geburtenrate in westeuropäischen Ländern geht stetig zurück. Gleichzeitig ist die Anzahl brütender Storchenpaare rückläufig. Wollten wir die Geburtenrate erhöhen, müssten wir also einfach Störche besser schützen?
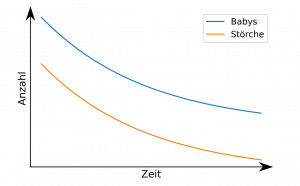
Das ist natürlich ein offensichtlicher Fehlschluss. Nur weil ein mathematischer Zusammenhang historisch existiert, heißt es noch lange nicht, dass die Geburtenrate in einem logischen Zusammenhang mit der Anzahl der Störche steht.
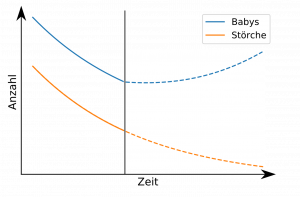
Ein Mensch kann diesen offensichtlichen Fehlschluss erkennen, da er gerade auf seine gesamte Lebenserfahrung und Allgemeinbildung zurückgreifen kann – KI kann das im Allgemeinen nicht. Bei komplizierteren Problemstellungen können auch Menschen nicht mehr zweifelsfrei sagen, ob einem mathematischen Zusammenhang eine reale Abhängigkeit zu Grunde liegt. Hier müssen Wissenschaftler Hypothesen aufstellen, die sie dann immer wieder mit neuen Experimenten versuchen zu widerlegen.
Bedeutet Auswendiglernen wirklich Konzeptverständnis?
Im Begriff „Künstliche Intelligenz“ ist schon der Vergleich mit menschlichen Fähigkeiten angelegt. Diese Vergleiche ziehen sich durch alle Begrifflichkeiten: so „lernt“ zum Beispiel ein Machine-Learning-Modell Zusammenhänge und Ähnlichkeiten aus einem vorgegebenen Datensatz. Nur was genau bedeutet hier „lernen“? Ein Mensch ist in der Lage, mit recht wenigen Daten Konzepte zu lernen.
Zur Illustration dient Abbildung 4: in einem einfachen Computerspiel bewegt sich auf dem Bildschirm ein Ball. Ziel ist es mit dem Ball alle auf dem Bildschirm platzierten Blöcke zu berühren, die bei Berührung verschwinden. Trifft der Ball auf ein Hindernis, so wird er von dort abgestoßen. Es sei denn, er berührt den unteren Bildschirmrand, dann ist das Spiel verloren. Mit Hilfe eines horizontal beweglichen Schlägers lässt sich der Ball indirekt steuern.

Ein Mensch versteht das Spielprinzip nach wenigen Sekunden, auch ohne eine explizite Regeldefinition und hat auch keine Probleme mit einer leichten Abwandlung: zum Beispiel, in dem die vertikale Position des Schlägers leicht verändert wird. Ein Deep-Learning-Modell hat mit solchen Verallgemeinerungen häufig große Probleme und scheitert durch die leichte Veränderung der äußeren Umstände. Das Modell hat nicht wirklich verallgemeinerte Konzepte gelernt („Schläger“, „Ball“, „Wand“) sondern durch endloses Ausprobieren eine erfolgreiche Lösungsstrategie gefunden – die jedoch nicht robust ist gegen kleine Abwandlungen der Systemparameter.
Die vielgefürchtete „black box“
Deep-Learning-Modellen wird häufig nachgesagt, dass sie schwer „erklärbar“ sind und wie eine „black box“ wirken. Man füttert das Modell mit Daten, erhält eine Antwort, aber weiß nicht wirklich, warum das Modell diese Antwort gegeben hat. Das Regelwerk, das zur Entscheidung führt, ist nicht sofort ersichtlich – es ist regelrecht undurchsichtig. Um diese Undurchsichtigkeit von KI zu durchbrechen, ist die „Erklärbarkeit“ von KI-Modellen ein Gegenstand aktueller Forschung. Aber warum ist das überhaupt wichtig? Ganz konkret schränken undurchsichtige KI-Modelle die Anwendbarkeit von KI in den folgenden zwei Beispielen ein:
Vertrauenswürdigkeit: Besonders in regulierten Bereichen, wie zum Beispiel der Medizintechnik oder dem Verkehrswesen, unterliegt jegliche Software besonders hohen gesetzlichen Auflagen. Es soll sichergestellt werden, dass die Software unter allen möglichen Umständen sicher agiert. Das stellt Deep-Learning-Modelle vor große Herausforderungen: Sie lernen hauptsächlich aus den zur Verfügung stehenden Daten. Nehmen wir wieder das Beispiel einer Verkehrsschilderkennung. Es ist undurchsichtig, warum genau das Modell ein Stoppschild als solches erkennt. Die Forschergruppe um Eykholt et al1. zeigte zum Beispiel, wie leicht KI-Modelle sich hier austricksen lassen können. Durch eine leichte Modifikation der Verkehrsschilder, die für Menschen klar als solche erkennbar war, wurden die Schilder nicht mehr als Stoppschild erkannt. Solche Effekte stellen natürlich das Vertrauen in Deep-Learning-Algorithmen für diese Anwendungszwecke in Frage. Die Undurchsichtigkeit von Deep-Learning-Modellen erschwert es, solche unerwünschten Effekte zu bemerken, da sie nicht direkt erkennbar sind.
Sicherheits- und Qualitätsgarantien für modulare Systeme: Im Ingenieursbereich werden komplexe technische Systeme häufig aus vielen kleinen Einzelteilen zusammengesetzt. Ein Auto benötigt einen Motor, Räder, eine Kupplung – für jede dieser Komponenten können in der Entwicklung Sicherheitsgarantien gegeben werden, die es erlauben das Teil in ein größeres Gesamtsystem einzusetzen. Deep-Learning-Modelle können das nicht ohne weiteres. Sie sind extrem abhängig von ihrem ursprünglichen Datensatz. Durch die Undurchsichtigkeit der Modelle ist es sehr schwierig, die Auswirkung veränderter Voraussetzungen auf das Modell abzuschätzen. Dementsprechend ist es nur schwer möglich ein Gesamtsystem modular aus vielen Modellen aufzubauen und verbindliche Qualitäts- und Performancegarantien für das Gesamtsystem abzuleiten.
Wie sieht die Zukunft von KI und Deep Learning aus?
Gary Marcus gibt ein paar Anregungen bezüglich der künftigen Entwicklung von künstlicher Intelligenz und insbesondere von Deep Learning:
- Wiederaufleben anderer KI-Disziplinen: Deep Learning ist ein Teil des Machine Learning, welches wiederum einer ganz gewissen Disziplin der künstlichen Intelligenz angehört. Eine klassische Disziplin der KI ist symbolische Künstliche Intelligenz. Hierdurch können vielleicht Fortschritte im logischen Schließen erzielt werden.
- Zurück zum Studienobjekt Mensch: So kann man besser verstehen und lernen, wie wir lernen und die Welt wahrnehmen. Disziplinen wie die kognitive Psychologie und Entwicklungspsychologie, die versuchen die Funktionsweise des Menschen besser zu verstehen, könnten hier neue Impulse liefern.
- Anspruchsvollere Ziele: Häufig wird versucht, mit Deep Learning eng abgesteckte Probleme zu lösen. Stattdessen steht der Vorschlag im Raum, darüber hinausgehende Herausforderungen aufzustellen – z.B. einen Algorithmus ein beliebiges Video oder einen Text analysieren zu lassen und ihn offene Fragen beantworten lassen: Wer ist die Hauptfigur? Was will sie erreichen? Welche Folgen hätte ihr Erfolg oder Misserfolg?
Fazit: Herausforderungen und Grenzen kennen – Deep Learning richtig nutzen
Manchmal scheint es, als stünde Künstliche Intelligenz kurz davor, die Menschheit in jeglicher Hinsicht zu überflügeln. Es gibt in der Tat einzelne Problemstellungen, in denen dies der KI bereits gelungen ist. Dennoch sind wir von einer Dominanz der KI in allen Lebensbereichen noch ein gutes Stück entfernt. Deep-Learning-Methoden arbeiten besonders gut, wenn sehr viele Daten vorhanden sind und die Problemstellung ganz klar abgegrenzt ist. Aber es gibt auch noch viele Herausforderungen – unter anderem: ein echtes Verständnis abstrakter Konzepte, Transfer von Wissen auf neuartige Anwendungsprobleme, Transparenz und Sicherheitsgarantien, die Unterscheidung zwischen zufälligen und logisch sinnvollen Zusammenhängen. Daher ist ein Bewusstsein über diese Rahmenbedingungen, beim Einsatz von KI Verfahren wie z.B. Deep Learning, sehr wichtig. Die Anregungen von Gary Marcus für die künftige Entwicklung können da wertvolle Impulse liefern.
Co-Autor: Danny Claus
1 Robust Physical-World Attacks on Deep Learning Visual Classification
Diese weiteren Blogbeiträge könnten auch interessant sein:
